排查 SQL Server 中窄和宽计划的 UPDATE 性能问题
适用范围:SQL Server
UPDATE在某些情况下,语句的速度可能更快,而其他语句则较慢。 有许多因素可能导致此类差异,包括更新的行数以及系统上的资源使用情况(阻塞、CPU、内存或 I/O)。 本文将介绍差异的一个具体原因:SQL Server 选择查询计划。
什么是狭窄和宽阔的计划?
针对聚集索引列执行 UPDATE 语句时,SQL Server 不仅会更新聚集索引本身,而且更新所有非聚集索引,因为非聚集索引包含群集索引键。
SQL Server 有两个选项可用于执行更新:
窄计划:执行非聚集索引更新以及聚集索引密钥更新。 这种简单的方法易于理解;更新聚集索引,然后同时更新所有非聚集索引。 SQL Server 将更新一行并移动到下一行,直到全部完成。 此方法称为窄计划更新或每行更新。 但是,此操作相对昂贵,因为将更新的非聚集索引数据的顺序可能不是聚集索引数据的顺序。 如果更新中涉及许多索引页,则当数据位于磁盘上时,可能会出现大量的随机 I/O 请求。
宽计划:为了优化性能并减少随机 I/O,SQL Server 可以选择一个宽计划。 它不会同时更新非聚集索引以及聚集索引更新。 相反,它会先对内存中的所有非聚集索引数据进行排序,然后按该顺序更新所有索引。 此方法称为宽计划(也称为每索引更新)。
下面是窄和宽计划的屏幕截图:

SQL Server 何时选择宽计划?
SQL Server 必须满足两个条件才能选择宽计划:
- 受影响的行数大于 250。
- 非聚集索引(索引页计数 * 8 KB)的叶级别大小至少为最大服务器内存设置的 1/1000。
狭窄和宽阔的计划如何工作?
若要了解窄和宽计划的工作原理,请按照以下环境中的步骤操作:
- SQL Server 2019 CU11
- 最大服务器内存 = 1,500 MB
运行以下脚本,创建一个表,该表
mytable1分别包含 41,501 行、列上的一个聚集索引c1和其余列的五个非聚集索引。CREATE TABLE mytable1(c1 INT,c2 CHAR(30),c3 CHAR(20),c4 CHAR(30),c5 CHAR(30)) GO WITH cte AS ( SELECT ROW_NUMBER() OVER(ORDER BY c1.object_id) id FROM sys.columns CROSS JOIN sys.columns c1 ) INSERT mytable1 SELECT TOP 41000 id,REPLICATE('a',30),REPLICATE('a',20),REPLICATE('a',30),REPLICATE('a',30) FROM cte GO INSERT mytable1 SELECT TOP 250 50000,c2,c3,c4,c5 FROM mytable1 GO INSERT mytable1 SELECT TOP 251 50001,c2,c3,c4,c5 FROM mytable1 GO CREATE CLUSTERED INDEX ic1 ON mytable1(c1) CREATE INDEX ic2 ON mytable1(c2) CREATE INDEX ic3 ON mytable1(c3) CREATE INDEX ic4 ON mytable1(c4) CREATE INDEX ic5 ON mytable1(c5)运行以下三个 T-SQL
UPDATE语句,并比较查询计划:UPDATE mytable1 SET c1=c1 WHERE c1=1 OPTION(RECOMPILE)- 更新了一行UPDATE mytable1 SET c1=c1 WHERE c1=50000 OPTION(RECOMPILE)- 更新了 250 行。UPDATE mytable1 SET c1=c1 WHERE c1=50001 OPTION(RECOMPILE)- 更新了 251 行。
根据第一个条件检查结果(受影响行数的阈值为 250)。
以下屏幕截图显示基于第一个条件的结果:

如预期所示,查询优化器为前两个查询选择一个窄计划,因为受影响的行数小于 250。 宽计划用于第三个查询,因为受影响的行计数为 251,大于 250。
根据第二个条件检查结果(叶索引大小的内存至少为最大服务器内存设置的 1/1000)。
以下屏幕截图显示了基于第二个条件的结果:
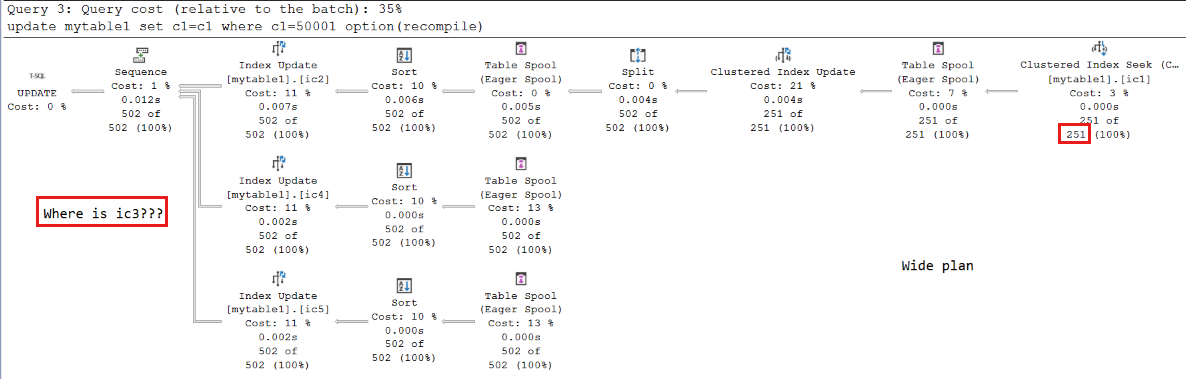
为第三
UPDATE个查询选择了宽计划。 但计划中没有看到索引ic3(列c3)。 出现此问题的原因是不符合第二个条件 - 与设置最大服务器内存相比的叶页索引大小。列
c2的数据类型,c4并且c4是char(30)列c3的数据类型。char(20)每行索引ic3的大小小于其他行,因此叶页数小于其他页数。借助动态管理功能(DMF),
sys.dm_db_database_page_allocations可以计算每个索引的页数。 对于索引ic2ic4,每个ic5索引有 214 页,其中 209 个是叶页(结果可能略有不同)。 叶页使用的内存为 209 x 8 = 1,672 KB。 因此,比率为 1672/(1500 x 1024) = 0.00108854101,大于 1/1000。 但是,ic3只有 161 页;其中 159 个是叶页。 比率为 159 x 8/(1500 x 1024) = 0.000828125,小于 1/1000 (0.001)。如果插入更多行或减少 最大服务器内存 以满足条件,计划将更改。 若要使索引叶级大小大于 1/1000,可以通过运行以下命令将最大服务器内存设置降到 1,200:
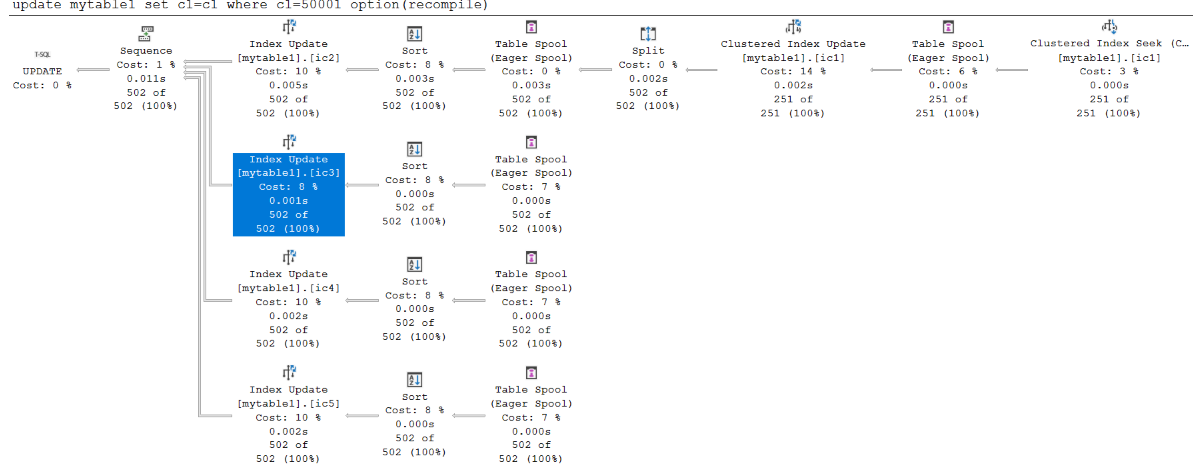
sp_configure 'show advanced options', 1; GO RECONFIGURE; GO sp_configure 'max server memory', 1200; GO RECONFIGURE GO UPDATE mytable1 SET c1=c1 WHERE c1=50001 OPTION(RECOMPILE) --251 rows are updated.在这种情况下,159 x 8/(1200 x 1024) = 0.00103515625 > 1/1000。 此更改后,该计划
ic3中会显示。有关详细信息
show advanced options,请参阅 使用 Transact-SQL。以下屏幕截图显示达到内存阈值时,宽计划使用所有索引:



宽计划比窄计划快吗?
答案是,这取决于数据页和索引页是否缓存在缓冲池中。
数据缓存在缓冲池中
如果数据已在缓冲池中,则与窄计划相比,具有宽计划的查询不一定提供额外的性能优势,因为宽计划旨在提高 I/O 性能(物理读取,而不是逻辑读取)。
若要在数据位于缓冲池中时测试宽计划是否比窄计划快,请按照以下环境中的步骤操作:
SQL Server 2019 CU11
最大服务器内存:30,000 MB
数据大小为 64 MB,而索引大小约为 127 MB。
数据库文件位于两个不同的物理磁盘上:
- I:\sql19\dbWideplan.mdf
- H:\sql19\dbWideplan.ldf
通过运行以下命令创建另一个表
mytable2:CREATE TABLE mytable2(C1 INT,C2 INT,C3 INT,C4 INT,C5 INT) GO CREATE CLUSTERED INDEX IC1 ON mytable2(C1) CREATE INDEX IC2 ON mytable2(C2) CREATE INDEX IC3 ON mytable2(C3) CREATE INDEX IC4 ON mytable2(C4) CREATE INDEX IC5 ON mytable2(C5) GO DECLARE @N INT=1 WHILE @N<1000000 BEGIN DECLARE @N1 INT=RAND()*4500 DECLARE @N2 INT=RAND()*100000 DECLARE @N3 INT=RAND()*100000 DECLARE @N4 INT=RAND()*100000 DECLARE @N5 INT=RAND()*100000 INSERT mytable2 VALUES(@N1,@N2,@N3,@N4,@N5) SET @N+=1 END GO UPDATE STATISTICS mytable2 WITH FULLSCAN执行以下两个查询来比较查询计划:
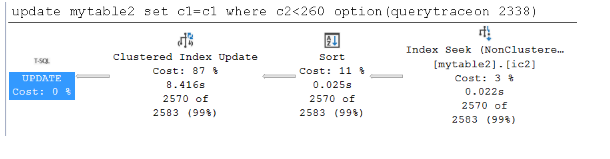
update mytable2 set c1=c1 where c2<260 option(querytraceon 8790) --trace flag 8790 will force Wide plan update mytable2 set c1=c1 where c2<260 option(querytraceon 2338) --trace flag 2338 will force Narrow plan有关详细信息,请参阅跟踪标志 8790 和跟踪标志 2338。
具有宽计划的查询需要 0.136 秒,而具有窄计划的查询只需 0.112 秒。 这两个持续时间非常接近,并且 Per-Index 更新(宽计划)不太有利,因为在执行语句之前
UPDATE,数据已在缓冲区中。以下屏幕截图显示了缓冲池中缓存数据时的宽和窄计划:


数据不会缓存在缓冲池中
若要在数据不在缓冲池中时测试宽计划是否快于窄计划,请运行以下查询:
注意
执行测试时,请确保你是唯一的 SQL Server 工作负载,并且磁盘专用于 SQL Server。
CHECKPOINT
GO
DBCC DROPCLEANBUFFERS
GO
WAITFOR DELAY '00:00:02' --wait for 1~2 seconds
UPDATE mytable2 SET c1=c1 WHERE c2 < 260 OPTION (QUERYTRACEON 8790) --force Wide plan
CHECKPOINT
GO
DBCC DROPCLEANBUFFERS
GO
WAITFOR DELAY '00:00:02' --wait for 1~2 SECONDS
UPDATE mytable2 SET c1=c1 WHERE c2 < 260 OPTION (QUERYTRACEON 2338) --force Narrow plan
具有宽计划的查询需要 3.554 秒,而具有窄计划的查询需要 6.701 秒。 此时间,宽计划查询运行速度更快。
以下屏幕截图显示了缓冲池中未缓存数据时的宽计划:

以下屏幕截图显示了缓冲池中未缓存数据时的窄计划:
如果数据不在缓冲区中,宽计划查询总是比窄查询计划快吗?
答案是“并不总是”。若要在数据不在缓冲区中时测试宽计划查询是否始终比窄查询计划快,请执行以下步骤:
通过运行以下命令创建另一个表
mytable2:SELECT c1,c1 AS c2,c1 AS C3,c1 AS c4,c1 AS C5 INTO mytable3 FROM mytable2 GO CREATE CLUSTERED INDEX IC1 ON mytable3(C1) CREATE INDEX IC2 ON mytable3(C2) CREATE INDEX IC3 ON mytable3(C3) CREATE INDEX IC4 ON mytable3(C4) CREATE INDEX IC5 ON mytable3(C5) GO这
mytable3与mytable2数据不同。mytable3具有具有相同值的所有五列,这使得非聚集索引的顺序遵循聚集索引的顺序。 这种数据排序将最大程度地减少宽计划的优势。执行以下命令来比较查询计划:
CHECKPOINT GO DBCC DROPCLEANBUFFERS go UPDATE mytable3 SET c1=c1 WHERE c2<12 OPTION(QUERYTRACEON 8790) --tf 8790 will force Wide plan CHECKPOINT GO DBCC DROPCLEANBUFFERS GO UPDATE mytable3 SET c1=c1 WHERE c2<12 OPTION(QUERYTRACEON 2338) --tf 2338 will force Narrow plan这两个查询的持续时间显著减少! 宽计划需要 0.304 秒,这比这次窄计划要慢一点。
以下屏幕截图显示了使用宽和窄时性能的比较:


应用宽计划的方案
下面是应用宽计划的其他方案:
聚集索引列具有唯一或主键,并且更新了多行
下面是重现方案的示例:
CREATE TABLE mytable4(c1 INT primary key,c2 INT,c3 INT,c4 INT)
GO
CREATE INDEX ic2 ON mytable4(c2)
CREATE INDEX ic3 ON mytable4(c3)
CREATE INDEX ic4 ON mytable4(c4)
GO
INSERT mytable4 VALUES(0,0,0,0)
INSERT mytable4 VALUES(1,1,1,1)
以下屏幕截图显示群集索引具有唯一键时使用宽计划:

有关更多详细信息,请查看 维护唯一索引。
群集索引列是在分区方案中指定的
下面是重现方案的示例:
CREATE TABLE mytable5(c1 INT,c2 INT,c3 INT,c4 INT)
GO
IF EXISTS (SELECT * FROM sys.partition_schemes WHERE name='PS1')
DROP PARTITION SCHEME PS1
GO
IF EXISTS (SELECT * FROM sys.partition_functions WHERE name='PF1')
DROP PARTITION FUNCTION PF1
GO
CREATE PARTITION FUNCTION PF1(INT) AS
RANGE right FOR VALUES
(2000)
GO
CREATE PARTITION SCHEME PS1 AS
PARTITION PF1 all TO
([PRIMARY])
GO
CREATE CLUSTERED INDEX c1 ON mytable5(c1) ON PS1(c1)
CREATE INDEX c2 ON mytable5(c2)
CREATE INDEX c3 ON mytable5(c3)
CREATE INDEX c4 ON mytable5(c4)
GO
UPDATE mytable5 SET c1=c1 WHERE c1=1
以下屏幕截图显示了分区方案中存在聚集列时使用宽计划:

聚集索引列不属于分区方案,并且已更新分区方案列
下面是重现方案的示例:
CREATE TABLE mytable6(c1 INT,c2 INT,c3 INT,c4 INT)
GO
IF EXISTS (SELECT * FROM sys.partition_schemes WHERE name='PS2')
DROP PARTITION SCHEME PS2
GO
IF EXISTS (SELECT * FROM sys.partition_functions WHERE name='PF2')
DROP PARTITION FUNCTION PF2
GO
CREATE PARTITION FUNCTION PF2(int) AS
RANGE right FOR VALUES
(2000)
GO
CREATE PARTITION SCHEME PS2 AS
PARTITION PF2 all TO
([PRIMARY])
GO
CREATE CLUSTERED INDEX c1 ON mytable6(c1) ON PS2(c2) --on c2 column
CREATE INDEX c3 ON mytable6(c3)
CREATE INDEX c4 ON mytable6(c4)
以下屏幕截图显示更新分区方案列时使用宽计划:
