多網站和多區域同盟
許多複雜的解決方案需要相同的事件串流可在多個位置中取用,或者它們需要在多個位置中收集事件串流,然後合併至特定的位置以供取用。 通常,也需要擴充或減少事件串流或進行事件格式轉換,也會在單一區域和解決方案內進行。
實際上,這表示您的解決方案會維護多個事件中樞,通常位於不同的區域和事件中樞命名空間,然後在其間複寫事件。 您也可以與來源和目標 (例如 Azure 服務匯流排、Azure IoT 中樞或 Apache Kafka) 交換事件。
在不同區域中維護多個作用中的事件中樞也可讓用戶端在其內容進行合併時,選擇並在它們之間切換,如此可讓整體系統在針對區域性可用性問題更具復原性。
「同盟」一章說明同盟模式,以及如何使用無伺服器 Azure 串流分析或 Azure Functions 執行階段來實現這些模式,並選擇在事件流程路徑中直接使用您自己的轉換或擴充程式碼。
同盟模式
有許多為何您想要在不同事件中樞或其他來源與目標之間移動事件的潛在動機,而且我們列舉本節中最重要的模式,並同時連結至個別模式的更詳細指引。
針對區域可用性事件的復原能力
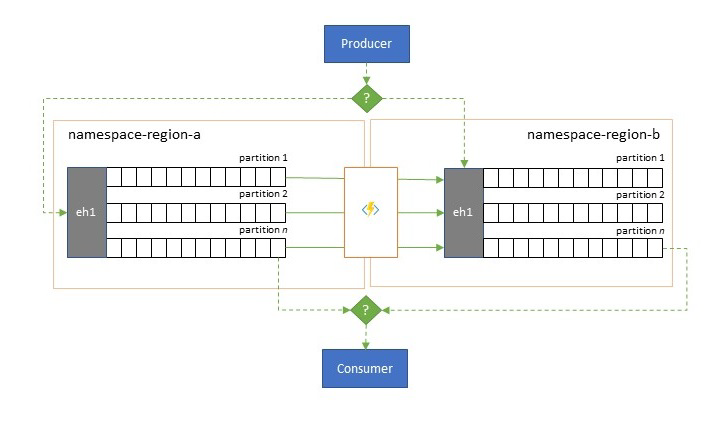
儘管最高可用性和可靠性是事件中樞的首要操作優先順序,但仍有許多方式可能會阻止生產者或取用者由於網路或名稱解析問題而無法與指派的「主要」事件中樞交談,或事件中樞可能真的暫時沒有回應或傳回錯誤。
這類情況並不是「災難」,以致您會想要完全放棄區域部署,就像您可能在災害復原情況下所做的一樣,但是某些應用程式的商務案例可能已受到持續不超過幾分鐘或甚至幾秒鐘的可用性事件所影響。
有兩種基本模式可處理這類案例:
- 複寫模式是關於將主要事件中樞的內容複寫至次要事件中樞,其中主要事件中樞通常由應用程式用於產生和取用事件,而次要事件中樞則是在主要事件中樞變成無法使用的情況下充當後援選項。 由於複寫是單向 (從主要到次要),因此將生產者和取用者從無法使用的主要事件中樞切換成次要事件中樞時,會導致舊的主要事件中樞不再收到新的事件,因此其不再是最新的。 因此,純複寫僅適用於單向容錯移轉案例。 一旦執行了容錯移轉,就會放棄舊的主要事件中樞,而且必須在不同的目標區域中建立新的次要事件中樞。
- 合併模式會連續合併兩個以上事件中樞的內容來擴充複寫模式。 原先生產至配置中所含其中一個事件中樞的每個事件,都會複寫到其他事件中樞。 複寫事件時,會標註它們,如此複寫目標的複寫流程後續會忽略它們。 使用合併模式的結果是兩個以上的事件中樞,其中將以最終一致的方式包含相同的事件集。
