Azure 監視器計量彙總與顯示的說明
本文說明時間序列資料庫中支援 Azure 監視器平台計量和自訂計量的計量彙總。 本文也適用於標準 Application Insights 計量。
本文中的資訊很複雜,提供給想要深入了解計量系統的人員。 您不需要了解才能有效地使用 Azure 監視器計量。
概觀和字詞
將計量新增至圖表時,計量瀏覽器會自動預先選取預設彙總。 預設在基本情節下可行,但您可以使用不同的彙總來深入解析計量。 檢視圖表上的各種彙總之前,您必須了解計量總管如何處理彙總。
讓我們先清楚定義幾個字詞:
- 計量值 - 針對特定資源收集的單一量值。
- 時間序列資料庫 - 此資料庫最適合儲存和擷取完全包含值和相應時間戳記的資料點。
- 時間週期 - 一段普通時間。
- 時間間隔 - 收集兩個計量值之間的一段時間。
- 時間範圍 - 圖表上顯示的時間週期。 通常預設為 24 小時。 只有特定範圍可用。
- 時間細微性或時間精細度 - 據以將值彙總起來顯示在圖表上的時間週期。 只有特定範圍可用。 目前最短 1 分鐘。 時間細微性值必須小於選取的時間範圍才有用,否則整個圖表只顯示一個值。
- 彙總類型 - 從多個計量值計算的一種統計資料。
- 彙總 - 取得多個輸入值,然後透過彙總類型所定義的規則來產生單一輸出值的過程。 例如,取得多個值的平均值。
流程摘要
計量是一系列以時間戳記儲存的值。 在 Azure 中,大部分計量都儲存在 Azure 計量時間序列資料庫中。 繪製圖表時會從資料庫擷取所選計量的值,然後根據選擇的時間細微性 (又稱為時間精細度) 分開彙總。 您使用計量瀏覽器的時間選擇器,以選取時間細微性的大小。 因為會根據目前選取的時間範圍,自動選取時間細微性,您不需要明確選取。 選取之後,每個時間細微性間隔期間擷取的計量值就彙總並畫在圖表上 - 每個間隔一個資料點。
彙總類型
計量總管中有五種可用的基本彙總類型。 計量瀏覽器會隱藏無關且無法用於給定計量的彙總。
- 總和:彙總間隔期間擷取的所有值的總和。 有時稱為總計彙總。
- 計數:彙總間隔期間擷取的量值數目。 計數不考慮量值的值,只關注記錄數目。
- 平均值:彙總間隔期間擷取的計量值的平均值。 就大部分計量而言,此值等於「總和/計數」。
- 最小值 - 彙總間隔期間擷取的最小值。
- 最大值 - 彙總間隔期間擷取的最大值。
例如,假設圖表使用總和彙總,顯示 VM 在過去 24 小時時間範圍內的網路輸出總計計量。 從圖表右上角可以變更時間範圍和細微性,如下列螢幕擷取畫面所示。
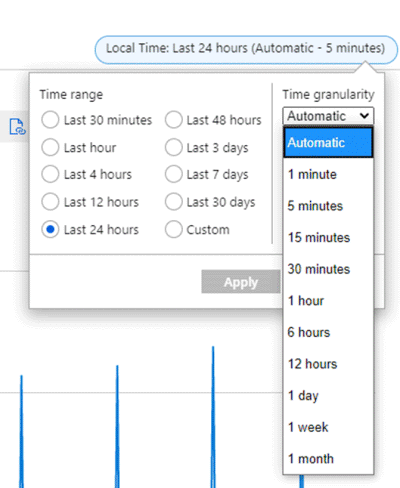
假設時間細微性 = 30 分鐘,時間範圍 = 24 小時:
- 圖表繪製 48 個資料點。 亦即 24 小時 x 每小時 2 個資料點 (60 分鐘/30 分鐘),彙總 1 分鐘資料點。
- 折線圖在圖表繪圖區連接 48 個點。
- 每個資料點代表每個相關 30 分鐘時間週期送出的所有網路輸出位元組的總和。

按一下本節中的影像以放大顯示。
如果將時間細微性切換為 15 分鐘,圖表將繪製 96 個彙總資料點。 亦即,60 分鐘/15 分鐘 = 每小時 4 個資料點 x 24 小時。

