Azure HDInsight 中 Apache Spark 叢集上的 Jupyter Notebook 核心
HDInsight Spark 叢集提供的核心,可讓您用於 Apache Spark 上的 Jupyter Notebook 以測試應用程式。 核心是一個可執行並解譯程式碼的程式。 三個核心為︰
- PySpark - 適用於以 Python2 撰寫的應用程式。 (僅適用於 Spark 2.4 版叢集)
- PySpark3 - 適用於以 Python3 撰寫的應用程式。
- Spark - 適用於以 Scala 撰寫的應用程式。
在本文中,您將了解使用這些核心的方式及優點。
必要條件
HDInsight 中的 Apache Spark 叢集。 如需指示,請參閱在 Azure HDInsight 中建立 Apache Spark 叢集。
在 Spark HDInsight 上建立 Jupyter Notebook
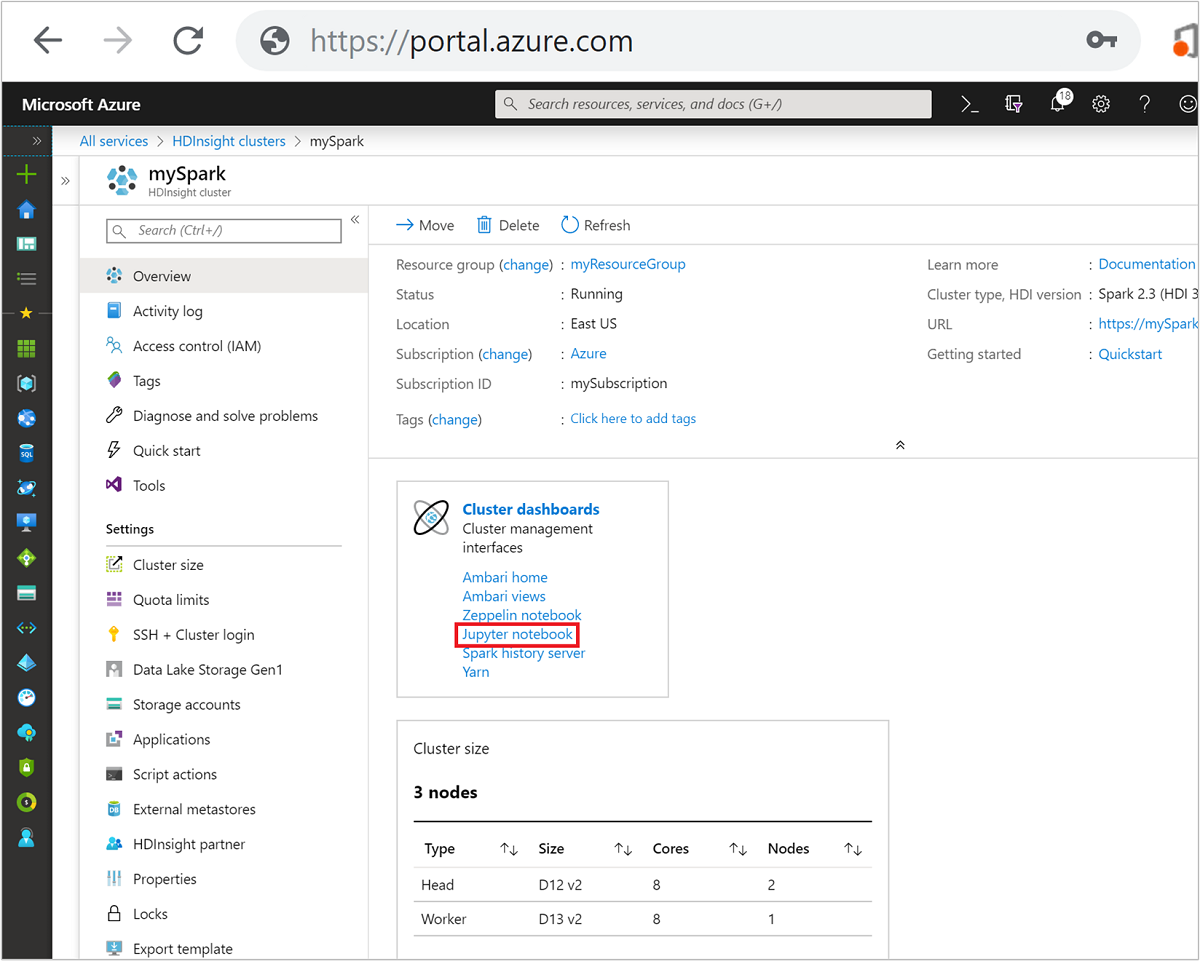
從 Azure 入口網站中,選取您的 Spark 叢集。 請參閱列出和顯示叢集以取得指示。 [概觀] 檢視隨即開啟。
從 [概觀] 檢視的 [叢集儀表板] 方塊中,選取 [Jupyter Notebook]。 出現提示時,輸入叢集的系統管理員認證。
注意
您也可以在瀏覽器中開啟下列 URL,來觸達 Spark 叢集上的 Jupyter Notebook。 使用您叢集的名稱取代 CLUSTERNAME :
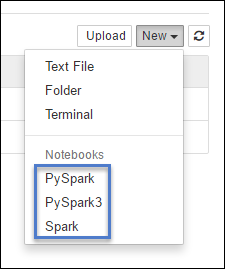
https://CLUSTERNAME.azurehdinsight.net/jupyter選取 [新增],然後選取 [Pyspark]、[PySpark3] 或 [Spark] 來建立 Notebook。 使用適用於 Scala 應用程式的 Spark 核心、適用於 Python2 應用程式的 PySpark 核心,以及適用於 Python3 應用程式的 PySpark3 核心。
注意
若為 Spark 3.1,只有 PySpark3 或 Spark 可供使用。
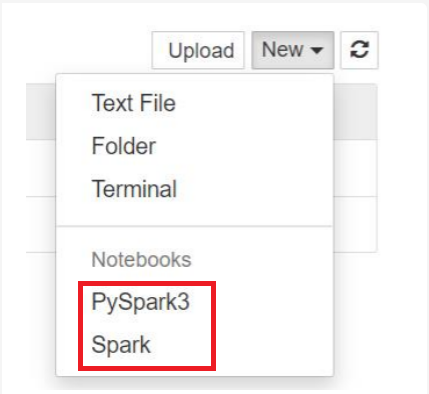
- 將以您選取的核心開啟 Notebook。
使用這些核心的優點
以下是在 Spark HDInsight 叢集上使用新的核心搭配 Jupyter Notebook 的幾個優點。
預設內容。 使用 PySpark、Spark3 或 Spark 核心時,您不需要先明確地設定 Spark 或 Hive 內容,即可開始處理您的應用程式。 這些內容預設為可用。 這些內容包括:
sc - 代表 Spark 內容
sqlContext - 代表 Hive 內容
因此,您「不」需要執行如下的陳述式來設定這些內容:
sc = SparkContext('yarn-client') sqlContext = HiveContext(sc)您可以直接在您的應用程式中使用現有的內容。
Cell magic。 PySpark 核心提供一些預先定義的 "magic",這是您可以使用
%%呼叫的特殊命令 (例如%%MAGIC<args>)。 magic 命令必須是程式碼儲存格中的第一個字,而且允許多行的內容。 magic 這個字應該是儲存格中的第一個字。 在 magic 前面加入任何項目,甚至是註解,將會造成錯誤。 如需 magic 的詳細資訊,請參閱 這裡。下表列出透過核心而提供的不同 magic。
Magic 範例 描述 說明 %%help產生所有可用 magic 的表格,其中包含範例與說明 info %%info輸出目前 Livy 端點的工作階段資訊 設定 %%configure -f{"executorMemory": "1000M"+"executorCores": 4+設定用來建立工作階段的參數。 如果已建立工作階段,則強制旗標 ( -f) 是必要的,可確保卸除並重新建立該工作階段。 如需有效參數的清單,請查看 Livy 的 POST /sessions 要求本文 。 參數必須以 JSON 字串傳遞,且必須在 magic 之後的下一行,如範例資料行中所示。sql %%sql -o <variable name>
SHOW TABLES針對 sqlContext 執行 Hive 查詢。 如果傳遞 -o參數,則查詢的結果會當做 Pandas 資料框架,保存在 %%local Python 內容中。本機 %%locala=1稍後幾行的程式碼全部在本機執行。 無論您使用哪個核心,程式碼都必須是有效的 Python2 程式碼。 因此,即使您在建立 Notebook 時選取 PySpark3 或 Spark 核心,如果您在資料格中使用核心 %%localmagic,則該資料格只能包含有效的 Python2 程式碼。記錄 %%logs輸出目前 Livy 工作階段的記錄。 delete %%delete -f -s <session number>刪除目前 Livy 端點的特定工作階段。 您無法刪除針對核心本身啟動的工作階段。 cleanup %%cleanup -f刪除目前 Livy 端點的所有工作階段,包括此 Notebook 的工作階段。 force 旗標 -f 是必要的。 注意
除了 PySpark 核心所新增的 Magic,您也可以使用內建的 IPython Magic (包括
%%sh)。 您可以使用%%shMagic,在叢集前端節點上執行指令碼和程式碼區塊。自動視覺化。 Pyspark 核心會自動將 Hive 和 SQL 查詢的輸出視覺化。 有數種不同類型的視覺效果供您選擇,包括資料表、圓形圖、線條、區域、長條圖。
%%sql magic 支援的參數
%%sql magic 支援不同的參數,可用來控制您執行查詢時收到的輸出類型。 下表列出輸出。
| 參數 | 範例 | 描述 |
|---|---|---|
| -o | -o <VARIABLE NAME> |
使用此參數,在 %%local Python 內容中保存查詢的結果,以做為 Pandas 資料框架。 資料框架變數的名稱是您指定的變數名稱。 |
| -q | -q |
使用此參數來關閉儲存格的視覺效果。 如果您不想自動將儲存格內容視覺化,而且只想擷取該內容作為資料框架,則請使用 -q -o <VARIABLE>。 如果您想要關閉視覺化功能而不擷取結果 (例如,執行 SQL 查詢的 CREATE TABLE 陳述式),請使用 -q 但不要指定 -o 引數。 |
| -m | -m <METHOD> |
其中 METHOD 是 take 或 sample (預設值是 take)。 如果方法是 take,則核心會從 MAXROWS 指定的結果資料集頂端挑選項目 (如此表稍後所述)。 如果方法是 sample,核心會根據 -r 參數隨機取樣資料集的項目,如此表稍後所述。 |
| -r | -r <FRACTION> |
這裡的 FRACTION 是介於 0.0 到 1.0 之間的浮點數。 如果 SQL 查詢的範例方法是 sample,則核心會為您從結果集隨機取樣指定比例的項目。 例如,如果您使用 -m sample -r 0.01 引數執行 SQL 查詢,則會隨機取樣 1% 的結果資料列。 |
| -n | -n <MAXROWS> |
MAXROWS 是整數值。 核心會將輸出資料列的數目限制為 MAXROWS。 如果 MAXROWS 是負數 (例如 -1),則結果集中的資料列數目不會受到限制。 |
範例:
%%sql -q -m sample -r 0.1 -n 500 -o query2
SELECT * FROM hivesampletable
上面的陳述式會執行下列動作:
- 從 hivesampletable選取所有記錄。
- 因為我們使用 -q,所以會關閉自動視覺效果。
- 因為我們使用
-m sample -r 0.1 -n 500,所以會從 hivesampletable 的資料列中隨機取樣 10%,並將結果集的大小限制為 500 個資料列。 - 最後,因為我們使用
-o query2,所以它也會將輸出儲存成名為 query2的資料框架。
使用新核心的考量
無論您使用何種核心,讓 Notebook 持續執行會耗用叢集資源。 針對這些核心,因為已預設內容,所以僅結束 Notebook 並不會終止內容。 因此會繼續使用叢集資源。 理想的作法是當 Notebook 使用完畢時,從 Notebook 的 [檔案] 功能表中使用 [關閉並終止] 選項。 這項關閉會先刪除內容,然後結束 Notebook。
Notebook 會儲存在哪裡?
如果您的叢集使用 Azure 儲存體作為預設的儲存體帳戶,則 Jupyter Notebook 會儲存在儲存體帳戶的 /HdiNotebooks 資料夾下。 您從 Jupyter 內建立的 Notebook、文字檔案和資料夾,都可從儲存體帳戶存取。 例如,如果您使用 Jupyter 建立資料夾 myfolder 和 Notebook myfolder/mynotebook.ipynb,則可以在儲存體帳戶內的 /HdiNotebooks/myfolder/mynotebook.ipynb 存取該 Notebook。 反之亦然,也就是說,如果您直接將 Notebook 上傳至儲存體帳戶的 /HdiNotebooks/mynotebook1.ipynb,則從 Jupyter 也能看到該 Notebook。 即使在刪除叢集之後,Notebook 仍會保留在儲存體帳戶中。
注意
使用 Azure Data Lake Store 作為預設儲存體帳戶的 HDInsight 叢集,不會在相關聯的儲存體中儲存筆記本。
將 Notebook 儲存到儲存體帳戶的方式與 Apache Hadoop HDFS 相容。 如果您使用 SSH 連線至叢集,則可以使用檔案管理命令:
| Command | 描述 |
|---|---|
hdfs dfs -ls /HdiNotebooks |
# 列出根目錄中的所有項目 – Jupyter 可以從首頁看到此目錄中的所有項目 |
hdfs dfs –copyToLocal /HdiNotebooks |
# 下載 HdiNotebooks 資料夾的內容 |
hdfs dfs –copyFromLocal example.ipynb /HdiNotebooks |
# 將 Notebook example.ipynb 上傳至根資料夾,使其可從 Jupyter 看見 |
無論叢集是使用 Azure 儲存體還是 Azure Data Lake Store 作為預設儲存體帳戶,筆記本也會儲存在叢集前端節點的 /var/lib/jupyter 上。
支援的瀏覽器
Google Chrome 上只支援 Spark HDInsight 叢集上的 Jupyter Notebook。
建議
新的核心已在發展階段,而且經過一段時間後將會成熟。 因此,API 可能會隨著這些核心的成熟而變更。 您在使用這些新核心時如有任何意見,我們都非常樂於知道。 此意見反應對於這些核心最終版本的定調很有幫助。 您可以將您的評論/意見反應填寫在本文最後的〈意見反應〉一節下方。