排查 SQL Server 中的高 CPU 使用率问题
适用范围:SQL Server
本文提供了诊断和修复运行 Microsoft SQL Server 的计算机上 CPU 使用率过高导致的问题的过程。 尽管 SQL Server 上的 CPU 使用率过高有许多可能的原因,但以下原因最为常见:
- 由于以下条件,表或索引扫描导致的逻辑读取较高:
- 过期统计信息
- 缺失索引
- 参数敏感计划 (PSP) 问题
- 查询设计不佳
- 工作负载增加
可以使用以下步骤来排查 SQL Server 中 CPU 使用率过高的问题。
步骤 1:验证 SQL Server 是否导致 CPU 使用率过高
使用以下工具之一检查 SQL Server 进程是否确实导致 CPU 使用率过高:
任务管理器:在“进程”选项卡上,检查 SQL Server Windows NT-64 位的 CPU 列值是否接近 100%。
-
- 计数器:
Process/%User Time,% Privileged Time - 实例:sqlservr
- 计数器:
可以使用以下 PowerShell 脚本在 60 秒的跨度内收集计数器数据:
$serverName = $env:COMPUTERNAME $Counters = @( ("\\$serverName" + "\Process(sqlservr*)\% User Time"), ("\\$serverName" + "\Process(sqlservr*)\% Privileged Time") ) Get-Counter -Counter $Counters -MaxSamples 30 | ForEach { $_.CounterSamples | ForEach { [pscustomobject]@{ TimeStamp = $_.TimeStamp Path = $_.Path Value = ([Math]::Round($_.CookedValue, 3)) } Start-Sleep -s 2 } }如果
% User Time始终大于 90%(% 用户时间是每个处理器上的处理器时间之和),则其最大值为 100% * (无 CPU),则 SQL Server 进程会导致 CPU 使用率过高。 但如果% Privileged time始终大于 90%,则是防病毒软件、其他驱动程序或计算机上的其他 OS 组件导致 CPU 使用率过高。 你应与系统管理员共同分析此行为的根本原因。性能仪表板:在 SQL Server Management Studio 中,右键单击 <SQLServerInstance> 并选择“ 报告>标准报表>性能仪表板”。
仪表板演示标题为 带条形图的系统 CPU 使用率 的图形。 较深的颜色表示 SQL Server 引擎 CPU 利用率,而较浅的颜色表示整个操作系统 CPU 使用率(请参阅图形上的图例以供参考)。 选择循环刷新按钮或 F5 以查看更新的利用率。
步骤 2:确定影响 CPU 使用率的查询
如果是 Sqlservr.exe 进程导致 CPU 使用率过高,则最常见的原因是执行表或索引扫描的 SQL Server 查询,其次是排序、哈希操作和循环(嵌套循环运算符或 WHILE (T-SQL))。 要了解查询当前在总 CPU 使用率中的占比,请运行以下语句:
DECLARE @init_sum_cpu_time int,
@utilizedCpuCount int
--get CPU count used by SQL Server
SELECT @utilizedCpuCount = COUNT( * )
FROM sys.dm_os_schedulers
WHERE status = 'VISIBLE ONLINE'
--calculate the CPU usage by queries OVER a 5 sec interval
SELECT @init_sum_cpu_time = SUM(cpu_time) FROM sys.dm_exec_requests
WAITFOR DELAY '00:00:05'
SELECT CONVERT(DECIMAL(5,2), ((SUM(cpu_time) - @init_sum_cpu_time) / (@utilizedCpuCount * 5000.00)) * 100) AS [CPU from Queries as Percent of Total CPU Capacity]
FROM sys.dm_exec_requests
若要确定当前负责高 CPU 活动的查询,请运行以下语句:
SELECT TOP 10 s.session_id,
r.status,
r.cpu_time,
r.logical_reads,
r.reads,
r.writes,
r.total_elapsed_time / (1000 * 60) 'Elaps M',
SUBSTRING(st.TEXT, (r.statement_start_offset / 2) + 1,
((CASE r.statement_end_offset
WHEN -1 THEN DATALENGTH(st.TEXT)
ELSE r.statement_end_offset
END - r.statement_start_offset) / 2) + 1) AS statement_text,
