快速入門:開始使用 Azure OpenAI 音訊產生
此 gpt-4o-audio-preview 模型會將音訊形式引入現有的 /chat/completions API。 音訊模型擴充了文字和語音型互動和音訊分析中 AI 應用程式的潛力。 模型中支援 gpt-4o-audio-preview 的形式包括:文字、音訊和文字 + 音訊。
以下是具有範例使用案例的支援形式數據表:
| 形式輸入 | Modality 輸出 | 使用案例範例 |
|---|---|---|
| Text | 文字 + 音訊 | 文字到語音轉換,音訊書籍產生 |
| 音訊 | 文字 + 音訊 | 音訊轉譯,音訊書籍產生 |
| 音訊 | Text | 音訊轉錄 |
| 文字 + 音訊 | 文字 + 音訊 | 音訊書籍產生 |
| 文字 + 音訊 | Text | 音訊轉錄 |
藉由使用音訊產生功能,您可以達成更動態和互動式的 AI 應用程式。 支援音訊輸入和輸出的模型可讓您產生提示的語音回應,並使用音訊輸入來提示模型。
支援的模型
目前只有 gpt-4o-audio-preview 版本: 2024-12-17 支援音訊產生。
此gpt-4o-audio-preview模型適用於美國東部 2 和瑞典中部地區的全域部署。
目前支援音訊輸出的下列聲音:合金、Echo 和填充器。
音訊檔案大小上限為 20 MB。
注意
即時 API 會使用與完成 API 相同的基礎 GPT-4o 音訊模型,但已針對低延遲、即時音訊互動進行優化。
API 支援
第一次在 API 版本中 2025-01-01-preview新增對音訊完成的支援。
部署用於產生音訊的模型
若要在 Azure AI Foundry 入口網站中部署 gpt-4o-audio-preview 模型:
- 移至 Azure AI Foundry 入口網站中的 Azure OpenAI 服務頁面 。 請確定您已使用具有 Azure OpenAI 服務資源和已
gpt-4o-audio-preview部署模型的 Azure 訂用帳戶登入。 - 從左窗格中的 [遊樂場] 底下選取 [聊天遊樂場]。
- 選取 [+ 從基底模型建立新的部署>],以開啟部署視窗。
- 搜尋並選取模型,
gpt-4o-audio-preview然後選取 [ 部署到選取的資源]。 - 在部署精靈中,選取
2024-12-17模型版本。 - 遵循精靈以完成模型部署。
現在您已部署 gpt-4o-audio-preview 模型,您可以在 Azure AI Foundry 入口網站 聊天 遊樂場或聊天完成 API 中與其互動。
使用 GPT-4o 音訊產生
若要在 Azure AI Foundry 入口網站的 Chat 遊樂場中與您的已gpt-4o-audio-preview部署模型聊天,請遵循下列步驟:
移至 Azure AI Foundry 入口網站中的 Azure OpenAI 服務頁面 。 請確定您已使用具有 Azure OpenAI 服務資源和已
gpt-4o-audio-preview部署模型的 Azure 訂用帳戶登入。從左窗格中的 [資源遊樂場] 底下選取 [聊天遊樂場]。
從 [部署] 下拉式
gpt-4o-audio-preview清單中選取已部署的模型。開始與模型聊天,並接聽音訊回應。
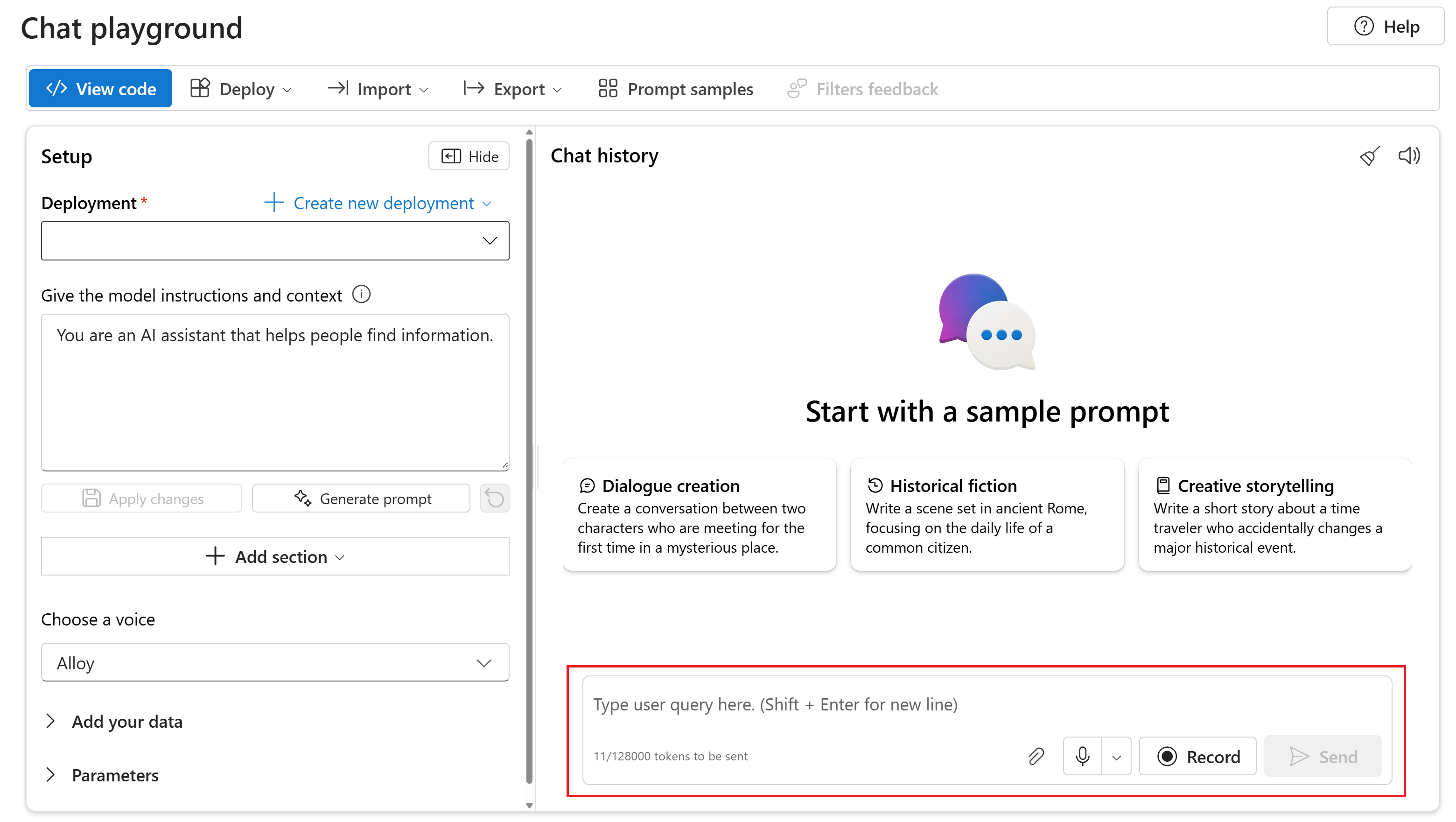
您可以:
- 錄製音訊提示。
- 將音訊檔案附加至聊天。
- 輸入文字提示。

參考文件 | 程式庫來源程式碼 | 套件 (npm) | 範例
此 gpt-4o-audio-preview 模型會將音訊形式引入現有的 /chat/completions API。 音訊模型擴充了文字和語音型互動和音訊分析中 AI 應用程式的潛力。 模型中支援 gpt-4o-audio-preview 的形式包括:文字、音訊和文字 + 音訊。
以下是具有範例使用案例的支援形式數據表:
| 形式輸入 | Modality 輸出 | 使用案例範例 |
|---|---|---|
| Text | 文字 + 音訊 | 文字到語音轉換,音訊書籍產生 |
| 音訊 | 文字 + 音訊 | 音訊轉譯,音訊書籍產生 |
| 音訊 | Text | 音訊轉錄 |
| 文字 + 音訊 | 文字 + 音訊 | 音訊書籍產生 |
| 文字 + 音訊 | Text | 音訊轉錄 |
藉由使用音訊產生功能,您可以達成更動態和互動式的 AI 應用程式。 支援音訊輸入和輸出的模型可讓您產生提示的語音回應,並使用音訊輸入來提示模型。
支援的模型
目前只有 gpt-4o-audio-preview 版本: 2024-12-17 支援音訊產生。
此gpt-4o-audio-preview模型適用於美國東部 2 和瑞典中部地區的全域部署。
目前支援音訊輸出的下列聲音:合金、Echo 和填充器。
音訊檔案大小上限為 20 MB。
注意
即時 API 會使用與完成 API 相同的基礎 GPT-4o 音訊模型,但已針對低延遲、即時音訊互動進行優化。
API 支援
第一次在 API 版本中 2025-01-01-preview新增對音訊完成的支援。
必要條件
- Azure 訂用帳戶 - 建立免費帳戶
- Node.js LTS 或 ESM 支援。
- 在美國東部 2 或瑞典中部區域建立的 Azure OpenAI 資源。 請參閱區域可用性 (英文)。
- 然後,您必須使用 Azure OpenAI 資源來部署
gpt-4o-audio-preview模型。 如需詳細資訊,請參閱使用 Azure OpenAI 建立資源及部署模型。
Microsoft Entra ID 必要條件
針對具有 Microsoft Entra ID 的建議無金鑰驗證,您需要:
- 使用 Microsoft Entra ID 安裝用於無密鑰驗證的 Azure CLI。
- 將
Cognitive Services User角色指派給您的使用者帳戶。 您可以在存取控制 (IAM)>[新增角色指派] 底下的 [Azure 入口網站 中指派角色。
設定
使用下列命令,建立新資料夾
audio-completions-quickstart以包含應用程式,並在該資料夾中開啟 Visual Studio Code:mkdir audio-completions-quickstart && code audio-completions-quickstartpackage.json使用下列指令建立 :npm init -ypackage.json使用下列命令將更新為 ECMAScript:npm pkg set type=module使用下列專案安裝適用於 JavaScript 的 OpenAI 用戶端連結庫:
npm install openai如需使用 Microsoft Entra ID 的建議 無金鑰驗證,請使用下列專案安裝
@azure/identity套件:npm install @azure/identity
擷取資源資訊
您需要擷取下列資訊,以向 Azure OpenAI 資源驗證您的應用程式:
| 變數名稱 | 值 |
|---|---|
AZURE_OPENAI_ENDPOINT |
在 Azure 入口網站查看資源時,您可以在 [金鑰和端點] 區段中找到此值。 |
AZURE_OPENAI_DEPLOYMENT_NAME |
此值會對應至您在部署模型時為部署選擇的自訂名稱。 您可以在 Azure 入口網站 中的資源管理>模型部署下找到此值。 |
OPENAI_API_VERSION |
深入瞭解 API 版本。 |
警告
若要搭配 SDK 使用建議的無密鑰驗證,請確定 AZURE_OPENAI_API_KEY 未設定環境變數。
從文字輸入產生音訊
to-audio.js使用下列程式代碼建立檔案:require("dotenv").config(); const { AzureOpenAI } = require("openai"); const { DefaultAzureCredential, getBearerTokenProvider } = require("@azure/identity"); const { writeFileSync } = require("node:fs"); // Keyless authentication const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); // Set environment variables or edit the corresponding values here. const endpoint = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion = "2025-01-01-preview"; const deployment = "gpt-4o-audio-preview"; const client = new AzureOpenAI({ endpoint, azureADTokenProvider, apiVersion, deployment }); async function main() { // Make the audio chat completions request const response = await client.chat.completions.create({ model: "gpt-4o-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: [ { role: "user", content: "Is a golden retriever a good family dog?" } ] }); // Inspect returned data console.log(response.choices[0]); // Write the output audio data to a file writeFileSync( "dog.wav", Buffer.from(response.choices[0].message.audio.data, 'base64'), { encoding: "utf-8" } ); } main().catch((err) => { console.error("Error occurred:", err); }); module.exports = { main };使用下列命令登入 Azure:
az login執行 JavaScript 檔案。
node to-audio.js
請稍候片刻以取得回應。
從文字輸入產生音訊的輸出
腳本會在與腳本相同的目錄中產生名為 dog.wav 的音訊檔案。 音訊檔案包含提示的口語回應:「黃金擷取器是好家庭狗嗎?
從音訊輸入產生音訊和文字
from-audio.js使用下列程式代碼建立檔案:require("dotenv").config(); const { AzureOpenAI } = require("openai"); const { DefaultAzureCredential, getBearerTokenProvider } = require("@azure/identity"); const fs = require('fs').promises; const { writeFileSync } = require("node:fs"); // Keyless authentication const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); // Set environment variables or edit the corresponding values here. const endpoint = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion = "2025-01-01-preview"; const deployment = "gpt-4o-audio-preview"; const client = new AzureOpenAI({ endpoint, azureADTokenProvider, apiVersion, deployment }); async function main() { // Buffer the audio for input to the chat completion const wavBuffer = await fs.readFile("dog.wav"); const base64str = Buffer.from(wavBuffer).toString("base64"); // Make the audio chat completions request const response = await client.chat.completions.create({ model: "gpt-4o-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: [ { role: "user", content: [ { type: "text", text: "Describe in detail the spoken audio input." }, { type: "input_audio", input_audio: { data: base64str, format: "wav" } } ] } ] }); console.log(response.choices[0]); // Write the output audio data to a file writeFileSync( "analysis.wav", Buffer.from(response.choices[0].message.audio.data, 'base64'), { encoding: "utf-8" } ); } main().catch((err) => { console.error("Error occurred:", err); }); module.exports = { main };使用下列命令登入 Azure:
az login執行 JavaScript 檔案。
node from-audio.js
請稍候片刻以取得回應。
從音訊輸入產生音訊和文字的輸出
腳本會產生口語音頻輸入摘要的文字記錄。 它也會在與腳本相同的目錄中產生名為 analysis.wav 的音訊檔案。 音訊檔案包含提示的語音回應。
產生音訊並使用多回合聊天完成
multi-turn.js使用下列程式代碼建立檔案:require("dotenv").config(); const { AzureOpenAI } = require("openai"); const { DefaultAzureCredential, getBearerTokenProvider } = require("@azure/identity"); const fs = require('fs').promises; // Keyless authentication const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); // Set environment variables or edit the corresponding values here. const endpoint = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion = "2025-01-01-preview"; const deployment = "gpt-4o-audio-preview"; const client = new AzureOpenAI({ endpoint, azureADTokenProvider, apiVersion, deployment }); async function main() { // Buffer the audio for input to the chat completion const wavBuffer = await fs.readFile("dog.wav"); const base64str = Buffer.from(wavBuffer).toString("base64"); // Initialize messages with the first turn's user input const messages = [ { role: "user", content: [ { type: "text", text: "Describe in detail the spoken audio input." }, { type: "input_audio", input_audio: { data: base64str, format: "wav" } } ] } ]; // Get the first turn's response const response = await client.chat.completions.create({ model: "gpt-4o-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: messages }); console.log(response.choices[0]); // Add a history message referencing the previous turn's audio by ID messages.push({ role: "assistant", audio: { id: response.choices[0].message.audio.id } }); // Add a new user message for the second turn messages.push({ role: "user", content: [ { type: "text", text: "Very concisely summarize the favorability." } ] }); // Send the follow-up request with the accumulated messages const followResponse = await client.chat.completions.create({ model: "gpt-4o-audio-preview", messages: messages }); console.log(followResponse.choices[0].message.content); } main().catch((err) => { console.error("Error occurred:", err); }); module.exports = { main };使用下列命令登入 Azure:
az login執行 JavaScript 檔案。
node multi-turn.js
請稍候片刻以取得回應。
多回合聊天完成的輸出
腳本會產生口語音頻輸入摘要的文字記錄。 然後,它會進行多回合聊天完成,以簡短摘要口語音頻輸入。
此 gpt-4o-audio-preview 模型會將音訊形式引入現有的 /chat/completions API。 音訊模型擴充了文字和語音型互動和音訊分析中 AI 應用程式的潛力。 模型中支援 gpt-4o-audio-preview 的形式包括:文字、音訊和文字 + 音訊。
以下是具有範例使用案例的支援形式數據表:
| 形式輸入 | Modality 輸出 | 使用案例範例 |
|---|---|---|
| Text | 文字 + 音訊 | 文字到語音轉換,音訊書籍產生 |
| 音訊 | 文字 + 音訊 | 音訊轉譯,音訊書籍產生 |
| 音訊 | Text | 音訊轉錄 |
| 文字 + 音訊 | 文字 + 音訊 | 音訊書籍產生 |
| 文字 + 音訊 | Text | 音訊轉錄 |
藉由使用音訊產生功能,您可以達成更動態和互動式的 AI 應用程式。 支援音訊輸入和輸出的模型可讓您產生提示的語音回應,並使用音訊輸入來提示模型。
支援的模型
目前只有 gpt-4o-audio-preview 版本: 2024-12-17 支援音訊產生。
此gpt-4o-audio-preview模型適用於美國東部 2 和瑞典中部地區的全域部署。
目前支援音訊輸出的下列聲音:合金、Echo 和填充器。
音訊檔案大小上限為 20 MB。
注意
即時 API 會使用與完成 API 相同的基礎 GPT-4o 音訊模型,但已針對低延遲、即時音訊互動進行優化。
API 支援
第一次在 API 版本中 2025-01-01-preview新增對音訊完成的支援。
使用本指南開始使用適用於 Python 的 Azure OpenAI SDK 產生音訊。
必要條件
- Azure 訂用帳戶。 免費建立一個。
- Python 3.8 或更新版本。 我們建議使用 Python 3.10 或更新版本,但至少需要 Python 3.8。 如果您未安裝適當的 Python 版本,可以遵循 VS Code Python 教學課程中的指示,以了解在作業系統上安裝 Python 的最簡單方式。
- 在美國東部 2 或瑞典中部區域建立的 Azure OpenAI 資源。 請參閱區域可用性 (英文)。
- 然後,您必須使用 Azure OpenAI 資源來部署
gpt-4o-audio-preview模型。 如需詳細資訊,請參閱使用 Azure OpenAI 建立資源及部署模型。
Microsoft Entra ID 必要條件
針對具有 Microsoft Entra ID 的建議無金鑰驗證,您需要:
- 使用 Microsoft Entra ID 安裝用於無密鑰驗證的 Azure CLI。
- 將
Cognitive Services User角色指派給您的使用者帳戶。 您可以在存取控制 (IAM)>[新增角色指派] 底下的 [Azure 入口網站 中指派角色。
設定
使用下列命令,建立新資料夾
audio-completions-quickstart以包含應用程式,並在該資料夾中開啟 Visual Studio Code:mkdir audio-completions-quickstart && code audio-completions-quickstart建立虛擬環境。 如果您已安裝 Python 3.10 或更高版本,您可以使用下列命令來建立虛擬環境:
啟用 Python 環境表示,當您命令列執行
python或pip,將會使用應用程式的.venv資料夾中所包含的 Python 解譯器。 您可以使用deactivate命令來結束 Python 虛擬環境,並可以稍後視需要重新啟用它。提示
建議您建立並啟用新的 Python 環境,以用來安裝本教學課程所需的套件。 請勿將套件安裝到您的全域 Python 安裝中。 安裝 Python 套件時,您應該一律使用虛擬或 conda 環境,否則您可以中斷 Python 的全域安裝。
使用下列專案安裝適用於 Python 的 OpenAI 用戶端連結庫:
pip install openai如需使用 Microsoft Entra ID 的建議 無金鑰驗證,請使用下列專案安裝
azure-identity套件:pip install azure-identity
擷取資源資訊
您需要擷取下列資訊,以向 Azure OpenAI 資源驗證您的應用程式:
| 變數名稱 | 值 |
|---|---|
AZURE_OPENAI_ENDPOINT |
在 Azure 入口網站查看資源時,您可以在 [金鑰和端點] 區段中找到此值。 |
AZURE_OPENAI_DEPLOYMENT_NAME |
此值會對應至您在部署模型時為部署選擇的自訂名稱。 您可以在 Azure 入口網站 中的資源管理>模型部署下找到此值。 |
OPENAI_API_VERSION |
深入瞭解 API 版本。 |
從文字輸入產生音訊
to-audio.py使用下列程式代碼建立檔案:import requests import base64 import os from openai import AzureOpenAI from azure.identity import DefaultAzureCredential, get_bearer_token_provider token_provider=get_bearer_token_provider(DefaultAzureCredential(), "https://cognitiveservices.azure.com/.default") # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication client=AzureOpenAI( azure_ad_token_provider=token_provider, azure_endpoint=endpoint, api_version="2025-01-01-preview" ) # Make the audio chat completions request completion=client.chat.completions.create( model="gpt-4o-audio-preview", modalities=["text", "audio"], audio={"voice": "alloy", "format": "wav"}, messages=[ { "role": "user", "content": "Is a golden retriever a good family dog?" } ] ) print(completion.choices[0]) # Write the output audio data to a file wav_bytes=base64.b64decode(completion.choices[0].message.audio.data) with open("dog.wav", "wb") as f: f.write(wav_bytes)執行 Python 檔案。
python to-audio.py
請稍候片刻以取得回應。
從文字輸入產生音訊的輸出
腳本會在與腳本相同的目錄中產生名為 dog.wav 的音訊檔案。 音訊檔案包含提示的口語回應:「黃金擷取器是好家庭狗嗎?
從音訊輸入產生音訊和文字
from-audio.py使用下列程式代碼建立檔案:import base64 import os from openai import AzureOpenAI from azure.identity import DefaultAzureCredential, get_bearer_token_provider token_provider=get_bearer_token_provider(DefaultAzureCredential(), "https://cognitiveservices.azure.com/.default") # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication client=AzureOpenAI( azure_ad_token_provider=token_provider, azure_endpoint=endpoint api_version="2025-01-01-preview" ) # Read and encode audio file with open('dog.wav', 'rb') as wav_reader: encoded_string = base64.b64encode(wav_reader.read()).decode('utf-8') # Make the audio chat completions request completion = client.chat.completions.create( model="gpt-4o-audio-preview", modalities=["text", "audio"], audio={"voice": "alloy", "format": "wav"}, messages=[ { "role": "user", "content": [ { "type": "text", "text": "Describe in detail the spoken audio input." }, { "type": "input_audio", "input_audio": { "data": encoded_string, "format": "wav" } } ] }, ] ) print(completion.choices[0].message.audio.transcript) # Write the output audio data to a file wav_bytes = base64.b64decode(completion.choices[0].message.audio.data) with open("analysis.wav", "wb") as f: f.write(wav_bytes)執行 Python 檔案。
python from-audio.py
請稍候片刻以取得回應。
從音訊輸入產生音訊和文字的輸出
腳本會產生口語音頻輸入摘要的文字記錄。 它也會在與腳本相同的目錄中產生名為 analysis.wav 的音訊檔案。 音訊檔案包含提示的語音回應。
產生音訊並使用多回合聊天完成
multi-turn.py使用下列程式代碼建立檔案:import base64 import os from openai import AzureOpenAI from azure.identity import DefaultAzureCredential, get_bearer_token_provider token_provider=get_bearer_token_provider(DefaultAzureCredential(), "https://cognitiveservices.azure.com/.default") # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication client=AzureOpenAI( azure_ad_token_provider=token_provider, azure_endpoint=endpoint, api_version="2025-01-01-preview" ) # Read and encode audio file with open('dog.wav', 'rb') as wav_reader: encoded_string = base64.b64encode(wav_reader.read()).decode('utf-8') # Initialize messages with the first turn's user input messages = [ { "role": "user", "content": [ { "type": "text", "text": "Describe in detail the spoken audio input." }, { "type": "input_audio", "input_audio": { "data": encoded_string, "format": "wav" } } ] }] # Get the first turn's response completion = client.chat.completions.create( model="gpt-4o-audio-preview", modalities=["text", "audio"], audio={"voice": "alloy", "format": "wav"}, messages=messages ) print("Get the first turn's response:") print(completion.choices[0].message.audio.transcript) print("Add a history message referencing the first turn's audio by ID:") print(completion.choices[0].message.audio.id) # Add a history message referencing the first turn's audio by ID messages.append({ "role": "assistant", "audio": { "id": completion.choices[0].message.audio.id } }) # Add the next turn's user message messages.append({ "role": "user", "content": "Very briefly, summarize the favorability." }) # Send the follow-up request with the accumulated messages completion = client.chat.completions.create( model="gpt-4o-audio-preview", messages=messages ) print("Very briefly, summarize the favorability.") print(completion.choices[0].message.content)執行 Python 檔案。
python multi-turn.py
請稍候片刻以取得回應。
多回合聊天完成的輸出
腳本會產生口語音頻輸入摘要的文字記錄。 然後,它會進行多回合聊天完成,以簡短摘要口語音頻輸入。
REST API 規格 | (英文)
此 gpt-4o-audio-preview 模型會將音訊形式引入現有的 /chat/completions API。 音訊模型擴充了文字和語音型互動和音訊分析中 AI 應用程式的潛力。 模型中支援 gpt-4o-audio-preview 的形式包括:文字、音訊和文字 + 音訊。
以下是具有範例使用案例的支援形式數據表:
| 形式輸入 | Modality 輸出 | 使用案例範例 |
|---|---|---|
| Text | 文字 + 音訊 | 文字到語音轉換,音訊書籍產生 |
| 音訊 | 文字 + 音訊 | 音訊轉譯,音訊書籍產生 |
| 音訊 | Text | 音訊轉錄 |
| 文字 + 音訊 | 文字 + 音訊 | 音訊書籍產生 |
| 文字 + 音訊 | Text | 音訊轉錄 |
藉由使用音訊產生功能,您可以達成更動態和互動式的 AI 應用程式。 支援音訊輸入和輸出的模型可讓您產生提示的語音回應,並使用音訊輸入來提示模型。
支援的模型
目前只有 gpt-4o-audio-preview 版本: 2024-12-17 支援音訊產生。
此gpt-4o-audio-preview模型適用於美國東部 2 和瑞典中部地區的全域部署。
目前支援音訊輸出的下列聲音:合金、Echo 和填充器。
音訊檔案大小上限為 20 MB。
注意
即時 API 會使用與完成 API 相同的基礎 GPT-4o 音訊模型,但已針對低延遲、即時音訊互動進行優化。
API 支援
第一次在 API 版本中 2025-01-01-preview新增對音訊完成的支援。
必要條件
- Azure 訂用帳戶。 免費建立一個。
- Python 3.8 或更新版本。 我們建議使用 Python 3.10 或更新版本,但至少需要 Python 3.8。 如果您未安裝適當的 Python 版本,可以遵循 VS Code Python 教學課程中的指示,以了解在作業系統上安裝 Python 的最簡單方式。
- 在美國東部 2 或瑞典中部區域建立的 Azure OpenAI 資源。 請參閱區域可用性 (英文)。
- 然後,您必須使用 Azure OpenAI 資源來部署
gpt-4o-audio-preview模型。 如需詳細資訊,請參閱使用 Azure OpenAI 建立資源及部署模型。
Microsoft Entra ID 必要條件
針對具有 Microsoft Entra ID 的建議無金鑰驗證,您需要:
- 使用 Microsoft Entra ID 安裝用於無密鑰驗證的 Azure CLI。
- 將
Cognitive Services User角色指派給您的使用者帳戶。 您可以在存取控制 (IAM)>[新增角色指派] 底下的 [Azure 入口網站 中指派角色。
設定
使用下列命令,建立新資料夾
audio-completions-quickstart以包含應用程式,並在該資料夾中開啟 Visual Studio Code:mkdir audio-completions-quickstart && code audio-completions-quickstart建立虛擬環境。 如果您已安裝 Python 3.10 或更高版本,您可以使用下列命令來建立虛擬環境:
啟用 Python 環境表示,當您命令列執行
python或pip,將會使用應用程式的.venv資料夾中所包含的 Python 解譯器。 您可以使用deactivate命令來結束 Python 虛擬環境,並可以稍後視需要重新啟用它。提示
建議您建立並啟用新的 Python 環境,以用來安裝本教學課程所需的套件。 請勿將套件安裝到您的全域 Python 安裝中。 安裝 Python 套件時,您應該一律使用虛擬或 conda 環境,否則您可以中斷 Python 的全域安裝。
使用下列專案安裝適用於 Python 的 OpenAI 用戶端連結庫:
pip install openai如需使用 Microsoft Entra ID 的建議 無金鑰驗證,請使用下列專案安裝
azure-identity套件:pip install azure-identity
擷取資源資訊
您需要擷取下列資訊,以向 Azure OpenAI 資源驗證您的應用程式:
| 變數名稱 | 值 |
|---|---|
AZURE_OPENAI_ENDPOINT |
在 Azure 入口網站查看資源時,您可以在 [金鑰和端點] 區段中找到此值。 |
AZURE_OPENAI_DEPLOYMENT_NAME |
此值會對應至您在部署模型時為部署選擇的自訂名稱。 您可以在 Azure 入口網站 中的資源管理>模型部署下找到此值。 |
OPENAI_API_VERSION |
深入瞭解 API 版本。 |
從文字輸入產生音訊
to-audio.py使用下列程式代碼建立檔案:import requests import base64 import os from openai import AzureOpenAI from azure.identity import DefaultAzureCredential # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication credential = DefaultAzureCredential() token = credential.get_token("https://cognitiveservices.azure.com/.default") api_version = '2025-01-01-preview' url = f"{endpoint}/openai/deployments/gpt-4o-audio-preview/chat/completions?api-version={api_version}" headers= { "Authorization": f"Bearer {token.token}", "Content-Type": "application/json" } body = { "modalities": ["audio", "text"], "model": "gpt-4o-audio-preview", "audio": { "format": "wav", "voice": "alloy" }, "messages": [ { "role": "user", "content": [ { "type": "text", "text": "Is a golden retriever a good family dog?" } ] } ] } # Make the audio chat completions request completion = requests.post(url, headers=headers, json=body) audio_data = completion.json()['choices'][0]['message']['audio']['data'] # Write the output audio data to a file wav_bytes = base64.b64decode(audio_data) with open("dog.wav", "wb") as f: f.write(wav_bytes)執行 Python 檔案。
python to-audio.py
請稍候片刻以取得回應。
從文字輸入產生音訊的輸出
腳本會在與腳本相同的目錄中產生名為 dog.wav 的音訊檔案。 音訊檔案包含提示的口語回應:「黃金擷取器是好家庭狗嗎?
從音訊輸入產生音訊和文字
from-audio.py使用下列程式代碼建立檔案:import requests import base64 import os from azure.identity import DefaultAzureCredential # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication credential = DefaultAzureCredential() token = credential.get_token("https://cognitiveservices.azure.com/.default") # Read and encode audio file with open('dog.wav', 'rb') as wav_reader: encoded_string = base64.b64encode(wav_reader.read()).decode('utf-8') api_version = '2025-01-01-preview' url = f"{endpoint}/openai/deployments/gpt-4o-audio-preview/chat/completions?api-version={api_version}" headers= { "Authorization": f"Bearer {token.token}", "Content-Type": "application/json" } body = { "modalities": ["audio", "text"], "model": "gpt-4o-audio-preview", "audio": { "format": "wav", "voice": "alloy" }, "messages": [ { "role": "user", "content": [ { "type": "text", "text": "Describe in detail the spoken audio input." }, { "type": "input_audio", "input_audio": { "data": encoded_string, "format": "wav" } } ] }, ] } completion = requests.post(url, headers=headers, json=body) print(completion.json()['choices'][0]['message']['audio']['transcript']) # Write the output audio data to a file audio_data = completion.json()['choices'][0]['message']['audio']['data'] wav_bytes = base64.b64decode(audio_data) with open("analysis.wav", "wb") as f: f.write(wav_bytes)執行 Python 檔案。
python from-audio.py
請稍候片刻以取得回應。
從音訊輸入產生音訊和文字的輸出
腳本會產生口語音頻輸入摘要的文字記錄。 它也會在與腳本相同的目錄中產生名為 analysis.wav 的音訊檔案。 音訊檔案包含提示的語音回應。
產生音訊並使用多回合聊天完成
multi-turn.py使用下列程式代碼建立檔案:import requests import base64 import os from openai import AzureOpenAI from azure.identity import DefaultAzureCredential # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication credential = DefaultAzureCredential() token = credential.get_token("https://cognitiveservices.azure.com/.default") api_version = '2025-01-01-preview' url = f"{endpoint}/openai/deployments/gpt-4o-audio-preview/chat/completions?api-version={api_version}" headers= { "Authorization": f"Bearer {token.token}", "Content-Type": "application/json" } # Read and encode audio file with open('dog.wav', 'rb') as wav_reader: encoded_string = base64.b64encode(wav_reader.read()).decode('utf-8') # Initialize messages with the first turn's user input messages = [ { "role": "user", "content": [ { "type": "text", "text": "Describe in detail the spoken audio input." }, { "type": "input_audio", "input_audio": { "data": encoded_string, "format": "wav" } } ] }] body = { "modalities": ["audio", "text"], "model": "gpt-4o-audio-preview", "audio": { "format": "wav", "voice": "alloy" }, "messages": messages } # Get the first turn's response, including generated audio completion = requests.post(url, headers=headers, json=body) print("Get the first turn's response:") print(completion.json()['choices'][0]['message']['audio']['transcript']) print("Add a history message referencing the first turn's audio by ID:") print(completion.json()['choices'][0]['message']['audio']['id']) # Add a history message referencing the first turn's audio by ID messages.append({ "role": "assistant", "audio": { "id": completion.json()['choices'][0]['message']['audio']['id'] } }) # Add the next turn's user message messages.append({ "role": "user", "content": "Very briefly, summarize the favorability." }) body = { "model": "gpt-4o-audio-preview", "messages": messages } # Send the follow-up request with the accumulated messages completion = requests.post(url, headers=headers, json=body) print("Very briefly, summarize the favorability.") print(completion.json()['choices'][0]['message']['content'])執行 Python 檔案。
python multi-turn.py
請稍候片刻以取得回應。
多回合聊天完成的輸出
腳本會產生口語音頻輸入摘要的文字記錄。 然後,它會進行多回合聊天完成,以簡短摘要口語音頻輸入。
參考文件 | 程式庫來源程式碼 | 套件 (npm) | 範例
此 gpt-4o-audio-preview 模型會將音訊形式引入現有的 /chat/completions API。 音訊模型擴充了文字和語音型互動和音訊分析中 AI 應用程式的潛力。 模型中支援 gpt-4o-audio-preview 的形式包括:文字、音訊和文字 + 音訊。
以下是具有範例使用案例的支援形式數據表:
| 形式輸入 | Modality 輸出 | 使用案例範例 |
|---|---|---|
| Text | 文字 + 音訊 | 文字到語音轉換,音訊書籍產生 |
| 音訊 | 文字 + 音訊 | 音訊轉譯,音訊書籍產生 |
| 音訊 | Text | 音訊轉錄 |
| 文字 + 音訊 | 文字 + 音訊 | 音訊書籍產生 |
| 文字 + 音訊 | Text | 音訊轉錄 |
藉由使用音訊產生功能,您可以達成更動態和互動式的 AI 應用程式。 支援音訊輸入和輸出的模型可讓您產生提示的語音回應,並使用音訊輸入來提示模型。
支援的模型
目前只有 gpt-4o-audio-preview 版本: 2024-12-17 支援音訊產生。
此gpt-4o-audio-preview模型適用於美國東部 2 和瑞典中部地區的全域部署。
目前支援音訊輸出的下列聲音:合金、Echo 和填充器。
音訊檔案大小上限為 20 MB。
注意
即時 API 會使用與完成 API 相同的基礎 GPT-4o 音訊模型,但已針對低延遲、即時音訊互動進行優化。
API 支援
第一次在 API 版本中 2025-01-01-preview新增對音訊完成的支援。
必要條件
- Azure 訂用帳戶 - 建立免費帳戶
- Node.js LTS 或 ESM 支援。
- TypeScript 會全域安裝。
- 在美國東部 2 或瑞典中部區域建立的 Azure OpenAI 資源。 請參閱區域可用性 (英文)。
- 然後,您必須使用 Azure OpenAI 資源來部署
gpt-4o-audio-preview模型。 如需詳細資訊,請參閱使用 Azure OpenAI 建立資源及部署模型。
Microsoft Entra ID 必要條件
針對具有 Microsoft Entra ID 的建議無金鑰驗證,您需要:
- 使用 Microsoft Entra ID 安裝用於無密鑰驗證的 Azure CLI。
- 將
Cognitive Services User角色指派給您的使用者帳戶。 您可以在存取控制 (IAM)>的 [新增角色指派] 底下的 Azure 入口網站 中指派角色。
設定
使用下列命令,建立新資料夾
audio-completions-quickstart以包含應用程式,並在該資料夾中開啟 Visual Studio Code:mkdir audio-completions-quickstart && code audio-completions-quickstartpackage.json使用下列指令建立 :npm init -ypackage.json使用下列命令將更新為 ECMAScript:npm pkg set type=module使用下列專案安裝適用於 JavaScript 的 OpenAI 用戶端連結庫:
npm install openai如需使用 Microsoft Entra ID 的建議 無金鑰驗證,請使用下列專案安裝
@azure/identity套件:npm install @azure/identity
擷取資源資訊
您需要擷取下列資訊,以向 Azure OpenAI 資源驗證您的應用程式:
| 變數名稱 | 值 |
|---|---|
AZURE_OPENAI_ENDPOINT |
在 Azure 入口網站查看資源時,您可以在 [金鑰和端點] 區段中找到此值。 |
AZURE_OPENAI_DEPLOYMENT_NAME |
此值會對應至您在部署模型時為部署選擇的自訂名稱。 您可以在 Azure 入口網站 中的資源管理>模型部署下找到此值。 |
OPENAI_API_VERSION |
深入瞭解 API 版本。 |
警告
若要搭配 SDK 使用建議的無密鑰驗證,請確定 AZURE_OPENAI_API_KEY 未設定環境變數。
從文字輸入產生音訊
to-audio.ts使用下列程式代碼建立檔案:import { writeFileSync } from "node:fs"; import { AzureOpenAI } from "openai/index.mjs"; import { DefaultAzureCredential, getBearerTokenProvider, } from "@azure/identity"; // Set environment variables or edit the corresponding values here. const endpoint: string = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion: string = "2025-01-01-preview"; const deployment: string = "gpt-4o-audio-preview"; // Keyless authentication const getClient = (): AzureOpenAI => { const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); const client = new AzureOpenAI({ endpoint: endpoint, apiVersion: apiVersion, azureADTokenProvider, }); return client; }; const client = getClient(); async function main(): Promise<void> { // Make the audio chat completions request const response = await client.chat.completions.create({ model: "gpt-4o-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: [ { role: "user", content: "Is a golden retriever a good family dog?" } ] }); // Inspect returned data console.log(response.choices[0]); // Write the output audio data to a file if (response.choices[0].message.audio) { writeFileSync( "dog.wav", Buffer.from(response.choices[0].message.audio.data, 'base64'), { encoding: "utf-8" } ); } else { console.error("Audio data is null or undefined."); } } main().catch((err: Error) => { console.error("Error occurred:", err); }); export { main };建立檔案
tsconfig.json以轉譯 TypeScript 程式代碼,並複製 ECMAScript 的下列程式代碼。{ "compilerOptions": { "module": "NodeNext", "target": "ES2022", // Supports top-level await "moduleResolution": "NodeNext", "skipLibCheck": true, // Avoid type errors from node_modules "strict": true // Enable strict type-checking options }, "include": ["*.ts"] }從 TypeScript 轉譯為 JavaScript。
tsc使用下列命令登入 Azure:
az login使用下列命令執行程式碼:
node to-audio.js
請稍候片刻以取得回應。
從文字輸入產生音訊的輸出
腳本會在與腳本相同的目錄中產生名為 dog.wav 的音訊檔案。 音訊檔案包含提示的口語回應:「黃金擷取器是好家庭狗嗎?
