本文提供一些關於如何執行 Azure HDInsight 的最常見問題答案。
建立或刪除 HDInsight 叢集
如何? 布建 HDInsight 叢集嗎?
若要檢閱 HDInsight 叢集類型和佈建方法,請參閱使用 Apache Hadoop、Apache Spark、Apache Kafka 等在 HDInsight 中設定叢集。
如何刪除現有的 HDInsight 叢集?
若要深入瞭解何時不再使用時刪除叢集,請參閱 刪除 HDInsight 叢集。
請嘗試在建立和刪除作業之間保留至少 30 到 60 分鐘。 否則,作業可能會失敗,並出現下列錯誤訊息:
Conflict (HTTP Status Code: 409) error when attempting to delete a cluster immediately after creation of a cluster. If you encounter this error, wait until the newly created cluster is in operational state before attempting to delete it.
如何針對工作負載選取正確的核心數目或節點數目?
適當的核心數目和其他設定選項取決於各種因素。
如需詳細資訊,請參閱 HDInsight 叢集的容量規劃。
HDInsight 叢集中的各種節點類型為何?
建立大型 HDInsight 叢集的最佳做法有哪些?
- 建議使用自訂 Ambari DB 設定 HDInsight 叢集,以改善叢集的可擴縮性。
- 使用 Azure Data Lake Storage Gen2 建立 HDInsight 叢集,以利用 Azure Data Lake Storage Gen2 更高的頻寬和其他效能特性。
- 前端節點大小應該要足以容納在這些節點上執行的多個主要服務。
- 有些特定工作負載 (例如 Interactive Query) 也會需要更大的 Zookeeper 節點。 請考慮至少八個核心的 VM。
- 針對 Hive 和 Spark 案例,請使用外部 Hive 中繼存放區。
個別元件
我可以在叢集上安裝更多元件嗎?
是。 若要安裝更多元件或自訂叢集組態,請使用:
建立期間或之後的指令碼。 透過指令碼動作叫用指令碼。 指令碼動作是一種設定選項,可讓您從 Azure 入口網站、HDInsight Windows PowerShell Cmdlet 或 HDInsight .NET SDK 使用。 您可從 Azure 入口網站、HDInsight Windows PowerShell Cmdlet 或 HDInsight .NET SDK 使用此設定選項。
使用 HDInsight 應用程式平台安裝應用程式。
如需支援的元件清單,請參閱可以搭配 HDInsight 使用的 Apache Hadoop 元件和版本有哪些?
我可以升級預安裝於叢集上的個別元件嗎?
如果您升級叢集上預安裝的內建元件或應用程式,則Microsoft不支援產生的設定。 這些系統設定尚未經過Microsoft測試。 嘗試使用不同的 HDInsight 叢集版本,該叢集可能已經預安裝元件的升級版本。
例如,不支援將 Hive 作為個別元件升級。 HDInsight 是受控服務,且許多服務都與 Ambari 伺服器整合並經過測試。 個別升級 Hive 會導致其他元件的索引二進位檔變更,而且會導致叢集發生元件整合問題。
Spark 和 Kafka 可以在相同的 HDInsight 叢集上執行嗎?
不可以,您無法在相同的 HDInsight 叢集上執行 Apache Kafka 和 Apache Spark。 請為 Kafka 和 Spark 建立不同的叢集,以避免發生資源競爭問題。
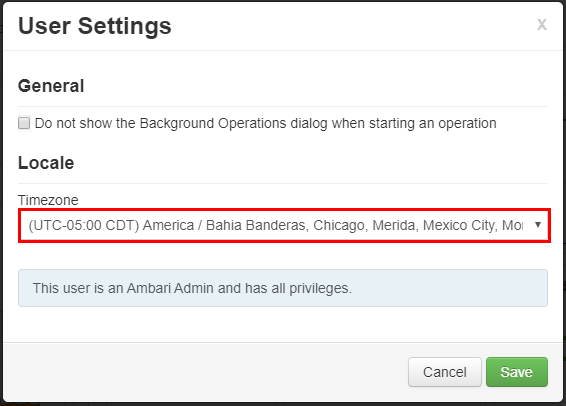
如何變更 Ambari 中的時區?
