將轉換最佳化
使用下列策略最佳化 Azure Data Factory 和 Azure Synapse Analytics 管線中對應資料流程的轉換效能。
最佳化聯結、存在和查閱
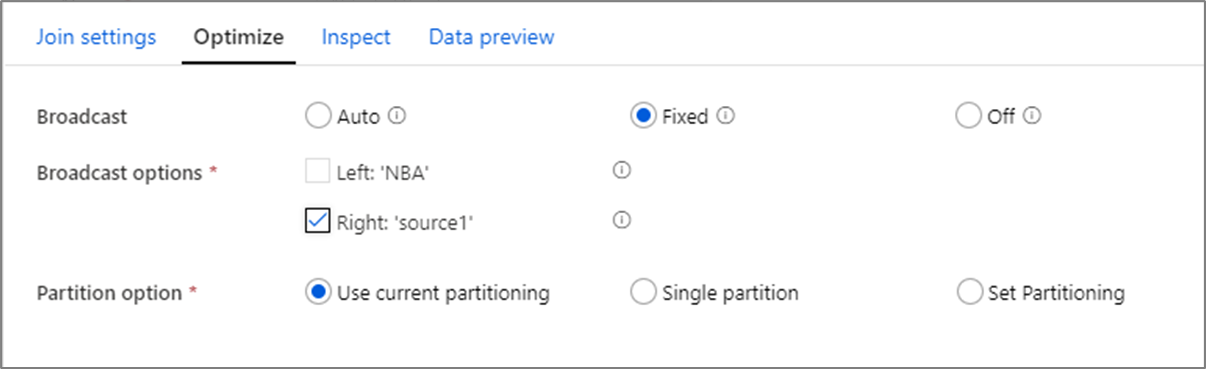
廣播
在聯結、查閱和存在轉換中,如果其中一個或兩個資料流小到能納入背景工作角色節點記憶體中,您可以藉由啟用 [廣播] 來最佳化效能。 廣播是當您將小型資料框架傳送至叢集中的所有節點時。 這可讓 Spark 引擎執行聯結,而不需重新緩衝處理大型資料流程中的資料。 根據預設,Spark 引擎會自動決定是否要廣播聯結的一邊。 如果您對於傳入的資料很熟悉,知道其中一個資料流會小於另一個資料流,則可以選取 [固定廣播]。 已修正廣播會強制 Spark 廣播選取的資料流程。
如果廣播資料的大小對 Spark 節點而言太大,您可能會收到記憶體不足錯誤。 若要避免記憶體不足錯誤,請使用記憶體最佳化叢集。 如果您在資料流程執行期間遇到廣播逾時,可以關閉廣播最佳化。 不過,這會導致資料流程的執行速度變慢。
使用可能需要較長時間才能查詢的資料來源 (例如大型資料庫查詢) 時,建議您關閉聯結的廣播。 當叢集嘗試廣播至計算節點時,具有較長查詢時間的來源可能會導致 Spark 逾時。 選擇關閉廣播的另一個好時機,是當您的資料流程中有資料流程,匯總值以供稍後用於查閱轉換時。 此模式可能會混淆 Spark 最佳化器並造成逾時。
交叉聯結
如果您在聯結條件中使用常值,或在聯結的兩端有多個相符項目,Spark 會以交叉聯結的形式執行聯結。 交叉聯結是完整的笛卡兒乘積,然後篩選出聯結的值。 這比其他聯結類型慢。 請確定您在聯結條件的兩端都有資料行參考,以避免造成效能影響。
在聯結前排序
不同於 SSIS 之類工具中的合併聯結,聯結轉換不是必要的合併聯結作業。 聯結索引鍵不需要在轉換之前進行排序。 不建議在對應資料流程中使用排序轉換。