無論是哪一種情況,事件中樞的內容都不會相同。 來自任何一個生產者並依相同分割區索引鍵分組的事件,會以原先提交的同一相對順序出現,但事件的絕對順序可能不同。 這尤其適用於下列案例:來源和目標事件中樞的分割區計數不同,這是這裡所述數個擴充模式想要得到的結果。 分割器或路由器可能會取得大型事件中樞 (具有數百個分割區) 的切片,並輸送至只有少數分割區的小型事件中樞,這更適合處理含有限處理資源的子集。 相反地,彙總可能會將數個小型事件中樞的資料輸送至單一大型事件中樞 (具有更多分割區),以處理合併的輸送量和處理需求。
將事件保持在一起的準則是分割區索引鍵,而不是原始分割區識別碼。 關於相對順序的進一步考量,以及如何在不依賴相同範圍的串流位移的情況下,從某個事件中樞執行容錯移轉至下一個事件中樞,會在複寫模式描述中討論。
指導方針:
延遲最佳化
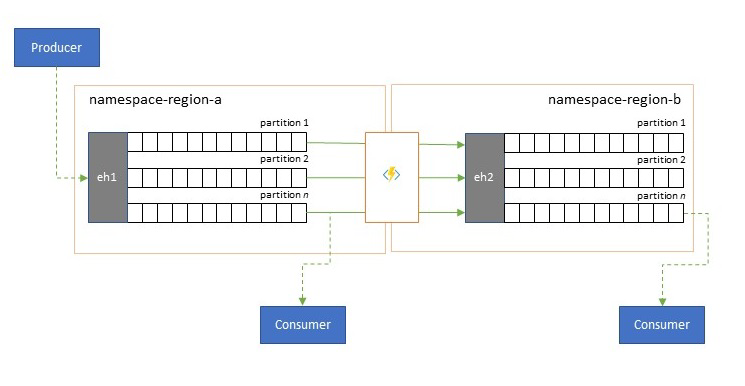
事件串流是由生產者寫入一次,但事件取用者可能不限次數讀取這些事件串流。 對於下列案例:區域中的事件串流由多個取用者共用,並需要在位於不同區域的分析處理期間重複存取,或整個要求將使並行取用者資源匱乏,將事件串流的複本置於分析處理器附近,以減少往返延遲,可能是有益的。
應該偏好複寫而不是跨區域從遠端取用事件的好範例,特別是區域相距極遠的範例 (例如,歐洲和澳大利亞在地理位置上幾乎是天南地北),而且對於任何來回行程,網路延遲很輕易就超過 250 毫秒。 您無法加速光的速度,但是可以減少與資料互動的高延遲來回行程次數。
指導方針:
驗證、減少和擴充
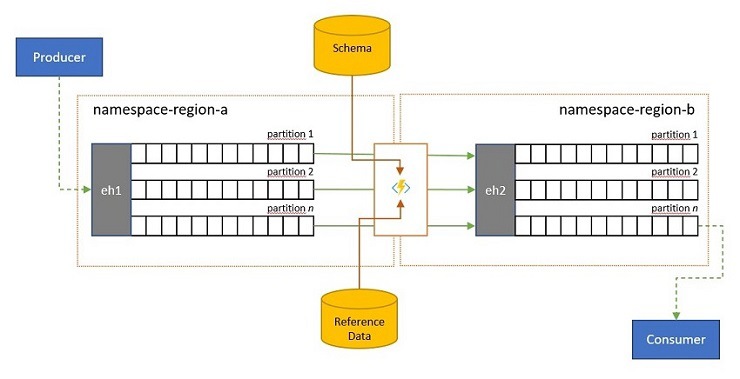
事件串流可能是由您自己解決方案外部的用戶端提交至事件中樞。 這類事件串流可能需要檢查外部提交的事件是否符合給定的結構描述,以及是否有要卸除的不符合規範事件。
在用戶端受到極大帶寬限制的案例中,例如在許多具有計量頻寬的「物聯網」,或者事件最初透過封包大小受到限制的非 IP 網路傳送,可能必須使用參考資料來擴充事件,以新增可供下游事件處理器使用的進一步內容。
在其他情況下,特別是當串流合併時,事件資料可能必須藉由省略一些詳細資料來降低複雜度或純大小。
其中任一項作業都可能會在複寫、彙總或合併流程中發生。
指導方針:
與分析服務整合
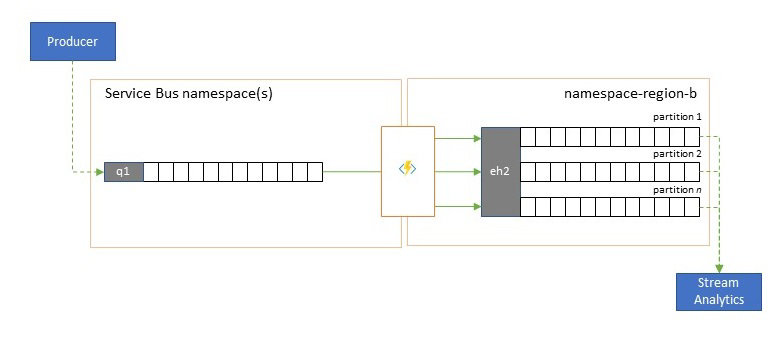
數個 Azure 雲端原生分析服務 (例如 Azure 串流分析或 Azure Synapse) 最適合使用從 Azure 事件中樞提供的串流或預先批次資料,而且 Azure 事件中樞也會啟用與數個開放原始碼分析套件 (例如 Apache Samza、Apache Flink、Apache Spark 和 Apache Storm) 整合。
如果您的解決方案主要使用服務匯流排或事件方格,您可以讓這類分析系統輕鬆地存取這些事件,也可以在將它們輸送至事件中樞時,使用事件中樞擷取來加以保存。 事件方格可透過其事件中樞整合以原生方式執行此動作。對於服務匯流排,您遵循服務匯流排複寫指引。