如果時間細微性為 5 分鐘,則會有 24 x (60/5) = 288 個點。
如果時間細微性為 1 分鐘 (圖表上可能的最短時間),則會有 24 x 60/1 = 1440 個點。

這些總和各展現不同的圖表,如先前螢幕擷取畫面所示。 請注意,相較於時間範圍的其餘部分,此 VM 在很短時間週期內有很多輸出。
時間細微性可讓您調整圖表上的「訊號雜訊」比。 較高的彙總可移除雜訊並使尖峰平滑。 請注意底部 1 分鐘圖表的變化,隨著細微性值偏高而平滑。
將此資料傳送至其他系統時 (例如警示),此平滑行為很重要。 CPU 時間在短尖峰內超過 90% 時,您通常不會想要收到警示。 但如果 CPU 停留在 90% 長達 5 分鐘,則可能很重要。 如果您在 CPU (或任何計量) 上設定警示規則,時間細微性越大可減少收到假警示的次數。
請務必規定何謂「正常」,讓工作負載知道最佳時間間隔。 此為動態警示的優點之一,這是另一個主題,超出本文範疇。
系統如何收集計量
資料收集隨計量而有所不同。
注意
下面的範例已簡化以進行說明,而且每個彙總中所含的實際計量資料都會受到評估發生時可用資料的影響。
量值收集頻率
有兩種收集週期。
一般 - 以一致不變的時間間隔來收集計量。
以活動為基礎 - 在特定類型的交易發生時收集計量。 每個交易都有計量項目和時間戳記。 其不會定期進行收集,因此,給定時間週期內的記錄數會不同。
資料粒度
時間細微性最短 1 分鐘,但隨計量而定,基礎系統可能更快擷取資料。 例如,以 15 秒的時間間隔擷取 Azure VM 的 CPU 百分比。 因為 HTTP 失敗視同交易來追蹤,很容易遠超過一分鐘。 其他計量 (例如 SQL 儲存體) 每隔 20 分鐘擷取一次。 此選擇取決於個別資源提供者和類型。 大多盡可能提供最短的時間間隔。
維度、分割和篩選
擷取計量以每個資源為對象。 不過,收集、儲存和能夠繪製的計量可能在不同層級。 此層級由「計量維度」中可用的其他計量所表示。 每個資源提供者會定義收集的資料詳細程度。 Azure 監視器只定義如何呈現和儲存這般詳細資料。
在計量總管中繪製計量時,您可以選擇依維度「分割」圖表。 分割圖表意味著您查看基礎資料以取得更多詳細資料,以及看到已在計量瀏覽器中繪製或篩選該資料。
例如,Microsoft.ApiManagement/service 有 Location 作為許多計量的維度。
容量即為這種計量。 有 Location 維度意味著基礎系統針對每個位置的容量儲存計量記錄,而不只彙總數量的計量記錄。 然後,您可以在計量圖表中擷取或分割該資訊。
以閘道要求的整體持續期間為例,有 Location 和 Hostname 這兩個維度,同樣可讓您知道持續期間的位置及來自哪個主機名稱。
要求是其中一個更有彈性的計量,有 7 個不同的維度。
如需每個計量和可用維度的詳細資訊,請參閱 Azure 監視器支援的計量一文。 此外,每個資源提供者和類型的文件可能提供有關維度及其測量什麼的其他資訊。
分割和篩選可以一起用來深入研究問題。 以下範例圖表顯示資源群組中一群 VM 的「平均磁碟寫入位元組」。 我們以此計量彙總所有 VM,但想要深入了解是哪些 VM 大約在早上 6 點造成尖峰。 是否為同一個機器? 有多少個機器涉入?

按一下本節中的影像以放大顯示。
套用分割時可以看到基礎資料,但有點雜亂。 結果,有 20 個 VM 彙總到上圖。 在此例子中,我們將滑鼠停留在早上 6 點的大尖峰上,發現是 CH-DCVM11 造成。 但是,因為其他 VM 造成圖表雜亂,所以很難看出與該 VM 相關聯的其餘資料。

使用篩選可讓我們將圖表清理整齊,看到實際情況。 您可以核取或取消核取想看的 VM。 請注意點線。 稍後一節會談到這些線條。

如需如何在計量總管圖表上顯示分割維度資料的詳細資訊,請參閱計量總管的進階功能 - 篩選和分割。
NULL 和零值
如果系統等待資源的計量資料但未收到,則會記錄 NULL 值。 NULL 不同於零值,在計算彙總和繪製圖表時變得很重要。 NULL 值不算是有效量值。
NULL 在不同圖表上有不同的顯示方式。 散佈圖在圖表上略過不顯示點。 橫條圖略過不顯示橫條。 在折線圖上,NULL 可能顯示為點線或虛線,如上一節的螢幕擷取畫面所示。 計算的平均值包含 NULL 時,可供計算平均值的資料點較少。 此行為有時可能導致圖表上的值突然變少,會比值轉換為零作為有效資料點更少一些。
自訂計量未收到資料時一律使用 NULL。 在平台計量方面,每個資源提供者根據何者對特定計量最有意義,決定使用零或 NULL。
Azure 監視器警示使用資源提供者寫入計量資料庫的值,請務必先檢視資料,以了解資源提供者如何處理 NULL。
彙總的運作方式
前一個系統中的計量圖表顯示各種不同的彙總資料。 系統會預先彙總資料,讓所要求的圖表可以更快地顯示,而不需要許多重複的計算。
在此範例中:
- 我們正在收集「虛構」交易計量,稱為「HTTP 失敗」
- Server 是 HTTP 失敗計量的一個維度。
- 我們有 3 個伺服器 - 伺服器 A、B 和 C。
為了簡化說明,我們只從 SUM 彙總類型開始。
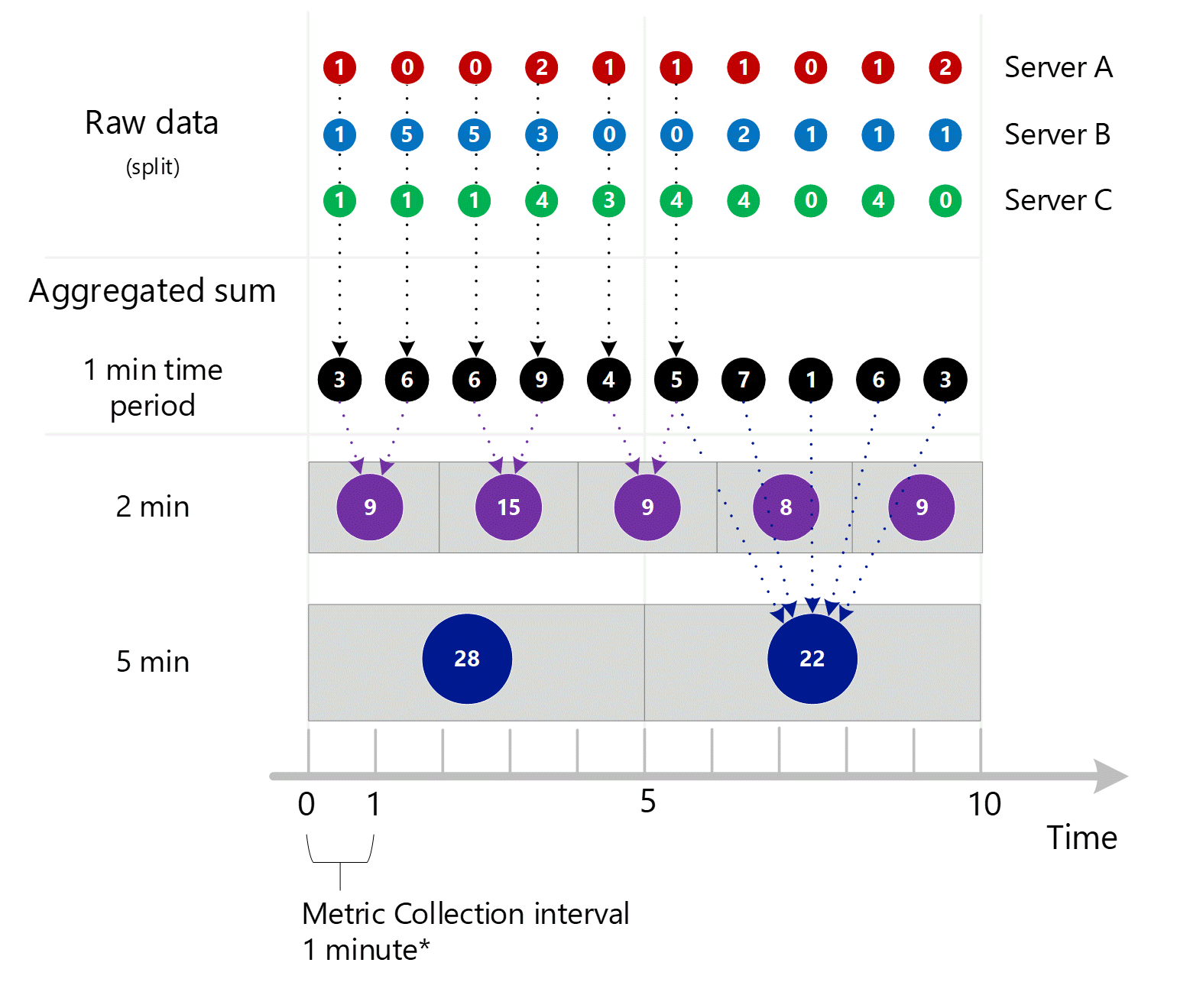
1 分鐘內到 1 分鐘彙總
首先,收集原始計量資料並儲存在 Azure 監視器計量資料庫中。 在此例子中,因為 Server 是維度,每個伺服器儲存的交易記錄都有時間戳記。 已知客戶可檢視的最短時間週期為 1 分鐘,這些時間戳記先彙總成每個伺服器的 1 分鐘計量值。 伺服器 B 的彙總流程如下圖所示。 伺服器 A 和 C 也一樣,但有不同的資料。
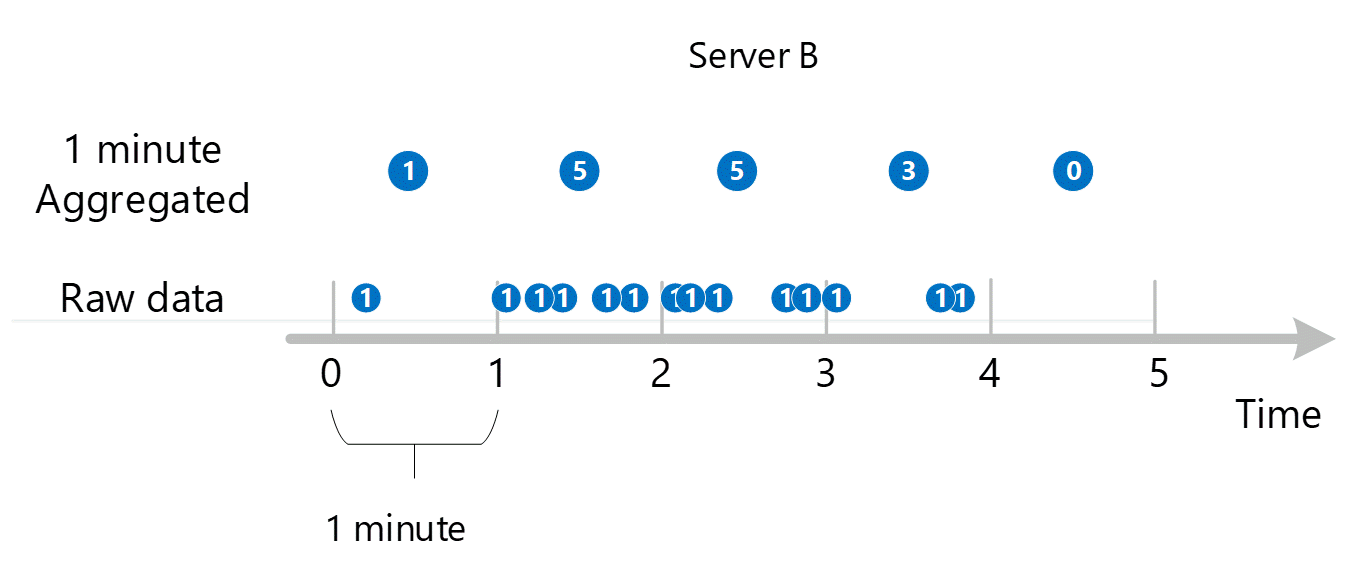
產生的 1 分鐘彙總值在計量資料庫中儲存為新項目,可收集供稍後計算。
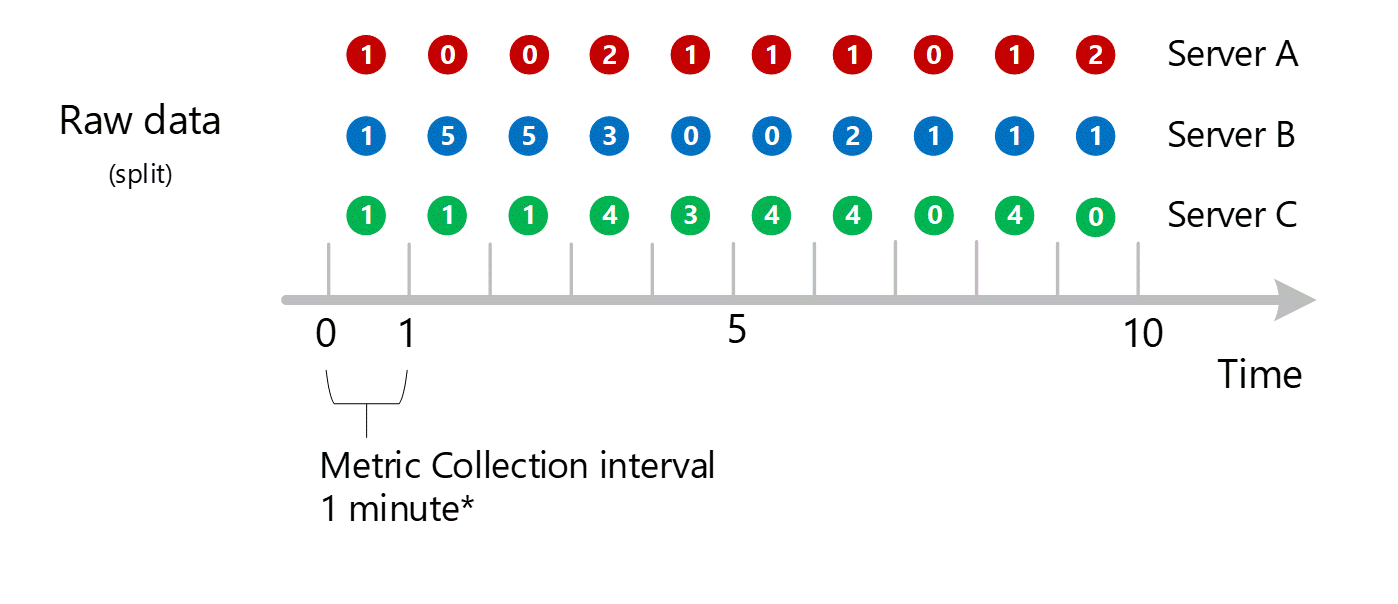
維度匯總
然後,1 分鐘計算依維度摺疊,並同樣儲存為個別記錄。 在此例子中,來自所有個別伺服器的所有資料彙總為 1 分鐘間隔計量,並儲存在計量資料庫中,供稍後彙總使用。
![螢幕擷取畫面:顯示伺服器 A、B 和 C 的多個 1 分鐘彙總項目,並彙總至 1 分鐘的 [所有伺服器] 項目](media/metrics-aggregation-explained/1-minute-transaction-dimension-flattened-aggregated.png)
為了清楚起見,下表顯示彙總方法。
| 期間 | 伺服器 A | 伺服器 B | 伺服器 C | 總和 (A+B+C) |
|---|---|---|---|---|
| 第 1 分鐘 | 1 | 1 | 1 | 3 |
| 第 2 分鐘 | 0 | 5 | 1 | 6 |