COALESCE(QUOTENAME(DB_NAME(st.dbid)) + N'.' + QUOTENAME(OBJECT_SCHEMA_NAME(st.objectid, st.dbid))
+ N'.' + QUOTENAME(OBJECT_NAME(st.objectid, st.dbid)), '') AS command_text,
r.command,
s.login_name,
s.host_name,
s.program_name,
s.last_request_end_time,
s.login_time,
r.open_transaction_count
FROM sys.dm_exec_sessions AS s
JOIN sys.dm_exec_requests AS r ON r.session_id = s.session_id CROSS APPLY sys.Dm_exec_sql_text(r.sql_handle) AS st
WHERE r.session_id != @@SPID
ORDER BY r.cpu_time DESC
如果查询目前未驱动 CPU,可以运行以下语句来查找历史占用大量 CPU 的查询:
SELECT TOP 10 qs.last_execution_time, st.text AS batch_text,
SUBSTRING(st.TEXT, (qs.statement_start_offset / 2) + 1, ((CASE qs.statement_end_offset WHEN - 1 THEN DATALENGTH(st.TEXT) ELSE qs.statement_end_offset END - qs.statement_start_offset) / 2) + 1) AS statement_text,
(qs.total_worker_time / 1000) / qs.execution_count AS avg_cpu_time_ms,
(qs.total_elapsed_time / 1000) / qs.execution_count AS avg_elapsed_time_ms,
qs.total_logical_reads / qs.execution_count AS avg_logical_reads,
(qs.total_worker_time / 1000) AS cumulative_cpu_time_all_executions_ms,
(qs.total_elapsed_time / 1000) AS cumulative_elapsed_time_all_executions_ms
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(sql_handle) st
ORDER BY(qs.total_worker_time / qs.execution_count) DESC
步骤 3:更新统计信息
在确定 CPU 占用最高的查询后,请更新这些查询使用的表的统计信息。 可以使用 sp_updatestats 系统存储过程更新当前数据库中所有用户定义表和内部表的统计信息。 例如:
exec sp_updatestats
注意
sp_updatestats 系统存储过程针对当前数据库中的所有用户定义表和内部表运行 UPDATE STATISTICS。 对于定期维护,请确保定期计划维护使统计信息保持最新。 使用自适应索引碎片整理等解决方案,自动管理一个或多个数据库的索引碎片整理和统计信息更新。 此过程根据碎片级别以及其他参数,自动选择是重新生成索引还是重新组织索引,并使用线性阈值更新统计信息。
有关 sp_updatestats 的更多信息,请参见 sp_updatestats。
如果 SQL Server 的 CPU 占用仍然过高,请前往下一步。
步骤 4:添加缺失索引
缺少索引可能导致运行速度较慢的查询和 CPU 使用率过高。 可以识别缺失的索引并创建这些索引,以改善这种性能影响。
运行以下查询以识别导致 CPU 使用率高且在查询计划中至少包含一个缺失索引的查询:
-- Captures the Total CPU time spent by a query along with the query plan and total executions SELECT qs_cpu.total_worker_time / 1000 AS total_cpu_time_ms, q.[text], p.query_plan, qs_cpu.execution_count, q.dbid, q.objectid, q.encrypted AS text_encrypted FROM (SELECT TOP 500 qs.plan_handle, qs.total_worker_time, qs.execution_count FROM sys.dm_exec_query_stats qs ORDER BY qs.total_worker_time DESC) AS qs_cpu CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS q CROSS APPLY sys.dm_exec_query_plan(plan_handle) p WHERE p.query_plan.exist('declare namespace qplan = "http://schemas.microsoft.com/sqlserver/2004/07/showplan"; //qplan:MissingIndexes')=1查看已标识查询的执行计划,并通过进行所需的更改来优化查询。 以下屏幕截图显示了一个示例,其中 SQL Server 将指出查询的缺失索引。 右键单击查询计划的“缺失索引”部分,然后选择“缺少索引详细信息”,在 SQL Server Management Studio 的另一个窗口中创建索引。
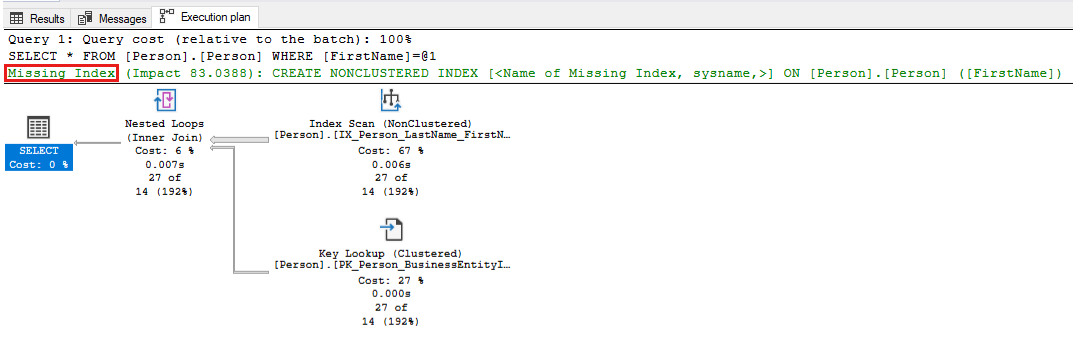
使用以下查询检查是否缺少索引,并应用具有高改进度量值的任何建议索引。 从输出中具有最高 improvement_measure 值的前 5 或 10 条建议开始。 这些索引对性能有最显著的积极影响。 确定是否要应用这些索引,并确保对应用程序进行了性能测试。 然后,继续应用缺失索引建议,直到获得所需的应用程序性能结果。 有关本主题的详细信息,请参阅优化包含缺失索引建议的非群集索引。
SELECT CONVERT(VARCHAR(30), GETDATE(), 126) AS runtime, mig.index_group_handle, mid.index_handle, CONVERT(DECIMAL(28, 1), migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans)) AS improvement_measure, 'CREATE INDEX missing_index_' + CONVERT(VARCHAR, mig.index_group_handle) + '_' + CONVERT(VARCHAR, mid.index_handle) + ' ON ' + mid.statement + ' (' + ISNULL(mid.equality_columns, '') + CASE WHEN mid.equality_columns IS NOT NULL AND mid.inequality_columns IS NOT NULL THEN ',' ELSE '' END + ISNULL(mid.inequality_columns, '') + ')' + ISNULL(' INCLUDE (' + mid.included_columns + ')', '') AS create_index_statement, migs.*, mid.database_id, mid.[object_id] FROM sys.dm_db_missing_index_groups mig INNER JOIN sys.dm_db_missing_index_group_stats migs ON migs.group_handle = mig.index_group_handle INNER JOIN sys.dm_db_missing_index_details mid ON mig.index_handle = mid.index_handle WHERE CONVERT (DECIMAL (28, 1), migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans)) > 10 ORDER BY migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans) DESC

步骤 5:调查并解决参数敏感型问题
可以使用 DBCC FREEPROCCACHE 命令释放计划缓存,并检查这是否解决了 CPU 使用率过高的问题。 如果问题已修复,则表示是参数敏感问题(PSP,也称为“参数探查问题”)。
注意
使用不带参数的 DBCC FREEPROCCACHE 将从计划缓存中删除所有已编译的计划。 这将导致再次编译新的查询执行,从而导致每个新查询的持续时间一次性延长。 最佳方法是使用 DBCC FREEPROCCACHE ( plan_handle | sql_handle ) 来识别导致问题的查询,然后解决单个查询或有问题的查询。
要解决此参数敏感问题,请使用以下方法。 每种方法都有相应的利弊。
使用 RECOMPILE 查询提示。 可以向步骤 2 中标识的一个或多个 CPU 过高查询添加
RECOMPILE查询提示。 此提示将使编译 CPU 使用率略微增加,有助于在与每个查询执行的更佳性能之间达到平衡。 有关详细信息,请参阅参数和执行计划重用、 参数敏感度和 RECOMPILE 查询提示。下面是如何将此提示应用到查询的示例。
SELECT * FROM Person.Person WHERE LastName = 'Wood' OPTION (RECOMPILE)使用 OPTIMIZE FOR 查询提示,使用包含数据中大多数值的更典型的参数值覆盖实际参数值。 此选项需要充分了解最佳参数值和关联的计划特征。 下面是如何在查询中使用此提示的示例。
DECLARE @LastName Name = 'Frintu' SELECT FirstName, LastName FROM Person.Person WHERE LastName = @LastName OPTION (OPTIMIZE FOR (@LastName = 'Wood'))使用优化未知查询提示,使用密度向量平均值覆盖实际参数值。 也可以通过捕获本地变量中的传入参数值,然后使用谓词中的本地变量而不是使用参数本身来执行此操作。 对于此修复,平均密度可能足以提供可接受的性能。
使用 DISABLE_PARAMETER_SNIFFING 查询提示,完全禁用参数探查。 下面是如何在查询中使用它的示例:
SELECT * FROM Person.Address WHERE City = 'SEATTLE' AND PostalCode = 98104 OPTION (USE HINT ('DISABLE_PARAMETER_SNIFFING'))使用 KEEPFIXED PLAN 查询提示,阻止在缓存中重新编译。 此解决方法假定“足够好”的常见计划是已在缓存中的计划。 还可以禁用统计信息自动更新,以减少逐出良好计划而编译新的不良计划的可能性。
将 DBCC FREEPROCCACHE 命令用作临时解决方案,直到应用程序代码修复为止。 可以使用
DBCC FREEPROCCACHE (plan_handle)命令仅删除导致问题的计划。 例如,若要查找引用 AdventureWorks 中Person.Person表的查询计划,可以使用此查询查找查询句柄。 然后,可以使用查询结果第二列中生成的DBCC FREEPROCCACHE (plan_handle),从缓存中释放特定查询计划。SELECT text, 'DBCC FREEPROCCACHE (0x' + CONVERT(VARCHAR (512), plan_handle, 2) + ')' AS dbcc_freeproc_command FROM sys.dm_exec_cached_plans CROSS APPLY sys.dm_exec_query_plan(plan_handle) CROSS APPLY sys.dm_exec_sql_text(plan_handle) WHERE text LIKE '%person.person%'
步骤 6:调查并解决 SARGability 问题
当 SQL Server 引擎可以使用索引查找来加快查询的执行时,查询中的谓词被视为可执行 SARG(搜索 ARGument 支持)。 许多查询设计会阻止 SARG 能力,并导致表或索引扫描以及 CPU 使用率过高。 请考虑 AdventureWorks 数据库的以下查询,其中必须检索每个 ProductNumber 并向其应用 SUBSTRING() 函数,然后再将其与字符串文本值进行比较。 可以看到,必须先提取表的所有行,然后应用函数,才能进行比较。 从表中提取所有行意味着扫描表或索引,这会导致更高的 CPU 使用率。
SELECT ProductID, Name, ProductNumber
FROM [Production].[Product]
WHERE SUBSTRING(ProductNumber, 0, 4) = 'HN-'
对搜索谓词中的列应用任何函数或计算通常会使查询不可执行 SARG,并导致 CPU 占用率增加。 解决方案通常包括以创造性的方式重写查询,从而可执行 SARG。 此示例的一个可能的解决方案是重写,其中从查询谓词中删除函数,搜索另一列并获得相同的结果:
SELECT ProductID, Name, ProductNumber
FROM [Production].[Product]
WHERE Name LIKE 'Hex%'
下面是另一个示例,销售经理可能希望为大额订单提供 10% 的销售佣金,并希望查看哪些订单的佣金将超过 300 美元。 这是合乎逻辑的,但非 sargable 的方法。
SELECT DISTINCT SalesOrderID, UnitPrice, UnitPrice * 0.10 [10% Commission]
FROM [Sales].[SalesOrderDetail]
WHERE UnitPrice * 0.10 > 300
下面是一个可能不太直观,但以 SARGable 重写查询的方法,其中计算将移动到谓词的另一边。
SELECT DISTINCT SalesOrderID, UnitPrice, UnitPrice * 0.10 [10% Commission]
FROM [Sales].[SalesOrderDetail]
WHERE UnitPrice > 300/0.10
SARGability 不仅适用于 WHERE 子句,也适用于 JOINs、HAVING、GROUP BY、ORDER BY 子句。 查询中频繁出现的阻止 SARGability 涉及导致列扫描的子句 WHERE 或 JOIN 中使用的 CONVERT()、CAST()、ISNULL()、COALESCE() 函数。 在数据类型转换情况下(CONVERT 或 CAST),解决方案可能会确保你正在比较相同的数据类型。 下面是一个示例,其中 T1.ProdID 列显式转换为 JOIN 中的 INT 数据类型。 此转换会阻止在联接列上使用索引。 当数据类型不同且 SQL Server 转换其中一种类型以执行联接的隐式转换时,也会出现相同的问题。
SELECT T1.ProdID, T1.ProdDesc
FROM T1 JOIN T2
ON CONVERT(int, T1.ProdID) = T2.ProductID
WHERE t2.ProductID BETWEEN 200 AND 300
为了避免对表进行 T1 扫描,可以在正确规划和设计后更改 ProdID 列的基础数据类型,然后联接这两列,而无需使用转换函数 ON T1.ProdID = T2.ProductID。
另一种解决方案是在 T1 中创建一个使用相同 CONVERT() 函数的计算列,然后在其上创建索引。 这将允许查询优化器使用该索引,而无需更改查询。
ALTER TABLE dbo.T1 ADD IntProdID AS CONVERT (INT, ProdID);
CREATE INDEX IndProdID_int ON dbo.T1 (IntProdID);
在某些情况下,无法轻松地重写查询以允许 SARGability。 在那些情况下,请查看带有索引的计算列是否可提供帮助,或者保持查询原样,并意识到它可能使 CPU 使用率更高。
步骤 7:禁用重度跟踪
检查 SQL 跟踪或 XEvent 跟踪,这些跟踪或跟踪会影响 SQL Server 性能并导致 CPU 使用率过高。 例如,如果跟踪大量 SQL Server 活动,则使用以下事件可能会导致 CPU 使用率较高:
- 查询计划 XML 事件(
query_plan_profile、query_post_compilation_showplan、query_post_execution_plan_profile、query_post_execution_showplan、query_pre_execution_showplan) - 语句级事件(
sql_statement_completed、sql_statement_starting、sp_statement_starting、sp_statement_completed) - 登录和注销事件(
login、process_login_finish、login_event、logout) - 锁定事件(
lock_acquired、lock_cancel、lock_released) - 等待事件(
wait_info、wait_info_external) - SQL 审核事件(取决于审核的组和该组中的 SQL Server 活动)
运行以下查询以确定活动的 XEvent 或 Server 跟踪:
PRINT '--Profiler trace summary--'
SELECT traceid, property, CONVERT(VARCHAR(1024), value) AS value FROM::fn_trace_getinfo(
default)
GO
PRINT '--Trace event details--'
SELECT trace_id,
status,
CASE WHEN row_number = 1 THEN path ELSE NULL end AS path,
CASE WHEN row_number = 1 THEN max_size ELSE NULL end AS max_size,
CASE WHEN row_number = 1 THEN start_time ELSE NULL end AS start_time,
CASE WHEN row_number = 1 THEN stop_time ELSE NULL end AS stop_time,
max_files,
is_rowset,
is_rollover,
is_shutdown,
is_default,
buffer_count,
buffer_size,
last_event_time,
event_count,
trace_event_id,
trace_event_name,
trace_column_id,
trace_column_name,
expensive_event
FROM
(SELECT t.id AS trace_id,
row_number() over(PARTITION BY t.id order by te.trace_event_id, tc.trace_column_id) AS row_number,
t.status,
t.path,
t.max_size,
t.start_time,
t.stop_time,
t.max_files,
t.is_rowset,
t.is_rollover,
t.is_shutdown,
t.is_default,
t.buffer_count,
t.buffer_size,
t.last_event_time,
t.event_count,
te.trace_event_id,
te.name AS trace_event_name,
tc.trace_column_id,
tc.name AS trace_column_name,
CASE WHEN te.trace_event_id in (23, 24, 40, 41, 44, 45, 51, 52, 54, 68, 96, 97, 98, 113, 114, 122, 146, 180) THEN CAST(1 as bit) ELSE CAST(0 AS BIT) END AS expensive_event FROM sys.traces t CROSS APPLY::fn_trace_geteventinfo(t.id) AS e JOIN sys.trace_events te ON te.trace_event_id = e.eventid JOIN sys.trace_columns tc ON e.columnid = trace_column_id) AS x
GO
PRINT '--XEvent Session Details--'
SELECT sess.NAME 'session_name', event_name, xe_event_name, trace_event_id,
CASE WHEN xemap.trace_event_id IN(23, 24, 40, 41, 44, 45, 51, 52, 54, 68, 96, 97, 98, 113, 114, 122, 146, 180)
THEN Cast(1 AS BIT)
ELSE Cast(0 AS BIT)
END AS expensive_event
FROM sys.dm_xe_sessions sess
JOIN sys.dm_xe_session_events evt
ON sess.address = evt.event_session_address
INNER JOIN sys.trace_xe_event_map xemap
ON evt.event_name = xemap.xe_event_name
GO
步骤 8:修复自旋锁争用导致 CPU 使用率过高的问题
若要解决由旋转锁争用导致的常见高 CPU 使用率,请参阅以下部分。
SOS_CACHESTORE旋转锁争用
如果 SQL Server 实例遇到繁重SOS_CACHESTORE的旋转锁争用,或者你注意到查询计划经常在计划外查询工作负载上删除,请参阅以下文章,并使用DBCC TRACEON (174, -1)命令启用跟踪标志T174:
修复:临时 SQL Server 计划缓存上的 SOS_CACHESTORE 旋转锁争用导致 SQL Server 中的 CPU 使用率过高。
如果 CPU 使用率过高的情况通过 T174 得以解决,请使用 SQL Server Configuration Manager 将其作为启动参数启用。
由于大型内存计算机上的SOS_BLOCKALLOCPARTIALLIST旋转锁争用,随机 CPU 使用率较高
如果 SQL Server 实例由于旋转锁争用而遇到随机高 CPU 使用率SOS_BLOCKALLOCPARTIALLIST,建议对 SQL Server 2019 应用累积更新 21。 有关如何解决此问题的详细信息,请参阅提供临时缓解的 bug 参考 2410400 和 DBCC DROPCLEANBUFFERS 。
由于高端计算机上的XVB_list上的旋转锁争用,CPU 使用率较高
如果 SQL Server 实例遇到高 CPU 方案,由高配置计算机上的旋转锁争用(具有大量较新一代处理器(CPU)的高端系统)上的旋转锁争用 XVB_LIST 导致,请启用跟踪标志 TF8102 和 TF8101。
注意
CPU 使用率过高可能会导致其他许多旋转锁类型的自旋锁争用。 有关旋转锁的详细信息,请参阅 诊断和解决 SQL Server 上的旋转锁争用。
步骤 9:配置虚拟机
如果使用的是虚拟机,请确保不要过度预配 CPU 并正确配置它们。 有关详细信息,请参阅排除 ESX/ESXi 虚拟机性能问题 (2001003)。
步骤 10:纵向扩展系统以使用更多 CPU
如果单个查询实例的 CPU 占用很低,但所有查询的总体工作负载共同导致 CPU 占用较高,请考虑通过添加更多 CPU 来纵向扩展计算机。 使用以下查询找出超过单个执行的平均 CPU 占用和最大 CPU 占用的特定阈值且已在系统上多次运行的查询数(确保修改这两个变量的值以匹配你的环境):
-- Shows queries where Max and average CPU time exceeds 200 ms and executed more than 1000 times
DECLARE @cputime_threshold_microsec INT = 200*1000
DECLARE @execution_count INT = 1000
SELECT qs.total_worker_time/1000 total_cpu_time_ms,
qs.max_worker_time/1000 max_cpu_time_ms,
(qs.total_worker_time/1000)/execution_count average_cpu_time_ms,
qs.execution_count,
q.[text]
FROM sys.dm_exec_query_stats qs CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS q
WHERE (qs.total_worker_time/execution_count > @cputime_threshold_microsec
OR qs.max_worker_time > @cputime_threshold_microsec )
AND execution_count > @execution_count
ORDER BY qs.total_worker_time DESC