在
https://CLUSTERNAME.azurehdinsight.net開啟 Ambari Web UI,其中 CLUSTERNAME 是您叢集的名稱。在右上角選取 [系統管理 | 設定]。
在 [用戶設定] 視窗中,從 [時區] 下拉式清單中選取新的時區,然後選取 [儲存]。
Metastore
如何從現有的中繼存放區移轉至 Azure SQL Database?
若要從 SQL Server 移轉至 Azure SQL Database,請參閱教學課程:使用 DMS 以離線方式將 SQL Server 移轉至 Azure SQL Database 中的單一資料庫或集區資料庫。
刪除叢集時,Hive 中繼存放區也會一併刪除嗎?
這取決於叢集設定使用的中繼存放區類型。
預設中繼存放區:預設中繼存放區是叢集生命週期的一部分。 當您刪除叢集時,相應的中繼存放區和中繼資料會一併刪除。
自訂中繼存放區:中繼存放區的生命週期不會與叢集的生命週期繫結。 因此,您可以建立和刪除叢集,而不會遺失中繼資料。 即使在刪除並重新建立 HDInsight 叢集之後,中繼資料 (例如 Hive 結構描述) 仍會保存。
如需詳細資訊,請參閱在 Azure HDInsight 中使用外部中繼資料存放區。
移轉 Hive 中繼存放區也會移轉 Ranger 資料庫的預設原則嗎?
否,原則定義位於 Ranger 資料庫中,因此移轉 Ranger 資料庫會移轉其原則。
是否可以將 Hive 中繼存放區從企業安全性套件 (ESP) 叢集移轉至非 ESP 叢集,反之亦然?
是,您可以將 Hive 中繼存放區從 ESP 移轉至非 ESP 叢集。
如何估計 Hive 中繼存放區資料庫的大小?
Hive 中繼存放區是用來儲存 Hive 伺服器所使用資料來源的中繼資料。 大小需求部分取決於 Hive 資料來源的數目和複雜度。 這些項目無法事先估計。 如 Hive 中繼存放區指導方針中所概述,您可以從 S2 階層開始。 該層提供 50 DTU 和 250 GB 的儲存空間,而若您遭遇瓶頸,請擴大資料庫。
是否支援以 Azure SQL Database 以外的任何其他資料庫作為外部中繼存放區?
否,Microsoft 僅支援使用 Azure SQL Database 作為外部自訂中繼存放區。
我可以在多個叢集之間共用中繼存放區嗎?
是,您可以在多個叢集之間共用自訂中繼存放區,只要這些叢集使用相同的 HDInsight 版本即可。
連線能力與虛擬網路
在網路上封鎖連接埠 22 和 23 有何影響?
如果封鎖連接埠 22 和連接埠 23,您將不會具備叢集的 SSH 存取權。 HDInsight 服務不會使用這些連接埠。
如需詳細資訊,請參閱下列文件:
我可以在與 HDInsight 叢集相同的子網內部署更多虛擬機嗎?
是,您可以在與 HDInsight 叢集相同的子網內部署更多虛擬機。 其支援下列設定:
邊緣節點:您可以將另一個邊緣節點新增至叢集,如在 HDInsight 中的 Apache Hadoop 叢集上使用空白邊緣節點中所述。
獨立節點:您可以將獨立虛擬機器新增至相同的子網路,並使用私人端點
https://<CLUSTERNAME>-int.azurehdinsight.net從該虛擬機器存取叢集。 如需詳細資訊,請參閱控制網路流量。
我應該將資料儲存在邊緣節點的本機磁碟上嗎?
否,將資料儲存在本機磁碟上並不是個好主意。 如果節點失敗,則儲存在本機的所有資料都會遺失。 建議將資料儲存在 Azure Data Lake Storage Gen2 或 Azure Blob 儲存體中,或裝載用來儲存資料的 Azure 檔案儲存體共用。
我可以將現有的 HDInsight 叢集新增至另一個虛擬網路嗎?
否,您無法進行這項操作。 虛擬網路應在佈建時指定。 若在佈建期間未指定任何虛擬網路,則部署會建立無法從外部存取的內部網路。 如需詳細資訊,請參閱將 HDInsight 新增至現有虛擬網路。
安全性和憑證
針對 Azure HDInsight 叢集上的惡意程式碼防護有哪些建議?
如需惡意程式碼防護的資訊,請參閱適用於 Azure 雲端服務和虛擬機器的 Microsoft Antimalware。
如何? 建立 HDInsight ESP 叢集的索引鍵表嗎?
為網域使用者名稱建立 Kerberos 金鑰表。 您稍後可以使用此金鑰表來驗證遠端已加入網域的叢集,而不需要輸入密碼。 網域名稱為大寫:
ktutil
ktutil: addent -password -p <username>@<DOMAIN.COM> -k 1 -e aes256-cts-hmac-sha1-96
Password for <username>@<DOMAIN.COM>: <password>
ktutil: wkt <username>.keytab
ktutil: q
建立 keytab 時,AES256 加密何時需要進行 Salt 處理?
如果您的 TenantName 與 DomainName 不同 (範例 TenantName – bob@CONTOSO.ONMICROSOFT.COM 和 DomainName – bob@CONTOSOMicrosoft.ONMICROSOFT.COM),則您需要使用 -s 選項來新增 SALT 值。
如何判斷適當的 SALT 值?
- 使用互動式 Kerberos 登入來判斷 keytab 的適當 salt 值。 互動式 Kerberos 登入預設會使用最高加密。 應該啟用追蹤來觀察 salt。 以下是 Kerberos 登入範例:
$ KRB5_TRAACE=/dev/stdout kinit <username> -V
- 查看 salt "......." 行的輸出。
- 建立 keytab 時,請使用這個 salt 值。
ktutil
ktutil: addent -password -p <username>@<DOMAIN.COM> -k 1 -e aes256-cts-hmac-sha1-96 -s <SALTvalue>
Password for <username>@<DOMAIN.COM>: <password>
ktutil: wkt <username>.keytab
ktutil: q
我可以使用現有的Microsoft Entra 租使用者來建立具有 ESP 的 HDInsight 叢集嗎?
啟用 Microsoft Entra Domain Services,才能使用 ESP 建立 HDInsight 叢集。 開放原始碼 Hadoop 依賴 Kerberos 進行驗證 (相較於 OAuth)。
若要將 VM 加入網域,您必須擁有網域控制站。 Microsoft Entra Domain Services 是受控網域控制站,並視為 Microsoft Entra ID 的延伸模組。 Microsoft Entra Domain Services 提供所有的 Kerberos 需求,以透過受控方式來建置安全的 Hadoop 叢集。 HDInsight 作為受控的服務,會與 Microsoft Entra Domain Services 整合,以提供安全性。
我是否可以在 Microsoft Entra Domain Services 安全 LDAP 設定中使用自我簽署憑證,並佈建 ESP 叢集?
建議使用憑證授權單位發行的憑證。 但 ESP 也支援使用自我簽署憑證。 如需詳細資訊,請參閱
是否可以將 Data Analytics Studio (DAS) 安裝為 ESP 叢集?
否,ESP 叢集不支援 DAS。
如何提取 Ranger 中顯示的登入活動?
針對稽核需求,Microsoft 建議啟用 Azure 監視器記錄,如使用 Azure 監視器記錄監視 HDInsight 叢集中所述。
我可以在叢集上停用 `Clamscan` 嗎?
Clamscan 是在 HDInsight 叢集上執行的防毒軟體,由 Azure 安全性 (azsecd) 用來保護叢集免受病毒攻擊。 Microsoft 強烈建議使用者避免對預設 Clamscan 設定進行任何變更。
此處理序不會干擾或從其他處理序中移除任何循環。 其一律讓給其他處理序。 只有在系統閒置時,才應該會看到 Clamscan 的 CPU 峰值。
在您必須控制排程的案例中,您可以使用下列步驟:
使用下列命令停用自動執行:
sudo
usr/local/bin/azsecd config -s clamav -d Disabledsudo service azsecd restart新增以根執行下列命令的 Cron 作業:
/usr/local/bin/azsecd manual -s clamav
如需如何設定及執行 Cron 作業的詳細資訊,請參閱 How do I set up a Cron job (如何設定 Cron 作業)?
為什麼 Spark ESP 叢集上的 LLAP 可供使用?
LLAP 是基於安全性理由 (Apache Ranger) 而啟用,而非效能。 請使用較大節點 VM 來配合 LLAP 的資源使用量 (例如至少 D13V2)。
如何在建立 ESP 叢集之後新增其他 Microsoft Entra 群組?
達成此目標的方法有兩種:1 - 您可以在建立叢集時重新建立叢集,以及新增其他群組。 如果您正在 Microsoft Entra Domain Services 中使用限域同步處理,則請確定群組 B 包含在限域同步處理中。
2 - 將群組新增為先前用來建立 ESP 叢集群組的巢狀子群組。 例如,如果已使用群組 A 建立 ESP 叢集,您稍候可以將群組 B 新增為 A 的巢狀子群組,其在約一小時後便會進行同步,並會自動在叢集中提供使用。
儲存體
我可以將 Azure Data Lake Storage Gen2 新增至現有 HDInsight 叢集作為額外的儲存體帳戶嗎?
否,目前無法將 Azure Data Lake Storage Gen2 儲存體帳戶新增至具有 Blob 儲存體作為主要儲存體的叢集。 如需詳細資訊,請參閱比較儲存體選項。
如何尋找 Data Lake 儲存體帳戶目前連結的服務主體?
您可以在 Azure 入口網站中位於叢集屬性下方的 [Data Lake Storage Gen1 存取] 內找到設定。 如需詳細資訊,請參閱驗證叢集設定。
如何計算 HDInsight 叢集的儲存體帳戶和 Blob 容器使用量?
執行下列其中一個動作:
若要尋找 HDInsight 叢集上 /user/hive/.Trash/ 資料夾的大小,請使用下列命令列:
hdfs dfs -du -h /user/hive/.Trash/
如何設定 Blob 儲存體帳戶的稽核?
若要稽核 Blob 儲存體帳戶,請使用在 Azure 入口網站中監視儲存體帳戶內的程序來設定監視。 HDFS-audit 記錄只會提供本機 HDFS 檔案系統 (hdfs://mycluster) 的稽核資訊。 其不包含在遠端存放裝置上已執行的作業。
如何在 Blob 容器與 HDInsight 前端節點之間傳輸檔案?
在前端節點上執行與下列殼層指令碼相似的指令碼:
for i in cat filenames.txt
do
hadoop fs -get $i <local destination>
done
注意
filenames.txt 檔案將具備 Blob 容器中檔案的絕對路徑。
是否有任何適用於儲存體的 Ranger 外掛程式?
目前沒有任何適用於 Blob 儲存體和 Azure Data Lake Storage Gen1 或 Gen2 的 Ranger 外掛程式。 針對 ESP 叢集,建議使用 Azure Data Lake Storage。 您至少可以使用 HDFS 工具在檔案系統層級手動設定精細的權限。 此外,使用 Azure Data Lake Storage 時,ESP 叢集將會在叢集層級使用 Microsoft Entra ID 進行某個檔案系統存取控制。
您可以使用 Azure 儲存體總管,將資料存取原則指派給使用者的安全性群組。 如需詳細資訊,請參閱
我可以在叢集上增加 HDFS 儲存體,而不增加背景工作節點的磁碟大小嗎?
否。 您無法增加任何背景工作節點的磁碟大小。 因此,增加磁碟大小的唯一方式是卸載叢集,然後使用較大的背景工作 VM 重新建立叢集。 請勿使用 HDFS 儲存任何 HDInsight 資料,因為如果您刪除叢集,資料便會遭到刪除。 請改為將資料儲存在 Azure 中。 擴大叢集也可將額外的容量新增至 HDInsight 叢集。
邊緣節點
是否可以在建立叢集之後新增邊緣節點?
如何連線到邊緣節點?
建立邊緣節點之後,您可以在連接埠 22 上使用 SSH 來連線到該節點。 您可以從叢集入口網站找到邊緣節點的名稱。 名稱結尾通常為 -ed。
為什麼在新建立的邊緣節點上不會自動執行保存的指令碼?
您可以使用保存的指令碼自訂透過縮放作業新增至叢集的新背景工作節點。 保存的指令碼不適用於邊緣節點。
REST API
從叢集提取 Tez 查詢檢視的 REST API 呼叫有哪些?
您可以使用下列 REST 端點提取 JSON 格式的必要資訊。 請使用基本驗證標頭來提出要求。
-
Tez Query View: https://<叢集名稱>.azurehdinsight.net/ws/v1/timeline/HIVE_QUERY_ID/ -
Tez Dag View: https://<叢集名稱>.azurehdinsight.net/ws/v1/timeline/TEZ_DAG_ID/
如何使用 Microsoft Entra 使用者以從 HDI 叢集擷取設定詳細資料?
若要與 Microsoft Entra 使用者交涉適當的驗證權杖,請使用下列格式來通過閘道:
- https://
<cluster dnsname>.azurehdinsight.net/api/v1/clusters/testclusterdem/stack_versions/1/repository_versions/1
如何使用 Ambari RESTful 監視 YARN 效能?
如果在相同的虛擬網路或對等互連虛擬網路中呼叫 Curl 命令,則該命令為:
curl -u <cluster login username> -sS -G
http://<headnodehost>:8080/api/v1/clusters/<ClusterName>/services/YARN/components/NODEMANAGER?fields=metrics/cpu
如果從虛擬網路外部或從非對等互連的虛擬網路呼叫命令,則命令格式為:
非 ESP 叢集:
curl -u <cluster login username> -sS -G https://<ClusterName>.azurehdinsight.net/api/v1/clusters/<ClusterName>/services/YARN/components/NODEMANAGER?fields=metrics/cpuESP 叢集:
curl -u <cluster login username>-sS -G https://<ClusterName>.azurehdinsight.net/api/v1/clusters/<ClusterName>/services/YARN/components/NODEMANAGER?fields=metrics/cpu
注意
Curl 會提示您輸入密碼。 您必須輸入叢集登入用戶名稱的有效密碼。
計費
部署 HDInsight 叢集需要多少成本?
如需定價和與計費相關常見問題集的詳細資訊,請參閱 Azure HDInsight 定價頁面。
HDInsight 計費何時開始和停止?
HDInsight 叢集的計費起自叢集建立時,終至叢集刪除時。 計費依每分鐘按比例計費。
如何取消訂閱?
如需如何取消訂閱的資訊,請參閱取消 Azure 訂閱。
針對隨用隨付訂閱,取消訂閱之後會發生什麼事?
如需訂閱取消後的資訊,請參閱取消訂閱之後會發生什麼事?
Hive
即使我執行 HDInsight 3.6 叢集,Hive 版本為何會在 Ambari UI 中顯示為 1.2.1000 而不是 2.1?
雖然 Ambari UI 中只會顯示 1.2,但 HDInsight 3.6 同時包含 Hive 1.2 和 Hive 2.1。
其他常見問題
HDInsight 提供的即時串流處理功能有哪些?
如需串流處理整合功能的資訊,請參閱在 Azure 中選擇串流處理技術。
當叢集閒置一段特定期間時,是否有方法可以動態地終止叢集的前端節點?
您無法使用 HDInsight 叢集來執行此動作。 在這些案例中,您可以使用 Azure Data Factory。
HDInsight 提供哪些合規性供應項目?
如需合規性資訊,請參閱 Microsoft 信任中心。