| 第 3 分鐘 | 0 | 5 | 1 | 6 |
| 第 4 分鐘 | 2 | 3 | 4 | 9 |
| 第 5 分鐘 | 1 | 0 | 3 | 4 |
| 第 6 分鐘 | 1 | 0 | 4 | 5 |
| 第 7 分鐘 | 1 | 2 | 4 | 7 |
| 第 8 分鐘 | 0 | 1 | 0 | 1 |
| 第 9 分鐘 | 1 | 1 | 4 | 6 |
| 第 10 分鐘 | 2 | 1 | 0 | 3 |
上圖只顯示一個維度,但計量支援的所有維度同樣都經過此彙總和儲存流程。
- 依該維度將值收集到 1 分鐘彙總集。 儲存這些值。
- 將維度摺疊成 1 分鐘彙總的「總和」。 儲存這些值。
讓我們引進 HTTP 失敗的另一個維度,稱為 NetworkAdapter。 假設每個伺服器的介面卡數目不同。
- 伺服器 A 有 1 個介面卡
- 伺服器 B 有 2 個介面卡
- 伺服器 C 有 3 個介面卡
我們已分別收集下列交易的資料。 都標示有:
- 時間
- 值
- 交易的來源伺服器
- 交易的來源介面卡
然後,這些 1 分鐘內的串流都彙總為 1 分鐘時間序列值,並儲存在 Azure 監視器計量資料庫中:
- 伺服器 A,介面卡 1
- 伺服器 B,介面卡 1
- 伺服器 B,介面卡 2
- 伺服器 C,介面卡 1
- 伺服器 C,介面卡 2
- 伺服器 C,介面卡 3
此外也儲存下列摺疊的彙總:
- 伺服器 A、介面卡 1 (因為沒有可摺疊的項目,所以將會再次儲存)
- 伺服器 B,介面卡 1+2
- 伺服器 C,介面卡 1+2+3
- 伺服器「全部」,介面卡「全部」
這表示計量的維度越多,彙總就越多。 不必知道所有排列,只要了解原理即可。 系統需要儲存個別資料和彙總的資料,以快速擷取供任何圖表存取。 系統根據您選擇顯示何者而定,挑選最相關已儲存的彙總或基礎未經處理資料。
無維度的彙總
因為此計量有 Server 維度,您可以透過分割和篩選來取得上述伺服器 A、B 和 C 的基礎資料,如本文稍早所述。 如果計量沒有 Server 當作維度,則客戶只能存取圖表上彙總的 1 分鐘總和 (以黑色顯示)。 也就是說,3、6、6、9 等等的值。系統也不會暗中彙總分割值,這些值絕不會在計量瀏覽器中用到,或透過計量 REST API 送出。
檢視超過 1 分鐘的時間細微性
如果您想要較大細微性的計量,系統會使用 1 分鐘彙總的總和,計算較大時間細微性的總和。 在下圖中,點線顯示 2 分鐘和 5 分鐘時間細微性的總和方法。 同樣地,為了簡單起見,我們只顯示 SUM 彙總類型。
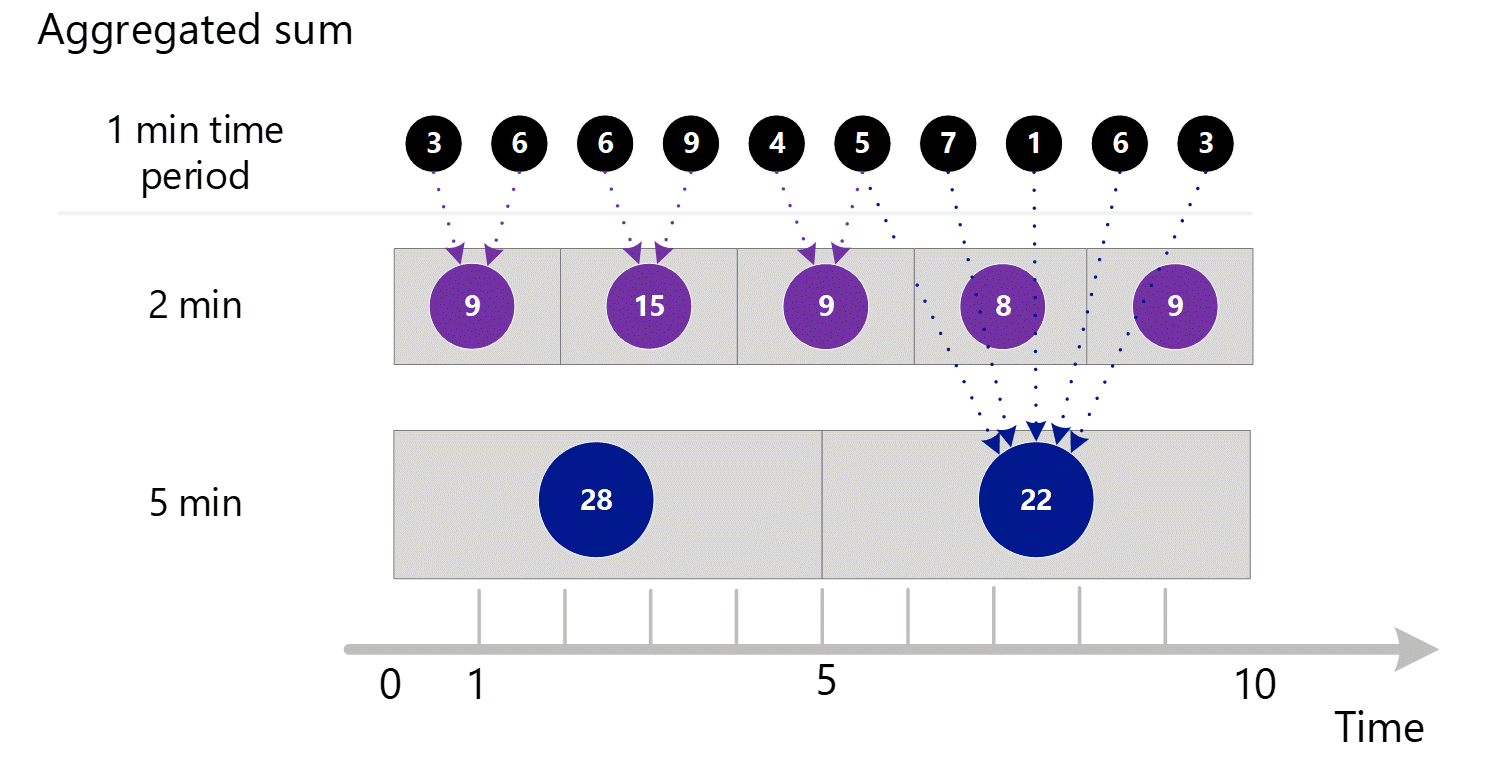
2 分鐘時間細微性。
| 期間 | 總和 |
|---|---|
| 第 1 和 2 分鐘 | (3 + 6) = 9 |
| 第 3 和 4 分鐘 | (6 + 9) = 15 |
| 第 4 和 5 分鐘 | (4 + 5) = 9 |
| 第 6 和 7 分鐘 | (7 + 1) = 8 |
| 第 8 和 9 分鐘 | (6 + 3) = 9 |
5 分鐘時間細微性。
| 期間 | 總和 |
|---|---|
| 第 1 到 5 分鐘 | 3 + 6 + 6 + 9 + 4 = 28 |
| 第 6 到 10 分鐘 | 5 + 7 + 1 + 6 + 3 = 22 |
系統使用儲存的彙總資料,以獲得最佳效能。
以下是上述 1 分鐘彙總流程的更大圖表,其中省略一些箭號來提高可讀性。