Azure 串流分析會直接與事件中樞整合。
指導方針:
事件串流的彙總和正規化
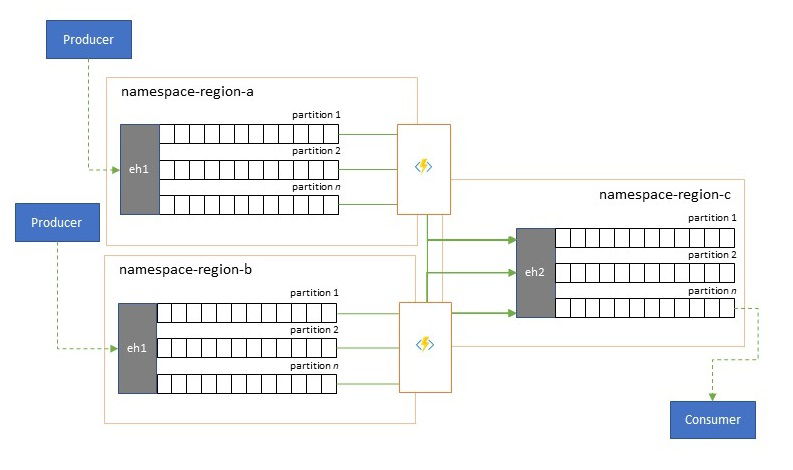
全域解決方案通常是由大多獨立的區域性使用量所組成,包括擁有自己的分析功能,但超區域和全域分析透視將需要整合的透視,這就是為什麼要集中彙總在個別區域性使用量中評估的相同事件串流,以取得本機透視。
正規化是彙總案例的變體,其中有兩個以上的傳入事件串流會攜帶相同類型的事件 (但具有不同的結構或不同的編碼),以及最需轉碼或轉換後才能使用的事件。
正規化也可能包含加密工作,例如解密端對端加密的承載,以及針對下游取用者對象使用不同的金鑰和演算法將其重新加密。
指導方針:
事件串流的分割和路由
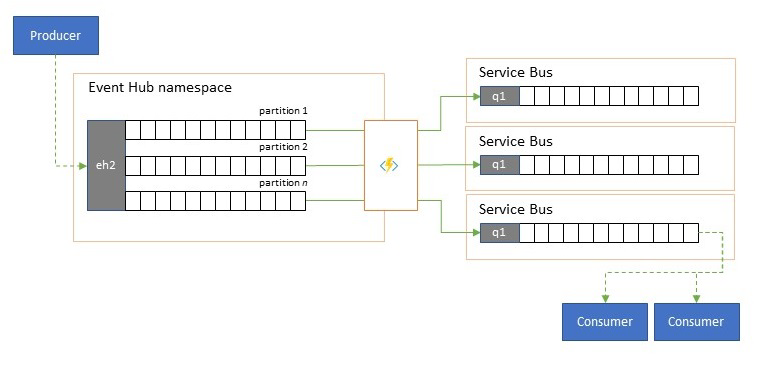
Azure 事件中樞偶爾會在「發佈-訂閱」樣式案例中使用,其中如洪流般傳入的內嵌事件遠超過 Azure 服務匯流排或 Azure 事件方格的容量,這兩者都有原生發佈-訂閱篩選和散發功能,而且是此模式所偏好的。
儘管真正的「發佈-訂閱」功能會將其保留給訂閱者,來挑選他們想要的事件,但是分割模式則會讓生產者依預先決定的散發模型將事件對應至分割區,然後指定的取用者會以獨佔方式從「其」分割區提取。 當事件中樞緩衝處理整體流量時,特定分割區的內容 (代表原始輸送量的一部分) 接著可能會複寫到佇列,用於可靠、交易式、競爭性的取用者取用。
在許多案例中,事件中樞主要用於在區域內的應用程式內移動事件,因此在某些情況下,可能僅來自單一分割區的選取事件也必須在其他位置可用。 此案例類似於分割案例,但可能會使用可擴充的路由器,考慮所有抵達事件中樞的訊息,並揀選幾個來進行向外路由,而且可能會依事件中繼資料或內容來區分路由目標。
指導方針:
記錄投影
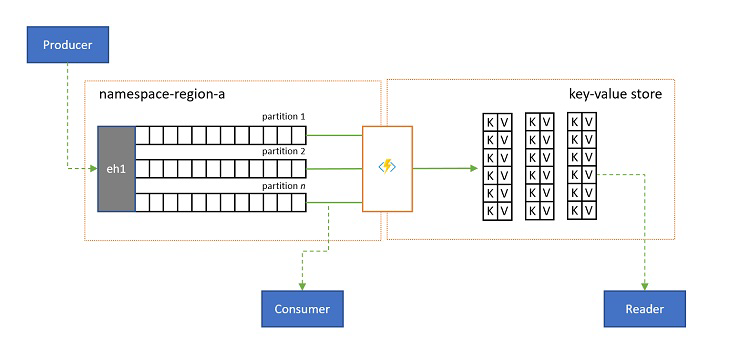
在某些案例中,您會想要有權存取任何事件子串流所傳送的最新值,而且通常會依分割區索引鍵加以區分。 在 Apache Kafka 中,這通常是藉由啟用主題的「記錄壓縮」來實現,從而捨棄所有事件,只留下以任何唯一索引鍵標記的最新事件。 記錄壓縮方法有三個複合缺點:
- 壓縮需要連續重組記錄,但對於為了僅限附加工作負載而最佳化的訊息代理程式來說,這是一項過於昂貴的作業。
- 壓縮具有破壞性,而且不允許對相同串流進行壓縮和未壓縮透視。
- 壓縮的串流仍具有循序存取模型,這表示在記錄中尋找所需的值,需要在最糟的情況下讀取整個記錄,在此情況下,通常會導致最佳化,以實作此處所呈現的確切模式:將記錄內容投影至資料庫或快取。