從音訊輸入產生音訊和文字
from-audio.ts使用下列程式代碼建立檔案:import { AzureOpenAI } from "openai"; import { writeFileSync } from "node:fs"; import { promises as fs } from 'fs'; import { DefaultAzureCredential, getBearerTokenProvider, } from "@azure/identity"; // Set environment variables or edit the corresponding values here. const endpoint: string = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion: string = "2025-01-01-preview"; const deployment: string = "gpt-4o-audio-preview"; // Keyless authentication const getClient = (): AzureOpenAI => { const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); const client = new AzureOpenAI({ endpoint: endpoint, apiVersion: apiVersion, azureADTokenProvider, }); return client; }; const client = getClient(); async function main(): Promise<void> { // Buffer the audio for input to the chat completion const wavBuffer = await fs.readFile("dog.wav"); const base64str = Buffer.from(wavBuffer).toString("base64"); // Make the audio chat completions request const response = await client.chat.completions.create({ model: "gpt-4o-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: [ { role: "user", content: [ { type: "text", text: "Describe in detail the spoken audio input." }, { type: "input_audio", input_audio: { data: base64str, format: "wav" } } ] } ] }); console.log(response.choices[0]); // Write the output audio data to a file if (response.choices[0].message.audio) { writeFileSync("analysis.wav", Buffer.from(response.choices[0].message.audio.data, 'base64'), { encoding: "utf-8" }); } else { console.error("Audio data is null or undefined."); } } main().catch((err: Error) => { console.error("Error occurred:", err); }); export { main };建立檔案
tsconfig.json以轉譯 TypeScript 程式代碼,並複製 ECMAScript 的下列程式代碼。{ "compilerOptions": { "module": "NodeNext", "target": "ES2022", // Supports top-level await "moduleResolution": "NodeNext", "skipLibCheck": true, // Avoid type errors from node_modules "strict": true // Enable strict type-checking options }, "include": ["*.ts"] }從 TypeScript 轉譯為 JavaScript。
tsc使用下列命令登入 Azure:
az login使用下列命令執行程式碼:
node from-audio.js
請稍候片刻以取得回應。
從音訊輸入產生音訊和文字的輸出
腳本會產生口語音頻輸入摘要的文字記錄。 它也會在與腳本相同的目錄中產生名為 analysis.wav 的音訊檔案。 音訊檔案包含提示的語音回應。
產生音訊並使用多回合聊天完成
multi-turn.ts使用下列程式代碼建立檔案:import { AzureOpenAI } from "openai/index.mjs"; import { promises as fs } from 'fs'; import { ChatCompletionMessageParam } from "openai/resources/index.mjs"; import { DefaultAzureCredential, getBearerTokenProvider, } from "@azure/identity"; // Set environment variables or edit the corresponding values here. const endpoint: string = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion: string = "2025-01-01-preview"; const deployment: string = "gpt-4o-audio-preview"; // Keyless authentication const getClient = (): AzureOpenAI => { const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); const client = new AzureOpenAI({ endpoint: endpoint, apiVersion: apiVersion, azureADTokenProvider, }); return client; }; const client = getClient(); async function main(): Promise<void> { // Buffer the audio for input to the chat completion const wavBuffer = await fs.readFile("dog.wav"); const base64str = Buffer.from(wavBuffer).toString("base64"); // Initialize messages with the first turn's user input const messages: ChatCompletionMessageParam[] = [ { role: "user", content: [ { type: "text", text: "Describe in detail the spoken audio input." }, { type: "input_audio", input_audio: { data: base64str, format: "wav" } } ] } ]; // Get the first turn's response const response = await client.chat.completions.create({ model: "gpt-4o-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: messages }); console.log(response.choices[0]); // Add a history message referencing the previous turn's audio by ID messages.push({ role: "assistant", audio: response.choices[0].message.audio ? { id: response.choices[0].message.audio.id } : undefined }); // Add a new user message for the second turn messages.push({ role: "user", content: [ { type: "text", text: "Very concisely summarize the favorability." } ] }); // Send the follow-up request with the accumulated messages const followResponse = await client.chat.completions.create({ model: "gpt-4o-audio-preview", messages: messages }); console.log(followResponse.choices[0].message.content); } main().catch((err: Error) => { console.error("Error occurred:", err); }); export { main };建立檔案
tsconfig.json以轉譯 TypeScript 程式代碼,並複製 ECMAScript 的下列程式代碼。{ "compilerOptions": { "module": "NodeNext", "target": "ES2022", // Supports top-level await "moduleResolution": "NodeNext", "skipLibCheck": true, // Avoid type errors from node_modules "strict": true // Enable strict type-checking options }, "include": ["*.ts"] }從 TypeScript 轉譯為 JavaScript。
tsc使用下列命令登入 Azure:
az login使用下列命令執行程式碼:
node multi-turn.js
請稍候片刻以取得回應。
多回合聊天完成的輸出
腳本會產生口語音頻輸入摘要的文字記錄。 然後,它會進行多回合聊天完成,以簡短摘要口語音頻輸入。
清除資源
如果您想要清除和移除 Azure OpenAI 資源,可以刪除資源。 刪除資源之前,您必須先刪除任何已部署的模型。