Azure API 管理 中產生的 AI 閘道功能概觀
適用於:所有 APIM 層
本文介紹 Azure API 管理 中的功能,可協助您管理產生 AI API,例如 Azure OpenAI 服務所提供的 API。 Azure API 管理 提供一系列原則、計量和其他功能,以增強為智慧型手機應用程式提供服務之 API 的安全性、效能和可靠性。 整體而言,這些功能稱為 產生 AI(GenAI) 閘道功能 ,適用於您的產生式 AI API。
注意
- 本文著重於管理 Azure OpenAI 服務所公開 API 的功能。 許多 GenAI 閘道功能適用於其他大型語言模型 (LLM) API,包括透過 Azure AI 模型推斷 API 取得的功能。
- 產生 AI 閘道功能是 API 管理 現有 API 閘道的功能,而不是個別的 API 閘道。 如需 API 管理 的詳細資訊,請參閱 Azure API 管理 概觀。
管理產生的 AI API 的挑戰
您在產生 AI 服務中擁有的主要資源之一是 令牌。 Azure OpenAI 服務會指派以每分鐘令牌表示的模型部署配額(TPM),然後分散到您的模型取用者 -例如,不同的應用程式、開發人員小組、公司內的部門等等。
Azure 可讓您輕鬆地將單一應用程式連線到 Azure OpenAI 服務:您可以使用 API 金鑰直接連線,並在模型部署層級上直接設定 TPM 限制。 不過,當您開始成長應用程式組合時,您會看到多個應用程式呼叫單一或甚至多個 Azure OpenAI 服務端點,部署為隨用隨付或 布建輸送量單位 (PTU) 實例。 這伴隨著某些挑戰:
- 如何在多個應用程式中追蹤令牌使用量? 針對使用 Azure OpenAI 服務模型的多個應用程式/小組,可以計算交叉費用嗎?
- 如何確保單一應用程式不會取用整個 TPM 配額,讓其他應用程式沒有使用 Azure OpenAI 服務模型的選項?
- API 金鑰如何安全地分散到多個應用程式?
- 負載如何分散到多個 Azure OpenAI 端點? 您可以確定 PTU 中認可的容量已用完,再回復為隨用隨付實例嗎?
本文的其餘部分說明 Azure API 管理 如何協助您解決這些挑戰。
將 Azure OpenAI 服務資源匯入為 API
使用單鍵體驗,將 API 從 Azure OpenAI 服務端點 匯入 Azure API 管理。 API 管理 自動匯入 Azure OpenAI API 的 OpenAPI 架構,並使用受控識別設定 Azure OpenAI 端點的驗證,以簡化上線程式,而不需要手動設定。 在相同的使用者易記體驗中,您可以預先設定 令牌限制 和 發出令牌計量的原則。

令牌限制原則
設定 Azure OpenAI 令牌限制原則 ,以根據 Azure OpenAI 服務令牌的使用方式管理及強制執行每個 API 取用者的限制。 使用此原則,您可以設定限制,以每分鐘令牌表示(TPM)。
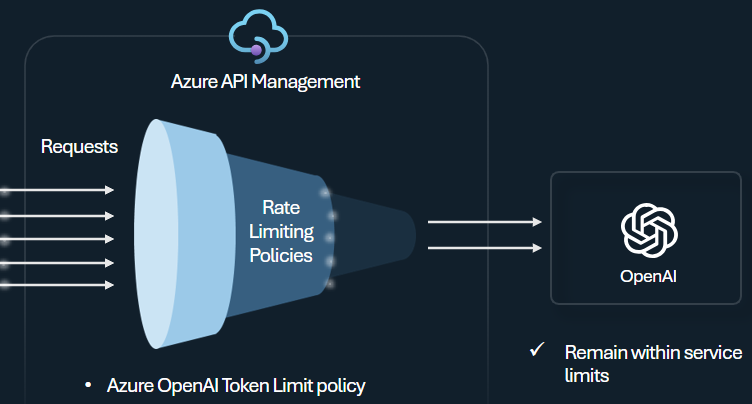
此原則提供彈性來指派任何計數器密鑰的令牌型限制,例如訂用帳戶密鑰、原始 IP 位址,或透過原則表達式定義的任意密鑰。 此原則也會在 Azure API 管理 端預先計算提示令牌,如果提示已超過限制,將對 Azure OpenAI 服務後端不必要的要求降至最低。
下列基本範例示範如何設定每個訂用帳戶密鑰 500 個 TPM 限制:
<azure-openai-token-limit counter-key="@(context.Subscription.Id)"
tokens-per-minute="500" estimate-prompt-tokens="false" remaining-tokens-variable-name="remainingTokens">
</azure-openai-token-limit>
提示
若要管理並強制執行可透過 Azure AI 模型推斷 API 取得之 LLM API 的令牌限制,API 管理 提供對等的 llm-token-limit 原則。
發出令牌計量原則
Azure OpenAI 發出令牌計量原則會透過 Azure OpenAI 服務 API 將 LLM 令牌耗用量的相關計量傳送至 Application Insights。 此原則有助於提供跨多個應用程式或 API 取用者使用 Azure OpenAI 服務模型的概觀。 此原則對於退款案例、監視和容量規劃很有用。
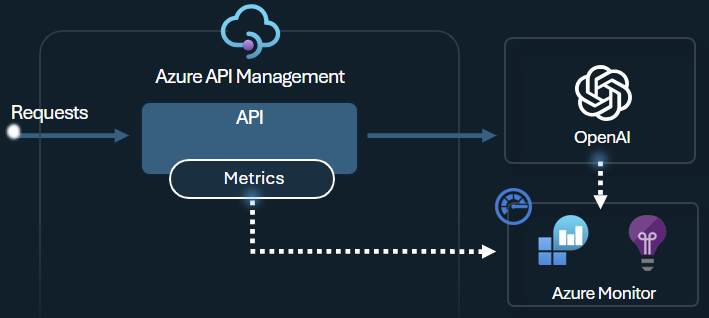
此原則會擷取提示、完成和令牌使用計量總計,並將其傳送至您選擇的 Application Insights 命名空間。 此外,您可以從預先定義的維度設定或選取來分割令牌使用計量,以便依訂用帳戶標識碼、IP 位址或您選擇的自定義維度來分析計量。
例如,下列原則會將計量傳送至依用戶端 IP 位址、API 和使用者分割的 Application Insights:
<azure-openai-emit-token-metric namespace="openai">
<dimension name="Client IP" value="@(context.Request.IpAddress)" />
<dimension name="API ID" value="@(context.Api.Id)" />
<dimension name="User ID" value="@(context.Request.Headers.GetValueOrDefault("x-user-id", "N/A"))" />
</azure-openai-emit-token-metric>
提示
若要傳送可透過 Azure AI 模型推斷 API 取得之 LLM API 的計量,API 管理 提供對等的 llm-emit-token-metric 原則。
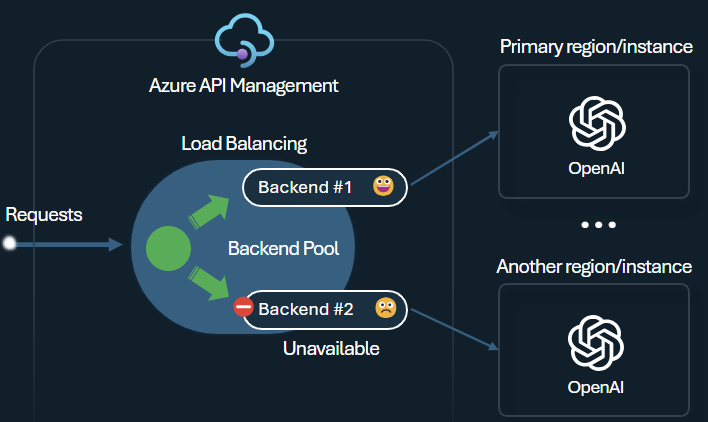
後端負載平衡器和斷路器
建置智慧型手機應用程式時,其中一個挑戰是確保應用程式能夠復原後端失敗,而且可以處理高負載。 藉由在 Azure API 管理 中使用後端來設定 Azure OpenAI 服務端點,您可以平衡其之間的負載。 如果要求沒有回應,您也可以定義斷路器規則,以停止將要求轉送至 Azure OpenAI 服務後端。
後端 負載平衡器 支援迴圈配置資源、加權和優先順序型負載平衡,讓您有彈性地定義符合特定需求的負載平衡策略。 例如,在負載平衡器組態中定義優先順序,以確保特定 Azure OpenAI 端點的最佳使用率,特別是購買為 PTU 的端點。
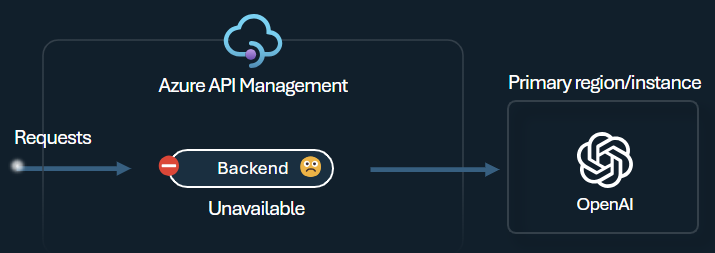
後端 斷路器 具有動態行程持續時間,並套用來自後端所提供之 Retry-After 標頭的值。 這可確保後端的精確且及時復原,將優先順序後端的使用率最大化。
語意快取原則
設定 Azure OpenAI 語意快 取原則,藉由儲存類似提示的完成,將令牌使用優化。
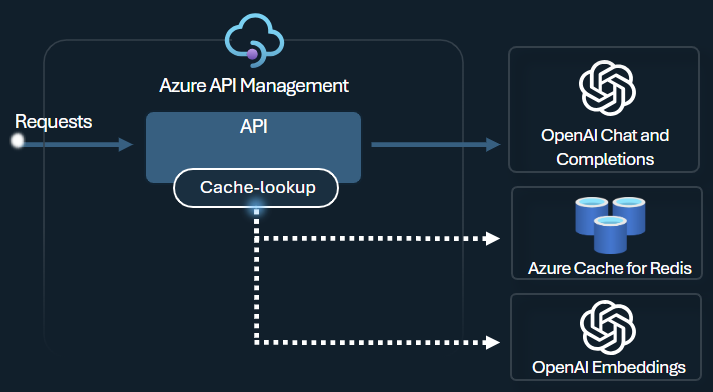
在 API 管理 中,使用 Azure Redis Enterprise 或其他與 RediSearch 相容的外部快取,並上線至 Azure API 管理,來啟用語意快取。 藉由使用 Azure OpenAI 服務內嵌 API,azure-openai-semantic-cache-store 和 azure-openai-semantic-cache-lookup 原則存放區,並從快取擷取語意上類似的提示完成。 此方法可確保完成重複使用,進而降低令牌耗用量並改善回應效能。
提示
若要為可透過 Azure AI 模型推斷 API 取得的 LLM API 啟用語意快取,API 管理 提供對等的 llm-semantic-cache-store-policy 和 llm-semantic-cache-lookup-policy 原則。
實驗室和範例
- Azure API 管理 GenAI 閘道功能的實驗室
- Azure API 管理 (APIM) - Azure OpenAI 範例 (Node.js)
- 使用 Azure OpenAI 搭配 API 管理 的 Python 範例程序代碼