最後,壓縮的記錄是索引鍵-值存放區,因此,對於這類存放區,其可能是最糟的實作選項。 對於查閱和查詢來說,建立和使用適當索引鍵-值存放區或其他資料庫的永久記錄投影,其效率要高得多。
由於事件是不可變的,且順序一律會保留在記錄中,因此索引鍵-值存放區的任何記錄投射對於相同範圍的事件一律相同,這表示您持續更新的投影一律會提供授權檢視,而且一旦建置,就沒有任何好理由從日誌內容重建投影。
指導方針:
複寫應用程式技術
針對您想要設定和執行的複寫工作,實作上述模式需要可調整且可靠的執行環境。 在 Azure 上,最適合這類工作 (即無狀態工作) 的執行階段環境是 Azure 串流分析 (若是具狀態串流複寫工作),以及 Azure Functions (若是無狀態複寫工作)。
Azure 串流分析中的具狀態複寫應用程式
對於需要考慮事件之間關聯性、建立複合事件、擴充事件或減少事件、建立資料彙總,以及轉換事件裝載的具狀態複寫應用程式,Azure 串流分析是最佳實作選項。
在 Azure 串流分析中,您可以建立作業,整合輸入和輸出,並透過查詢產生接著可在輸出上使用的結果來整合輸入中的資料。
查詢是 SQL 查詢語言為基礎,而且可在一段時間內輕鬆地篩選、排序、彙總和聯結串流處理資料。 您也可以使用 JavaScript 和 C# 使用者定義函數 (UDF) 來擴充此 SQL 語言。 透過簡單的語言建構和/或設定執行彙總作業時,您可以輕鬆調整事件排序選項和時間範圍的持續長度。
每個作業都具有所轉換資料的一或多個輸出,並可控制所要採取的動作以回應您所分析的資訊。 例如,您可以:
- 將資料傳送至服務如 Azure Functions、服務匯流排主題或佇列,以觸發通訊或自訂工作流程下游。
- 將資料傳送至 Power BI 儀表板以即時顯示在儀表板上。
- 將資料儲存至其他 Azure 儲存體服務 (例如 Azure Data Lake、Azure Synapse Analytics 等等),以便根據歷程記錄資料的超大型索引集區執行批次分析或定型機器學習服務模型。
- 在資料庫 (SQL Database、Azure Cosmos DB) 中,儲存投影 (亦稱為「具體化檢視」)。
Azure Functions 中的無狀態複寫應用程式
針對無狀態複寫工作,您若想要在不考慮其承載的情況下轉送事件,或單獨處理它們,而不必考慮事件的關聯性 (除了其相對順序外),您可以使用 Azure Functions,其會提供極大的彈性。
Azure Functions 具有預建、可調整的觸發程序和輸出繫結 (適用於 Azure 事件中樞、Azure IoT 中樞、Azure 服務匯流排、Azure 事件方格,以及 Azure 佇列儲存體),以及適用於 RabbitMQ 和 Apache Kafka 的自訂延伸模組。 大部分的觸發程序會根據記載的計量,將同時執行的執行個體數目擴增或縮減,以動態方式適應輸送量需求。
針對建置記錄投影,Azure Functions 支援 Azure Cosmos DB 和 Azure 表格儲存體的輸出繫結。
Azure Functions 可在 Azure 受控識別下執行,而且藉此其可以在 Azure Key Vault 內的緊密存取控制儲存體中保留認證的設定值。
Azure Functions 還可讓複寫工作直接與 Azure 虛擬網路和所有 Azure 傳訊服務的服務端點整合,而且可以隨時與 Azure 監視器整合。
使用 Azure Functions 取用方案,預建的觸發程序甚至可以在沒有任何訊息可供複寫時縮減至零,這表示您無須支付任何成本,即可將設定保持備妥狀態,以再次擴增;使用取用方案的主要缺點是,從這個狀態「喚醒」複寫工作時的延遲明顯高於基礎結構保持執行中狀態的裝載方案。
相較之下,傳訊和事件的最常見複寫引擎 (例如 Apache Kafka 的 MirrorMaker) 會要求您提供裝載環境,並自行調整複寫引擎。 這包括設定和整合安全性和網路功能,以及協助監視資料的流程,然後您仍然沒有機會將自訂複寫工作插入流程中。
在 Azure Functions 與 Azure 串流分析之間進行選擇
當您需要在複寫事件時處理其承載時,Azure 串流分析 (ASA) 是最佳選項。 ASA 可以逐一複製事件,也可以建立彙總來壓縮事件串流的資訊,然後再將其轉送。 其可以立即依賴補充參考資料 (保留在 Azure Blob 儲存體或 Azure SQL Database 中),而不需要將這類資料匯入資料流程中。
使用 ASA,您可以輕鬆地在超大規模資料庫中建立串流的持續性和具體化檢視。 對於 Apache Kafka 笨重的「日誌壓縮」模型和 Kafka Streams 的易變用戶端資料表投影來說,這是一種相當優越的方法。
ASA 可以立即處理具有以 CSV、JSON 和 Apache Avro 格式所編碼承載的事件,而且您可以插入任何其他格式的自訂還原序列化程式。
對於您想要「依原狀」複製事件串流,且不需要觸及承載的所有複寫工作,或者,如果您需要實作路由器、執行密碼編譯工作、變更承載的編碼,或如果需要完全控制資料串流內容,Azure Functions 是最佳選項。
後續步驟
在本文中,我們探索了一系列的同盟模式,並說明了 Azure Functions 在 Azure 中作為事件和傳訊複寫執行階段的角色。
接下來,您可能會想要攻讀如何使用 Azure 串流分析或 Azure Functions 來設定複寫器應用程式,然後如何在事件中樞與其他各種事件和傳訊系統之間複寫事件流程: