应用内核更改后 Azure Linux 虚拟机无法启动
适用于:✔️ Linux VM
注意
本文中引用的 CentOS 是 Linux 分发版,将达到生命周期结束(EOL)。 请相应地考虑使用和规划。 有关详细信息,请参阅 CentOS 生命周期指南。
本文提供了在应用内核更改后 Linux 虚拟机(VM)无法启动的问题的解决方案。
先决条件
确保在 Linux VM 中启用串行控制台 并正常运行。
如何识别与内核相关的启动问题
若要标识与内核相关的启动问题,请检查特定的内核恐慌字符串。 为此,请使用 Azure CLI 或Azure 门户在启动诊断窗格或串行控制台窗格中查看 VM 的串行控制台日志输出。
内核恐慌类似于以下输出,将在串行控制台日志的末尾显示:
Probing EDD (edd=off to disable)... ok
Memory KASLR using RDRAND RDTSC...
[ 300.206297] Kernel panic - xxxxxxxx
[ 300.207216] CPU: 1 PID: 1 Comm: swapper/0 Tainted: G ------------ T 3.xxx.x86_64 #1
联机故障排除
提示
如果 VM 有最近的备份, 请从备份 还原 VM 以修复启动问题。
串行控制台是解决启动问题的最快方法。 它允许你直接修复此问题,而无需将系统磁盘呈现给恢复 VM。 请确保满足分发所需的先决条件。 有关详细信息,请参阅 适用于 Linux 的虚拟机串行控制台。
使用 Azure 串行控制台在 GRUB 菜单中中断 VM,并选择任何以前的内核来启动它。 有关详细信息,请参阅 旧版内核上的启动系统。
转到相应的部分,解决与内核相关的特定启动问题:
解决与内核相关的启动问题后,重启 VM,以便它可以启动最新的内核版本。
脱机故障排除
提示
