使用 Data Lake Tools for Visual Studio 執行 Apache Hive 查詢
了解如何使用 Data Lake Tools for Visual Studio 查詢 Apache Hive。 Data Lake Tools 可讓您在 Azure HDInsight 上輕鬆地建立、提交和監視對 Apache Hadoop 的 Hive 查詢。
必要條件
HDInsight 上的 Apache Hadoop 叢集。 如需建立此項目的相關資訊,請參閱使用 Resource Manager 範本在 Azure HDInsight 中建立 Apache Hadoop 叢集。
Visual Studio。 本文中的步驟使用 Visual Studio 2019。
HDInsight tools for Visual Studio 或 Azure Data Lake tools for Visual Studio。 如需安裝和設定工具的相關資訊,請參閱安裝 Data Lake Tools for Visual Studio。
使用 Visual Studio 執行 Apache Hive 查詢
您有兩個選項可建立和執行 Hive 查詢:
- 建立特定查詢。
- 建立 Hive 應用程式。
建立臨機操作 Hive 查詢
臨機操作查詢可以在 Batch 或 [互動式] 模式中執行。
啟動 Visual Studio,然後選取 [不使用程式碼繼續]。
在 [伺服器總管] 中,用滑鼠右鍵按一下 Azure,選取 [連線到 Microsoft Azure 訂閱...],然後完成登入程序。
展開 HDInsight,在您想要執行查詢的叢集上按一下滑鼠右鍵,然後選取 [撰寫 Hive 查詢]。
輸入下列 Hive 查詢:
SELECT * FROM hivesampletable;選取 [執行]。 執行模式預設為 [互動式]。
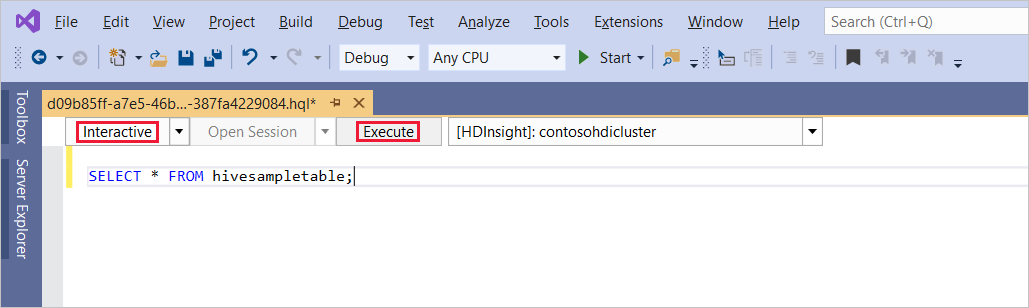
若要在 Batch 模式中執行相同的查詢,請將下拉式清單從 [互動式] 切換為 Batch。 執行按鈕會從 [執行] 變更為 [提交]。

Hive 編輯器支援 Intellisense。 Data Lake Tools for Visual Studio 支援在編輯 Hive 指令碼時載入遠端中繼資料。 例如,如果您輸入
SELECT * FROM,IntelliSense 會列出所有建議的資料表名稱。 若已指定資料表名稱,IntelliSense 會列出資料行名稱。 此工具支援大部分的 Hive DML 陳述式、子查詢及內建 UDF。 IntelliSense 只建議 HDInsight 工具列中已選取的叢集中繼資料。在查詢工具列中 (查詢索引標籤下方和查詢文字上方),選取 [提交],或選取 [提交] 旁的下拉箭號,然後從下拉式清單中選擇 [進階]。 如果您選取後者選項,
如果您選取進階提交選項,請在 [指令碼提交] 對話方塊中設定 [作業名稱]、[引數]、[其他組態] 和 [狀態目錄]。 然後,選取 [提交]。
![[提交指令碼] 對話方塊,HDInsight Hadoop Hive 查詢。](media/apache-hadoop-use-hive-visual-studio/vs-tools-submit-jobs-advanced.png)
建立 Hive 應用程式
若要藉由建立 Hive 應用程式來執行 Hive 查詢,請遵循下列步驟:
開啟 Visual Studio。
在 [開始] 視窗中,選取 [建立新專案]。
在 [建立新專案] 視窗中,於 [搜尋範本] 方塊中,輸入 Hive。 然後選擇 [Hive 應用程式],並選取 [下一步]。
在 [設定新專案] 視窗中,輸入 [專案名稱],選取或建立新專案的 [位置],然後選取 [建立]。
開啟使用此專案所建立的 Script.hql 檔案,並貼入下列 HiveQL 陳述式中:
set hive.execution.engine=tez; DROP TABLE log4jLogs; CREATE EXTERNAL TABLE log4j Logs (t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE LOCATION '/example/data/'; SELECT t4 AS sev, COUNT(*) AS count FROM log4jLogs WHERE t4 = '[ERROR]' AND INPUT__FILE__NAME LIKE '%.log' GROUP BY t4;這些陳述式會執行下列動作:
DROP TABLE:刪除資料表 (若存在)。CREATE EXTERNAL TABLE在 Hive 中建立新的「外部」資料表。 外部資料表只會將資料表定義儲存在 Hive 中。 (資料會保留在來源位置。)注意
當您預期基礎資料應該由外部來源 (例如 MapReduce 作業或 Azure 服務) 更新時,應該使用外部資料表。
捨棄外部資料表並 不會 刪除資料,只會刪除資料表定義。
ROW FORMAT:告訴 Hive 如何格式化資料。 在此情況下,每個記錄中的欄位會以空格隔開。STORED AS TEXTFILE LOCATION:將資料的儲存位置告訴 Hive (example/data 目錄),且資料儲存為文字。SELECT:選擇其資料行t4包含值[ERROR]的所有資料列計數。 此陳述式會傳回值3,因為有三個資料列包含此值。INPUT__FILE__NAME LIKE '%.log':告訴 Hive 只從以 .log 結尾的檔案中傳回資料。 這個子句會將搜尋限制為包含資料的 sample.log 檔案。
從查詢檔案工具列 (其具有類似臨機操作查詢工具列的外觀),選取您想要用於此查詢的 HDInsight 叢集。 然後視需要將 [互動式] 變更為 Batch,並選取 [提交] 以 Hive 作業形式執行陳述式。
[Hive 工作摘要] 將會出現並顯示執行中工作的相關資訊。 使用 [重新整理] 連結來重新整理工作資訊,直到 [工作狀態] 變更為 [已完成] 為止。
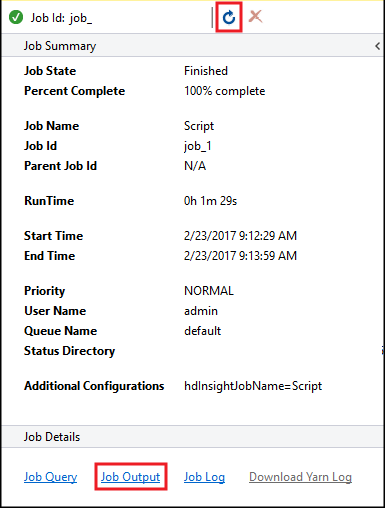
選取 [工作輸出] 以檢視此工作的輸出。 它會顯示
[ERROR] 3,這是此查詢所傳回的值。
其他範例
下列範例依賴於log4jLogs上一個程序中建立的資料表:建立 Hive 應用程式。
從 [伺服器總管] 中,以滑鼠右鍵按一下您的叢集,然後選取 [撰寫 Hive 查詢]。
輸入下列 Hive 查詢:
set hive.execution.engine=tez; CREATE TABLE IF NOT EXISTS errorLogs (t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) STORED AS ORC; INSERT OVERWRITE TABLE errorLogs SELECT t1, t2, t3, t4, t5, t6, t7 FROM log4jLogs WHERE t4 = '[ERROR]' AND INPUT__FILE__NAME LIKE '%.log';這些陳述式會執行下列動作:
CREATE TABLE IF NOT EXISTS:建立資料表 (如果不存在)。 因為未使用EXTERNAL關鍵字,這個陳述式會建立內部資料表。 內部資料表儲存在 Hive 資料倉儲中,並受到 Hive 所管理。注意
與
EXTERNAL資料表不同之處在於,捨棄內部資料表也會刪除基礎資料。STORED AS ORC:以最佳化資料列單欄式 (ORC) 格式儲存資料。 ORC 是高度最佳化且有效率的 Hive 資料儲存格式。INSERT OVERWRITE ... SELECT︰從含有[ERROR]的log4jLogs資料表選取資料列,然後將資料插入errorLogs資料表。
視需要將 [互動式] 變更為 Batch,然後選取 [提交]。
若要驗證作業已建立資料表,請移至 [伺服器總管] 並展開 [Azure] > [HDInsight]。 展開您的 HDInsight 叢集,然後展開 [Hive 資料庫] > [預設]。 會列出 errorLogs 資料表和 Log4jLogs 資料表。
下一步
如您所見,HDInsight tools for Visual Studio 提供簡單的方法,可在 HDInsight 上使用 Hive 查詢。
如需 HDInsight 中 Hive 的一般資訊,請參閱什麼是 Apache Hive 和 Azure HDInsight 上的 HiveQL?
如需在 HDInsight 上使用 Hadoop 的其他方式的相關資訊,請參閱在 HDInsight 上的 Apache Hadoop 中使用 MapReduce
如需 HDInsight tools for Visual Studio 的詳細資訊,請參閱使用 Data Lake Tools for Visual Studio 連線到 Azure HDInsight 並執行 Apache Hive 查詢