排查可用性组副本之间的间歇性连接超时问题
本文可帮助你诊断可用性组副本之间报告的间歇性连接超时。
间歇性可用性组副本连接超时的症状和影响
查询主副本和次要副本将返回不同的结果
查询次要副本的只读工作负荷可能会查询过时的数据。 如果发生间歇性副本连接超时,则查询相同数据时,主副本数据库上的数据的更改尚未反映在辅助数据库中。 有关详细信息,请参阅 次要副本 上的数据延迟部分。
诊断报告可用性组未同步
SQL Server Management Studio 中的 AlwaysOn 仪表板可能会报告具有副本处于 “未同步 ”状态的运行不正常的可用性组。 还可以观察 AlwaysOn 仪表板报表副本处于 “未同步 ”状态。

查看这些副本的 SQL Server 错误日志时,可能会观察到以下消息,指出可用性组中的副本之间存在连接超时:
主副本的错误日志
2023-02-15 07:10:55.500 spid43s Always On availability groups connection with secondary database terminated for primary database 'agdb' on the availability replica 'SQL19AGN2' with Replica ID: {<replicaid>}. This is an informational message only. No user action is required.
辅助副本的错误日志
2023-02-15 07:11:03.100 spid31s A connection time-out has occurred on a previously established connection to availability replica 'SQL19AGN1' with id [<replicaid>]. Either a networking or a firewall issue exists or the availability replica has transitioned to the resolving role.
2023-02-15 07:11:03.100 spid31s Always On Availability Groups connection with primary database terminated for secondary database 'agdb' on the availability replica 'SQL19AGN1' with Replica ID: {<replicaid>}. This is an informational message only. No user action is required.
间歇性连接问题可能会影响辅助副本的故障转移就绪情况
如果将可用性组配置为自动故障转移,并且同步提交故障转移伙伴间歇性地与主故障转移断开连接,则自动故障转移可能失败。
可以查询 sys.dm_hadr_database_replia_cluster_states 以确定可用性组数据库目前是否已准备好故障转移。 下面是在次要副本上停止镜像终结点时的结果示例:
SELECT drcs.database_name, drcs.is_failover_ready, ar.replica_server_name, ars.role_desc, ars.connected_state_desc,
ars.last_connect_error_description, ars.last_connect_error_number, ar.endpoint_url
FROM sys.dm_hadr_availability_replica_states ars JOIN sys.availability_replicas ar ON ars.replica_id=ar.replica_id
JOIN sys.dm_hadr_database_replica_cluster_states drcs ON ar.replica_id=drcs.replica_id
WHERE ars.role_desc='SECONDARY'

如果故障转移与副本连接超时相吻合,则自动故障转移可能不会使可用性组联机在故障转移伙伴计算机上的主要角色。
连接超时错误指示什么?
可用性组副本设置 SESSION_TIMEOUT的默认值为 10 秒。 为每个副本配置此设置。 它确定副本在报告连接超时之前等待接收来自其伙伴副本的响应的时间。如果副本未从合作伙伴副本获取响应,则会在Microsoft SQL Server 错误日志和 Windows 应用程序日志中报告连接超时。 报告超时的副本会立即尝试重新连接,并将继续每隔五秒尝试一次。
通常,仅检测并报告一个副本的连接超时。 但是,两个副本可能会同时报告连接超时。 此消息有不同版本,具体取决于使用以前建立的连接还是新连接发生的连接超时:
Message 35206 A connection timeout has occurred on a previously established connection to availability replica '<replicaname>' with id [<replicaid>]. Either a networking or a firewall issue exists or the availability replica has transitioned to the resolving role.
Message 35201 A connection timeout has occurred while attempting to establish a connection to availability replica '<replicaname>' with id [<replicaid>]. Either a networking or firewall issue exists, or the endpoint address provided for the replica is not the database mirroring endpoint of the host server instance.
合作伙伴副本可能不会检测到超时。如果这样做,它可能会报告消息 35201 或 35206。 如果没有,它会向每个可用性组数据库报告连接丢失:
Message 35267 Always On Availability Groups connection with primary/secondary database terminated for primary/secondary database '<databasename>' on the availability replica '<replicaname>' with Replica ID: {<replicaid>}. This is an informational message only. No user action is required.
下面是 SQL Server 向错误日志报告的示例:如果停止主副本上的镜像终结点,次要副本将检测到连接超时,次要副本错误日志中报告了 35206 和 35267 消息:
2023-02-15 07:11:03.100 spid31s A connection timeout has occurred on a previously established connection to availability replica 'SQL19AGN1' with id [<replicaid>]. Either a networking or a firewall issue exists or the availability replica has transitioned to the resolving role.
2023-02-15 07:11:03.100 spid31s Always On Availability Groups connection with primary database terminated for secondary database 'agdb' on the availability replica 'SQL19AGN1' with Replica ID:[<replicaid>]. This is an informational message only. No user action is required.
在此示例中,主副本未检测到任何连接超时,因为它仍可与辅助数据库通信,并且报告了每个可用性组数据库的消息 35267(在此示例中,只有一个数据库“agdb”):
2023-02-15 07:10:55.500 spid43s Always On Availability Groups connection with secondary database terminated for primary database 'agdb' on the availability replica 'SQL19AGN2' with Replica ID: {<replicaid>}. This is an informational message only. No user action is required.
副本连接超时的原因
应用程序问题
由于多种原因,SQL Server 可能正忙,并且不会在可用性组 SESSION_TIMEOUT 期间内为镜像终结点连接提供服务。 这会导致连接超时。其中一些原因包括:
SQL Server 的 CPU 使用率为 100%。 这意味着 SQL Server 或其他应用程序一次驱动 CPU 数秒。
SQL Server 遇到非生成计划程序事件。 如果线程没有及时生成,SQL Server 线程负责将计划程序(CPU)传递给其他线程以完成其工作。
SQL Server 遇到工作线程耗尽、内存不足问题或影响其服务镜像终结点连接能力的应用程序问题。
网络问题
这要求在触发错误时收集主要副本和次要副本上的网络跟踪日志。 为此,可以检查网络延迟和丢弃的数据包。
如何诊断副本连接超时
对于阻止 SQL Server 与伙伴副本建立连接的应用程序问题,本部分介绍如何分析 SQL Server 日志。 这些提示可帮助你确定副本连接超时的根本原因。 本部分以有关如何在发生连接超时时收集网络跟踪以便检查网络状态的更高级指导结束。
评估副本连接超时的时间和位置
查看连接超时的历史记录、频率和趋势。 使用在 SQL Server 错误日志中找到的消息是执行此操作的好方法。 在何处报告连接超时? 它们是否一致地报告在主要副本或次要副本上? 错误何时发生? 它们是否发生在某一个月的某一周、一周或一天的时间? 其他计划的维护或批处理是否与观察到连接超时的时间相对应? 此评估可帮助你确定连接超时的范围并关联,以确定根本原因。
查看AlwaysOn_health扩展事件会话
AlwaysOn_health扩展事件会话已增强,以包含事件ucs_connection_setup,该事件在副本与伙伴副本建立连接时触发。 排查连接超时问题时,这非常有用。
注意
扩展 ucs_connection_setup 事件已添加到最新的 SQL Server 累积更新。 必须运行最新的累积更新才能观察此扩展事件。
查询 AlwaysOn 分布式管理视图 (DMV)
可以查询 Always On DMV,了解有关副本连接状态的详细信息。 此查询仅报告连接状态以及与发生问题时连接超时关联的任何错误。 如果连接问题间歇性,则查询可能无法轻松捕获断开连接的状态。
SELECT ar.replica_server_name, ars.role_desc, ars.connected_state_desc,
ars.last_connect_error_description, ars.last_connect_error_number, ar.endpoint_url
FROM sys.dm_hadr_availability_replica_states ars JOIN sys.availability_replicas ar ON ars.replica_id=ar.replica_id
下面的示例演示了持续断开连接的状态,因为主副本上的镜像终结点已停止。 通过查询主副本,Always On DMV 可以报告主要副本和所有次要副本(在主副本上禁用终结点)。

通过查询次要副本,Always On DMV 仅报告次要副本。

查看 AlwaysOn 扩展事件会话
使用 SQL Server Management Studio(SSMS)对象资源管理器连接到每个副本,并打开
AlwaysOn_health扩展事件文件。在 SSMS 中,转到“文件>打开”,然后选择“合并扩展事件文件”。
选择“添加”按钮。
在“文件打开”对话框中,导航到 SQL Server \LOG 目录中的文件。
按 Control,然后选择名称以“AlwaysOn_healthxxx.xel”开头的文件。
选择“打开”,然后选择“确定”。
应该会在 SSMS 中看到一个新的选项卡式窗口,其中显示了 AlwaysOn 事件。
以下屏幕截图显示了
AlwaysOn_health次要副本中的数据。 第一个轮廓框显示主副本上的终结点停止后的连接丢失。 第二个大纲框显示下次辅助副本尝试连接到主副本时发生的连接失败。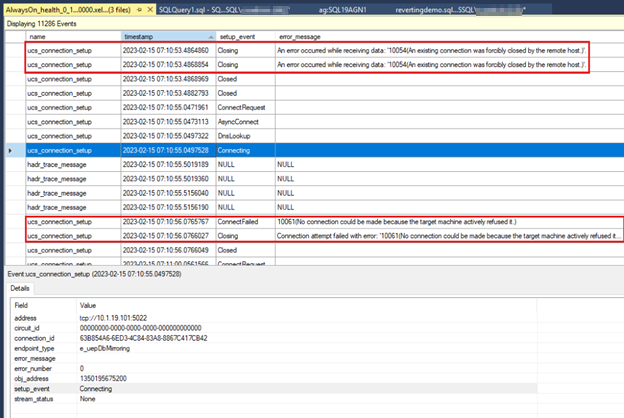

检查非生成事件是否导致连接超时
可用性副本无法为合作伙伴副本连接提供服务的最常见原因之一是非生成计划程序。 有关非生成计划程序的详细信息,请参阅 SQL Server 计划和生成疑难解答。
SQL Server 跟踪短于 5 到 10 秒的非生成计划程序事件。 它报告组件输出中的数据点中的TrackingNonYieldingSchedulersp_server_diagnostics query_processing这些事件。
若要检查可能导致副本连接超时的非生成事件,请执行以下步骤:
创建每五秒记录
sp_server_diagnostics一次的 SQL 代理作业。在未报告连接超时的服务器上计划此作业。也就是说,如果服务器 A 副本在其错误日志中报告副本连接超时,请在伙伴副本服务器 B 上设置 SQL 代理作业。或者,如果在两个副本上看到连接超时,请在这两个副本上创建该作业。
运行以下批处理文件以创建每五秒运行
sp_server_diagnostics一次的作业,将输出追加到文本文件,然后启动该作业。 以下示例sp_server_diagnostics 5中的命令每五秒执行一次。 因此,无需计划此作业每隔五秒运行一次,只需启动作业,该作业将运行到停止为止,每五秒运行一次:USE [msdb] GO DECLARE @ReturnCode INT SELECT @ReturnCode = 0 DECLARE @jobId BINARY(16) EXEC @ReturnCode = msdb.dbo.sp_add_job @job_name=N'Run sp_server_diagnostics', @owner_login_name=N'sa', @job_id = @jobId OUTPUT /****** Object: Step [Run SP_SERVER_DIAGNOSTICS] Script Date: 2/15/2023 4:20:41 PM ******/ EXEC @ReturnCode = msdb.dbo.sp_add_jobstep @job_id=@jobId, @step_name=N'Run SP_SERVER_DIAGNOSTICS', @subsystem=N'TSQL', @command=N'sp_server_diagnostics 5', @database_name=N'master', @output_file_name=N'D:\cases\2423\sp_server_diagnostics_output.out', @flags=2 EXEC @ReturnCode = msdb.dbo.sp_add_jobserver @job_id = @jobId, @server_name = N'(local)' EXEC sp_start_job 'Run sp_server_diagnostics'注意
在这些命令中,更改为
@output_file_name有效的路径并提供文件名。
分析结果
报告连接超时时,请注意 SQL Server 错误日志中显示的超时事件的时间戳。 对于以下示例中的副本, SQL19AGN1 报告副本连接超时。 因此,在合作伙伴副本上 SQL19AGN2创建了 SQL 代理作业。 然后,错误日志中 SQL19AGN1 报告了 07:24:31 的连接超时。

接下来,在报告时间检查运行sp_server_diagnostics的 SQL 代理作业的输出,具体检查 TrackingNonYieldingScheduler 组件输出中的数据 query_processing 点。 输出报告在SQL19AGN1(07:24:31)报告副本连接超时时,服务器SQL19AGN2(07:24:33)跟踪了非生成计划程序(作为非零十六进制值)。
注意
sp_server_diagnostics以下输出连接以显示 create_time (timestamp) 和query_processing TrackingNonYieldingScheduler结果。

调查非生成计划程序事件
如果从前面的诊断步骤中验证了非生成事件导致副本连接超时的步骤:
确定在运行非生成事件时在 SQL Server 中运行的工作负荷。
与副本连接超时类似,在事件发生的月份、日或周中查找这些事件的趋势。
在检测到非生成事件的系统上收集性能监视器跟踪。
收集系统资源的关键性能计数器,包括 Processor::% Processor Time、Memory::Available MBytes、 Logical Disk::Avg Disk Queue Length 和 Logical Disk::Avg Disk sec/Transfer。
如有必要,请打开 SQL Server 支持事件,以进一步帮助查找这些非生成事件的根本原因。 共享收集的日志以供进一步分析。
高级数据收集:在连接超时期间收集网络跟踪
如果以前对 SQL Server 应用程序的诊断没有产生根本原因,则应检查网络。 成功分析网络需要收集涵盖连接超时时间的网络跟踪。
以下过程在 SQL Server 错误日志中报告连接超时的副本上启动 Windows netsh 网络跟踪。 在应用程序日志中记录其中一个 SQL Server 连接错误时,将触发 Windows 计划事件任务。 计划任务运行命令以停止 netsh 网络跟踪,以便不会覆盖关键网络跟踪数据。 这些步骤还假定批处理和跟踪日志的路径为 *F:* 。 将此路径调整到你的环境。
启动网络跟踪,如以下代码片段所示,在连接超时发生的两个副本上:
netsh trace start capture=yes persistent=yes overwrite=yes maxsize=500 tracefile=f:\trace.etl创建停止事件 35206 或 35267 上的跟踪的 Windows 计划任务
netsh。 可以在管理命令行中创建这些任务:schtasks /Create /tn Event35206Task /tr F:\stoptrace.bat /SC ONEVENT /EC Application /MO *[System/EventID=35206] /f /RL HIGHEST schtasks /Create /tn Event35267Task /tr F:\stoptrace.bat /SC ONEVENT /EC Application /MO *[System/EventID=35267] /f /RL HIGHEST事件发生并捕获网络跟踪后,可以删除
ONEVENT任务:PS C:\Users\sqladmin> Schtasks /Delete /tn Event35206Task /F PS C:\Users\sqladmin> Schtasks /Delete /tn Event35267Task /F
网络跟踪的分析超出了此疑难解答的范围。 如果无法解释网络跟踪,请联系Microsoft SQL Server 支持团队,并与其他请求的日志文件一起提供跟踪,以便进行根本原因分析。
我还能做些什么来缓解连接超时?
默认可用性组 SESSION_TIMEOUT配置为 10 秒。 可以通过调整可用性组副本 SESSION_TIMEOUT 属性来缓解连接超时。 此设置按副本进行。 针对主要副本和每个受影响的次要副本调整它。 下面是语法的示例。 默认值 SESSION_TIMEOUT 为 10。 因此,可以使用 15 作为下一个值。
ALTER AVAILABILITY GROUP ag
MODIFY REPLICA ON 'SQL19AGN1' WITH (SESSION_TIMEOUT = 15);