更複雜的範例
以下是更大的範例,使用虛構計量的值,稱為 HTTP 回應時間 (以毫秒為單位)。 此處介紹其他複雜度層級。
- 顯示總和、計數、最小值和最大值的彙總,以及平均值的計算。
- 顯示 NULL 值及其如何影響計算。
請思考一下下列範例。 方塊和箭號示範如何彙總和計算值。
總和、計數、最小值和最大值同樣經過上一節所述的 1 分鐘預先彙總流程。 不過,「不」會預先彙總「平均值」。 其會使用彙總的資料重新進行計算,以避免計算錯誤。

請看 1 分鐘彙總的第 6 分鐘,如上圖中醒目提示。 伺服器 B 在這分鐘離線並停止報告資料,可能因為重新開機。
從第 6 分鐘起,計算的 1 分鐘彙總類型為:
| 彙總類型 | 值 | 備註 |
|---|---|---|
| Sum | 53+20=73 | |
| 計數 | 2 | 顯示 NULL 的效果。 如果伺服器已上線,則值為 3。 |
| 最小值 | 20 | |
| 最大值 | 53 | |
| 平均 | 73 / 2 | 一律為總和除以計數。 永遠不儲存,針對每個時間細微性,一律使用該細微性的彙總數字來重新計算。 請注意 5 分鐘和 10 分鐘時間細微性的重新計算,如上圖中醒目提示。 |
紅色文字代表可能超出正常範圍的值,並指出值如何隨著時間細微性升高而傳播 (或無法傳播)。 請注意「最小值」和「最大值」如何指出基礎異常,而「平均值」和「總和」隨著時間細微性上升而遺失該資訊。
您也可以看到 NULL 計算平均值比改用零更方便。
注意
如果計量擷取的值一律為 1,則「計數」等於「總和」,只不過此範例中並非如此。 這常見於計量追蹤交易式事件的出現次數,例如本文上一個範例提及的 HTTP 失敗次數。