視窗轉換效能
對應資料流程中的視窗轉換會依您在轉換設定中選取作為 over() 子句一部分資料行中的值分割資料。 在視窗轉換中會公開許多熱門的彙總和分析函數。 不過,如果使用案例是針對排名 rank() 或資料列編號 rowNumber() 產生整個資料集上的視窗,建議您改用排名轉換和 Surrogate 索引鍵轉換。 這些轉換會使用那些函式,再次執行更完善的完整資料集作業。
重新分割扭曲的資料
某些轉換,例如聯結和匯總會重新換用您的資料分割區,有時可能導致扭曲的資料。 扭曲的資料表示資料不會平均分散到分割區。 高度扭曲的資料可能導致下游轉換和接收寫入速度變慢。 您可以按一下監視顯示中的轉換,在資料流程執行的任何時間點檢查扭曲資料。
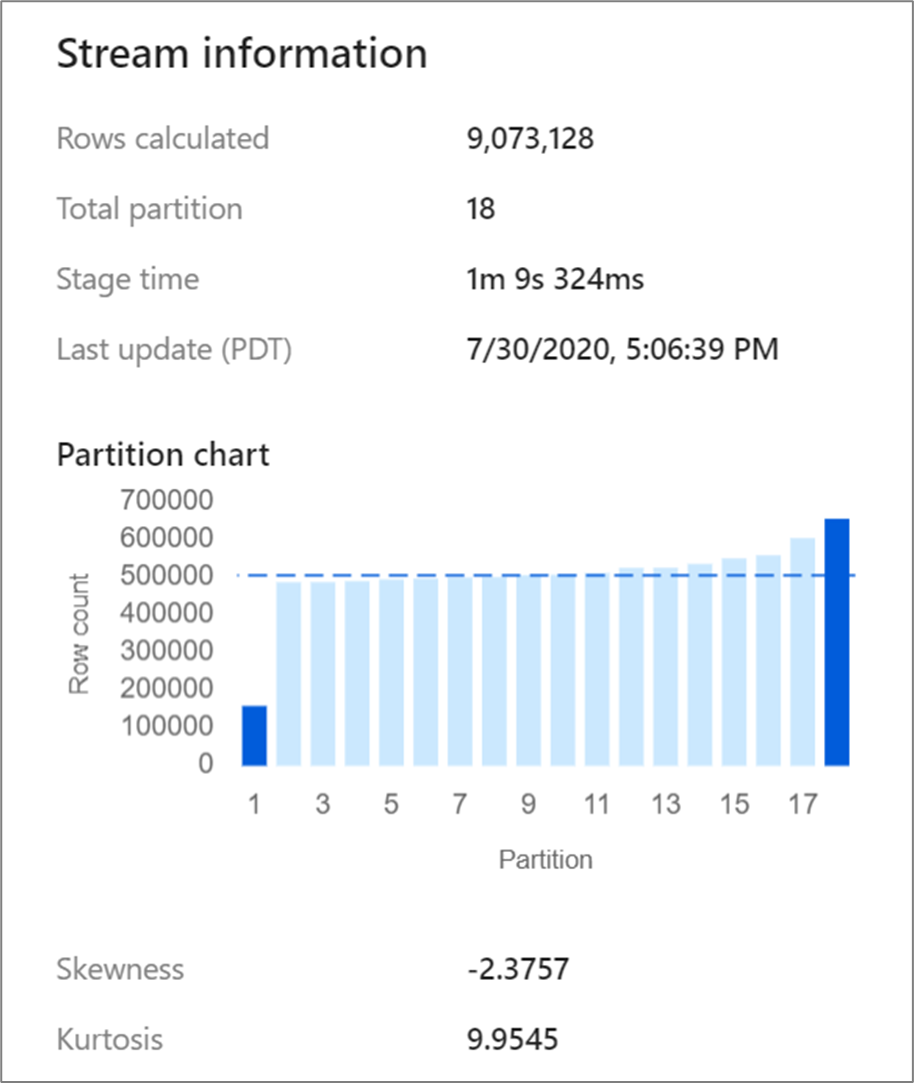
監視顯示會顯示資料如何分散到每個分割區,以及兩個計量:扭曲和峰態。 扭曲是非對稱資料的量值,而且可以有正值、零、負值或未定義值。 負扭曲誤差表示左尾比右尾長。 峰態是資料為粗尾或淺尾的量值。 高峰態值為不理想。 理想的扭曲範圍介於 -3 到 3 之間,而峰態範圍小於 10。 解譯這些數字的簡單方式是查看資料分割圖表,並查看是否有 1 個橫條大於其餘橫條。
如果資料在轉換之後未平均分割,可以使用最佳化索引標籤來重新分割。 重新緩衝資料需要一段時間,而且可能無法改善資料流程效能。
提示
如果您重新分割資料,但具有可重新換行資料的下游轉換,請在做為聯結索引鍵的資料行上使用雜湊分割。
注意
資料流程內的轉換 (接收轉換除外) 不會修改待用資料的檔案和資料夾分割。 每次轉換時的分割,都會重新分割 ADF 為了執行您的每個資料流程而管理之暫存無伺服器 Spark 叢集的資料框架中包含的資料。
相關內容
請參閱其他與效能相關的資料流程文章: