排查 SQL Server Always On 环境中的自动故障转移问题
本文可帮助你解决Microsoft SQL Server 中自动故障转移期间发生的问题。
原始产品版本:SQL Server
原始 KB 数: 2833707
总结
可以为 SQL Server Always On 可用性组配置自动故障转移。 如果在托管主副本的 SQL Server 实例上检测到运行状况问题,则可以将主要角色转换为自动故障转移伙伴(辅助副本)。 但是,辅助副本不能始终转换为主要角色。 在某些情况下,只能将其转换为 RESOLVING 角色。 在这种情况下,除非主副本返回到正常状态,否则没有副本将具有主要角色。 此外,可用性数据库将不可访问。
本文列出了自动故障转移失败的一些常见原因,并讨论了诊断这些故障的原因所要采取的步骤。
成功触发自动故障转移时出现症状
在托管主副本的 SQL Server 实例上触发自动故障转移时,辅助副本将 RESOLVING 转换为角色,然后转换为主角色。 尽管此过程成功,但在类似于以下文本的 SQL Server 日志报告中记录错误条目:
The state of the local availability replica in availability group '\<Group name>' has changed from 'RESOLVING_NORMAL' to 'PRIMARY_PENDING'
The state of the local availability replica in availability group '\<Group name>' has changed from 'PRIMARY_PENDING' to 'PRIMARY_NORMAL'

注意
次要副本已成功从 RESOLVING_NORMAL 状态转换为 PRIMARY_NORMAL 状态。
如果自动故障转移失败,则会出现症状
如果自动故障转移事件未成功,辅助副本不会成功转换为主要角色。 因此,可用性副本将报告此副本处于 RESOLVING 状态。 此外,可用性数据库报告它们处于 NOT SYNCHRONIZING 状态,应用程序无法访问这些数据库。
例如,在下图中,SQL Server Management Studio 报告辅助副本处于 RESOLVING 状态,因为自动故障转移过程无法将辅助副本转换为主要角色。
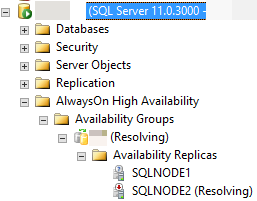
以下部分讨论了自动故障转移可能失败的几个可能原因,以及如何诊断每个原因。
案例 1:“指定时间段内的最大失败数”值已用尽
可用性组具有 Windows 群集资源属性,例如 “指定时间段 ”属性中的“最大失败数”。 此属性用于避免在发生多个节点故障时无限期移动群集资源。
若要调查和诊断这是故障转移失败的原因,请查看 Windows 群集日志(Cluster.log),然后检查属性。
步骤 1:查看 Windows 群集日志中的数据(Cluster.log)
使用 Windows PowerShell 在托管主副本的群集节点上生成 Windows 群集日志。 为此,请在托管主副本的 SQL Server 实例上提升的 PowerShell 窗口中运行以下 cmdlet:
Get-ClusterLog -Node <SQL Server node name> -TimeSpan 15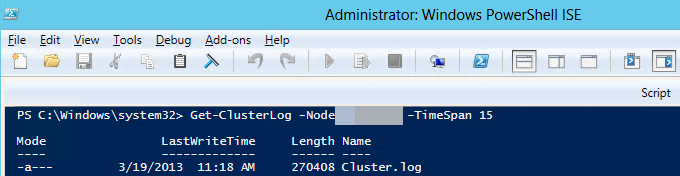
[!NOTES]
-TimeSpan 15此步骤中的参数假定在前 15 分钟内诊断出的问题。- 默认情况下,日志文件在 %WINDIR%\cluster\reports 中创建。
在 记事本中打开Cluster.log 文件以查看 Windows 群集日志。
在记事本中,选择“编辑>查找”,然后在文件末尾搜索“failoverCount”字符串。 在结果中,应找到类似于以下消息的消息:
不故障转移组 <资源组名称>、failoverCount 3、failoverThresholdSetting <Number>、computedFailoverThreshold 2

步骤 2:检查指定时间段属性中的最大失败数
启动故障转移群集管理器。
在导航窗格中,选择“ 角色”。
在 “角色 ”窗格中,右键单击群集资源,然后选择“ 属性”。
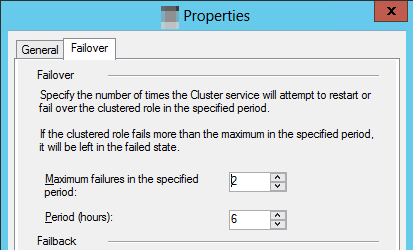
选择 “故障转移 ”选项卡,然后选择 “指定时间段 ”值中的“最大失败数”。
注意
默认行为指定,如果群集资源在六小时内失败三次,它应保持失败状态。 对于可用性组,这意味着副本处于
RESOLVING状态。
结语
分析日志后,你会发现 failoverCount 值 3 大于 computedFailoverThreshold 值为 2。 因此,Windows 群集无法将可用性组资源的故障转移操作完成到故障转移伙伴。
分辨率
若要解决此问题,请在指定的时间段值中增加最大失败数。
注意
增加此值可能无法解决问题。 可能存在一个更严重的问题,导致可用性组在短时间内多次失败。 默认情况下,此时间段为 15 分钟。 增加此值可能会导致可用性组失败次数更多,并且仍处于失败状态。 建议使用积极的故障排除来确定自动故障转移发生的原因。
案例 2:NT Authority\SYSTEM 帐户权限不足
SQL Server 数据库引擎资源 DLL 使用 ODBC 监视运行状况连接到托管主副本的 SQL Server 实例。 用于此连接的登录凭据是本地 SQL Server NT AUTHORITY\SYSTEM 登录帐户。 默认情况下,此本地登录帐户被授予以下权限:
- 更改任何可用性组
- 连接 SQL
- 查看服务器状态
NT AUTHORITY\SYSTEM如果登录帐户在自动故障转移伙伴(次要副本)上缺少这些权限,则发生自动故障转移时,SQL Server 无法启动运行状况检测。 因此,次要副本无法转换为主要角色。 若要调查和诊断这是否是原因,请查看 Windows 群集日志。 为此,请按照下列步骤进行操作:
使用 Windows PowerShell 在群集节点上生成 Windows 群集日志。 为此,请在托管未转换为主要角色的辅助副本的 SQL Server 实例上提升的 PowerShell 窗口中运行以下 cmdlet:
Get-ClusterLog -Node <SQL Server node name> -TimeSpan 15
在 记事本中打开Cluster.log 文件以查看 Windows 群集日志。
查找类似于以下文本的错误条目:
未能运行诊断命令。 用户没有执行此操作的权限。
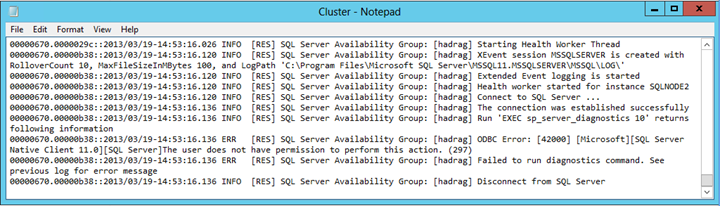
结语
Cluster.log文件报告 SQL Server 运行诊断命令时存在权限问题。 在此示例中,失败是由从 NT AUTHORITY\SYSTEM 托管自动故障转移对辅助副本的 SQL Server 实例上的登录帐户中删除 View 服务器状态权限导致的。
分辨率
若要解决此问题,请向NT AUTHORITY\SYSTEM登录帐户授予足够的权限,以检测 SQL Server 数据库引擎资源 DLL 的运行状况。
案例 3:可用性数据库未处于 SYNCHRONIZED 状态
若要自动故障转移,可用性组中定义的所有可用性数据库必须处于 SYNCHRONIZED 主副本和辅助副本之间的状态。 发生自动故障转移时,必须满足此同步条件,以确保不会丢失数据。 因此,如果可用性组中的一个可用性数据库处于同步或 NOT SYNCHRONIZED 状态,则自动故障转移不会成功将辅助副本转换为主要角色。
有关自动故障转移所需的条件的详细信息,请参阅自动故障转移所需的条件和同步提交副本支持故障转移和故障转移模式(AlwaysOn 可用性组)的两个设置部分。
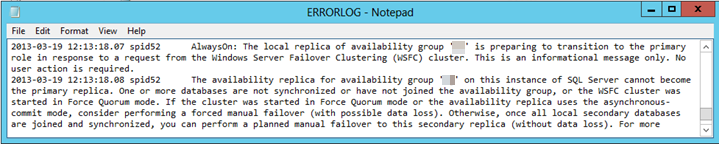
若要调查和诊断这是故障转移失败的原因,请查看 SQL Server 错误日志。 应会看到类似于以下文本的错误条目:
一个或多个数据库未同步或尚未加入可用性组。
若要检查可用性数据库是否处于 SYNCHRONIZED 状态,请执行以下步骤:
连接到辅助副本。
运行以下 SQL 脚本,检查
is_failover_ready可用性组中未故障转移的所有可用性数据库的值。注意
任何可用性数据库的值为零可以阻止自动故障转移。 此值指示可用性数据库不是
SYNCHRONIZED。SELECT database_name, is_failover_ready FROM sys.dm_hadr_database_replica_cluster_states WHERE replica_id IN (SELECT replica_id FROM sys.dm_hadr_availability_replica_states)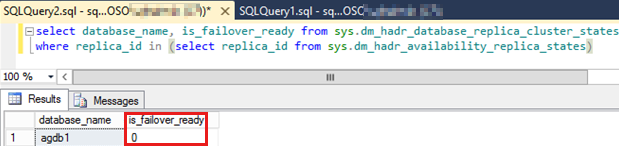
结语
可用性组的成功自动故障转移要求所有可用性数据库处于 SYNCHRONIZED 状态。 有关可用性模式的详细信息,请参阅 AlwaysOn 可用性组中的可用性模式。
案例 4:为次要副本(目标主副本)上的客户端协议选择了“强制协议加密”配置,但未为加密配置副本
在故障转移期间,当主服务器检测到运行状况问题时,故障转移伙伴(辅助副本)上的群集 DLL 会尝试连接到本地副本来启动运行状况监视。 这是过渡到主要角色的一部分。 如果未为次要副本配置加密,但在 客户端配置中无意中设置了强制协议加密 设置,则连接将失败,并且无法进行故障转移。
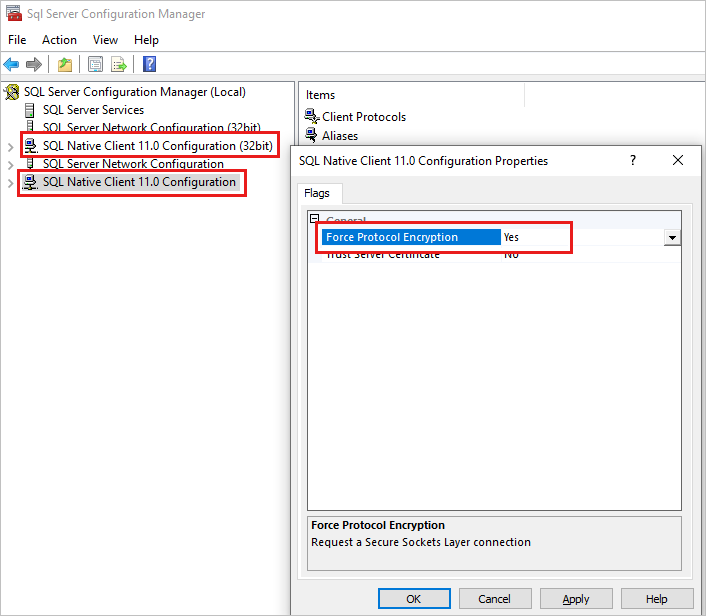
若要检查此配置,请执行以下操作:
- 启动 SQL Server 配置管理器。
- 在 左 窗格中,右键单击 SQL Native Client 11.0 配置,然后选择“ 属性”。
- 在对话框中,选中“ 强制协议加密 ”设置。 如果设置为 “是”,请将值更改为 “否”。
- 重新测试故障转移。
结语
SQL Server Always On 运行状况监视使用本地 ODBC 连接来监视 SQL Server 运行状况。 只有在 SQL Server 本身配置为在 SQL Server 网络配置部分的SQL Server 配置管理器中强制加密时,才能在SQL Server 配置管理器的客户端配置部分中启用强制协议加密。 有关详细信息,请参阅启用数据库引擎的加密连接。
案例 5:次要副本或节点上的性能问题导致 AlwaysOn 运行状况检查失败
在从主副本故障转移到次要副本之前,SQL Server 数据库引擎资源 DLL 连接到辅助副本,以确定副本的运行状况。 如果由于次要副本上的性能问题导致此连接失败,则不会发生自动故障转移。
若要调查和诊断这是否是原因,请执行以下步骤:
查看辅助副本上的群集日志以检查错误消息“由于打开服务器连接延迟而无法完成登录过程”。
0000110c.00002bcc::2020/08/06-01:17:54.943 INFO [RCM] move of group AOCProd01AG from CO2ICMV3SQL09(1) to CO2ICMV3SQL10(2) of type MoveType::Manual is about to succeed, failoverCount=3, lastFailoverTime=2020/08/05-02:08:54.524 targeted=true 00002a54.0000610c::2020/08/06-01:18:44.929 ERR [RES] SQL Server Availability Group <AOCProd01AG>: [hadrag] ODBC Error: [08001] [Microsoft][SQL Server Native Client 11.0]Unable to complete login process due to delay in opening server connection (0) 00002a54.0000610c::2020/08/06-01:18:44.929 INFO [RES] SQL Server Availability Group <AOCProd01AG>: [hadrag] Could not connect to SQL Server (rc -1) 00002a54.0000610c::2020/08/06-01:18:44.929 INFO [RES] SQL Server Availability Group <AOCProd01AG>: [hadrag] SQLDisconnect returns following information 00002a54.0000610c::2020/08/06-01:18:44.929 ERR [RES] SQL Server Availability Group <AOCProd01AG>: [hadrag] ODBC Error: [08003] [Microsoft][ODBC Driver Manager] Connection not open (0) 00002a54.0000610c::2020/08/06-01:18:44.931 ERR [RES] SQL Server Availability Group <AOCProd01AG>: [hadrag] Failed to connect to SQL Server 00002a54.0000610c::2020/08/06-01:18:44.931 ERR [RHS] Online for resource AOCProd01AG failed.如果故障转移到具有繁忙现有工作负荷的 SQL Server 辅助副本,则可能会出现这种情况。 这可能会延迟 SQL Server 对 HADR 运行状况连接请求尝试的响应,并阻止成功的故障转移尝试。
若要确定系统计划程序是否有压力,请使用 SQL Server Management Studio 在次要副本上运行以下脚本:
USE MASTER GO WHILE 1=1 BEGIN PRINT convert(varchar(20), getdate(),120) DECLARE @max INT; SELECT @max = max_workers_count FROM sys.dm_os_sys_info; SELECT GETDATE() AS 'CurrentDate', @max AS 'TotalThreads', SUM(active_Workers_count) AS 'CurrentThreads', @max - SUM(active_Workers_count) AS 'AvailableThreads', SUM(runnable_tasks_count) AS 'WorkersWaitingForCpu', SUM(work_queue_count) AS 'RequestWaitingForThreads' --SUM(current_workers_count) AS 'AssociatedWorkers' FROM sys.dm_os_Schedulers WHERE STATUS = 'VISIBLE ONLINE'; wait for delay '0:0:15' END下面是上述查询的示例输出:
CurrentDate TotalThreads CurrentThreads AvailableThreads WorkersWaitingForCpu RequestWaitingForThreads 2020-10-06 01:27:01.337 1216 361 855 33 0 2020-10-06 01:27:08.340 1216 1412 -196 22 76 2020-10-06 01:27:15.340 1216 1304 -88 2 161 2020-10-06 01:27:22.340 1216 1242 26- 21 185 2020-10-06 01:27:29.343 1216 13:46 -130 19 476 2020-10-06 01:27:36.350 1216 1350 -134 9 630 2020-10-06 01:27:43.353 1216 13:46 -130 13 539 2020-10-06 01:27:50.360 1216 1378 -162 5 328 2020-10-06 01:27:57.360 1216 197 1019 0 0 报告
WorkersWaitingForCpu并指示发生计划争用且RequestWaitingForThreadsSQL Server 无法及时为当前工作负荷提供服务的高值。
分辨率
如果遇到此问题,请在次要副本上重新平衡工作负荷,或考虑在运行这些工作负荷的计算机上增加处理能力(添加处理器)。
排查其他故障转移事件失败的问题
若要在故障转移期间监视新主副本的运行状况,必须将 AlwaysOn 运行状况监视本地连接到正在转换为主要角色的 SQL Server 实例。
除了本文中讨论的更常见原因外,还有其他许多原因导致此连接尝试失败。 若要进一步调查故障转移尝试失败,请查看故障转移伙伴上的群集日志(无法故障转移到的副本):
使用 Windows PowerShell 在群集节点上生成 Windows 群集日志。 为此,请在托管未转换为主角色的辅助副本的 SQL Server 实例上提升的 PowerShell 窗口中运行以下 cmdlet。 群集日志将生成过去 60 分钟的活动。
Get-ClusterLog -Node <SQLServerNodeName> -TimeSpan 60若要查看 Windows 群集日志,请在 记事本中打开Cluster.log 文件。
搜索在故障转移事件失败期间发生的“连接到 SQL Server”字符串。
使用线程 ID 查看后续登录消息(请参阅以下屏幕截图),以关联与登录事件相关的事件。 以下示例显示搜索“连接到 SQL Server”。它还显示使用线程 ID(左侧)查找描述连接尝试失败的原因的其他诊断。


以下示例显示了与新主副本的连接失败。
示例集 1
[hadrag] ODBC Error: [08001] [Microsoft][SQL Server Native Client 11.0]SQL Server Network
Interfaces: No client protocols are enabled and no protocol was specified in the connection
string [xFFFFFFFF]. (268435455)
分辨率
启动SQL Server 配置管理器,然后验证是否在 SQL 本机客户端配置的客户端协议下启用了共享内存或 TCP/IP。
示例集 2
[hadrag] ODBC Error: [08001] [Microsoft][SQL Server Native Client 11.0]SQL Server Network
Interfaces: Server doesn't support requested protocol [xFFFFFFFF]. (268435455)
分辨率
启动SQL Server 配置管理器,然后验证是否在 SQL 本机客户端配置的客户端协议下启用了共享内存或 TCP/IP。
示例集 3
000010b8.00001764::2020/12/02-16:52:49.808 ERR [RES] SQL Server Availability Group : [hadrag]
ODBC Error: [42000] [Microsoft][SQL Server Native Client 11.0][SQL Server]Cannot alter the availability
group 'ag', because it does not exist or you do not have permission. (15151)
000010b8.00000fd0::2020/12/02-17:01:14.821 ERR [RES] SQL Server Availability Group: [hadrag]
ODBC Error: [42000] [Microsoft][SQL Server Native Client 11.0][SQL Server]The user does not have permission to perform this action. (297)
000010b8.00001838::2020/12/02-17:10:04.427 ERR [RES] SQL Server Availability Group : [hadrag]
ODBC Error: [42000] [Microsoft][SQL Server Native Client 11.0][SQL Server]Login failed for user
'SQLREPRO\NODE2$'. Reason: The account is disabled. (18470)
分辨率