如果 VM 有最近的备份, 请从备份 还原 VM 以修复启动问题。
如果 Azure 串行控制台在特定 VM 中不起作用,或者不是订阅中的选项,请使用救援/修复 VM 排查启动问题。 为此,请按照下列步骤进行操作:
使用 VM 修复命令 创建已附加受影响 VM OS 磁盘副本的修复 VM。 使用 chroot 在修复 VM 中装载 OS 文件系统的副本。
注意
或者,可以使用 Azure 门户手动创建救援 VM。 有关详细信息,请参阅通过使用 Azure 门户将 OS 磁盘附加到恢复 VM 来对 Linux VM 进行故障排除。
转到相应的部分,解决与内核相关的特定启动问题:
解决与内核相关的启动问题后,执行以下操作:
- 退出 chroot。
- 从救援/修复 VM 中卸载文件系统的副本。
az vm repair restore运行以下命令,将修复的 OS 磁盘与 VM 的原始 OS 磁盘交换。 有关详细信息,请参阅使用 Azure 虚拟机修复命令修复 Linux VM 中的步骤 5。- 通过查看 Azure 串行控制台或尝试连接到 VM 来验证 VM 是否能够启动。
如果存在与内核相关的重要内容、整个
/boot分区或其他重要内容缺失,并且无法恢复,建议从备份还原 VM。 有关详细信息,请参阅如何还原 Azure 门户 中的 Azure VM 数据。
较旧内核版本的启动系统
使用 Azure 串行控制台
使用 Azure 串行控制台重启 VM。
- 选择 串行控制台窗口顶部的关闭 按钮。
- 选择“重启 VM”选项。
串行控制台连接恢复后,将在串行控制台窗口的左上角看到倒计时计数器。 按 ESCAPE 键在 GRUB 菜单上中断 VM。
按向下键选择任何以前的内核版本。
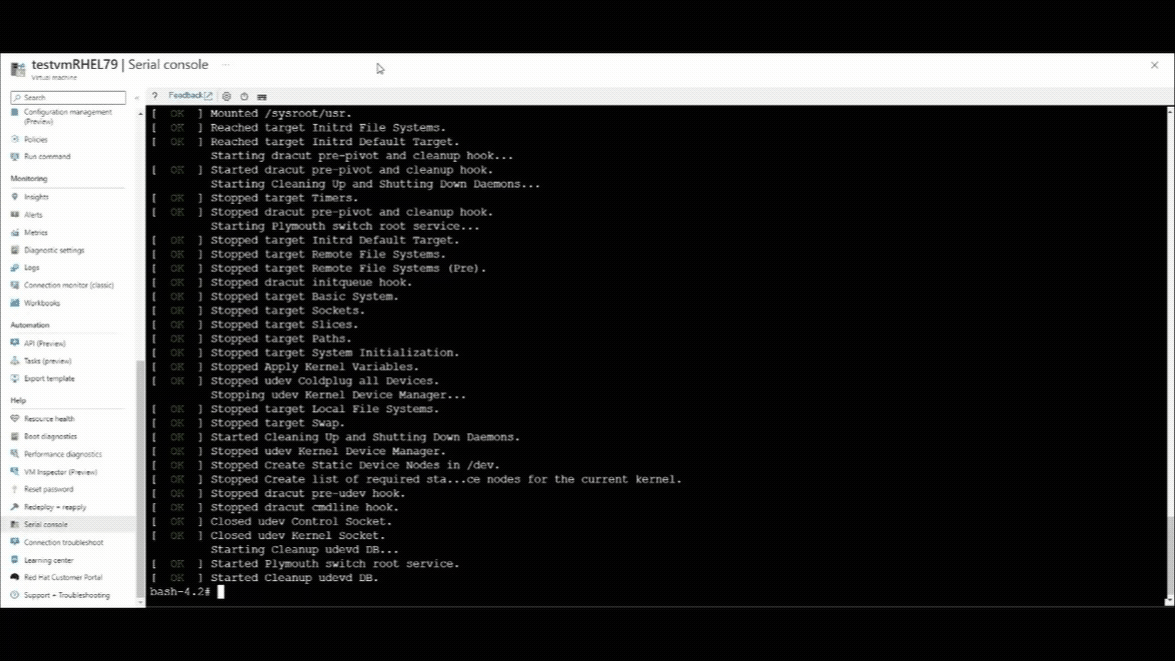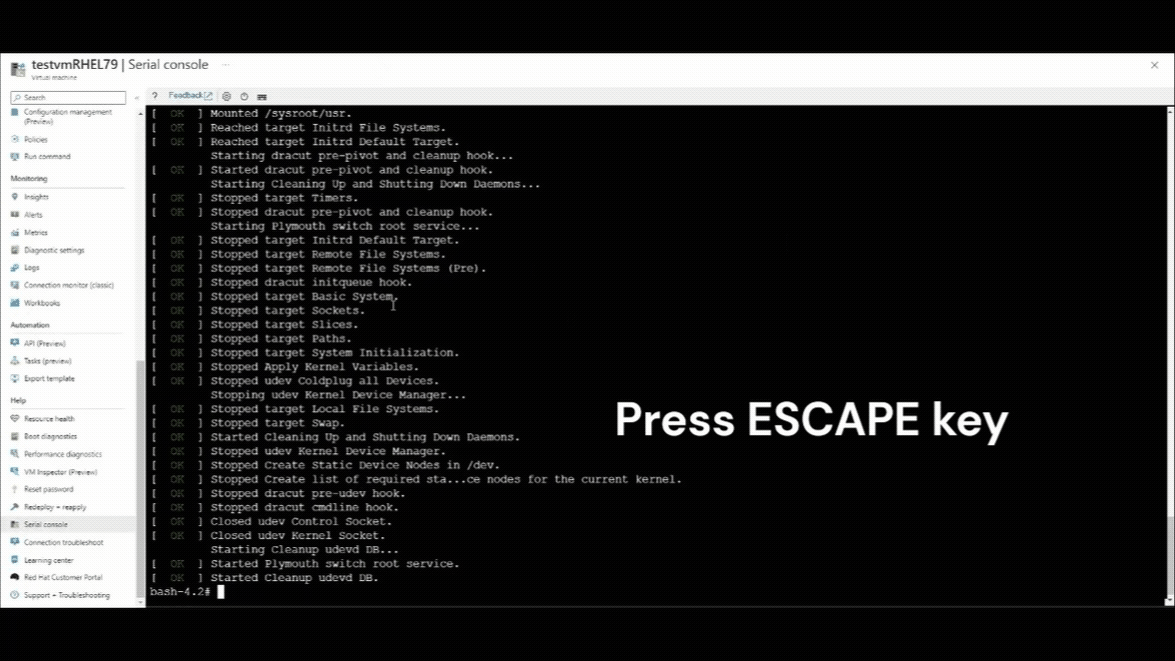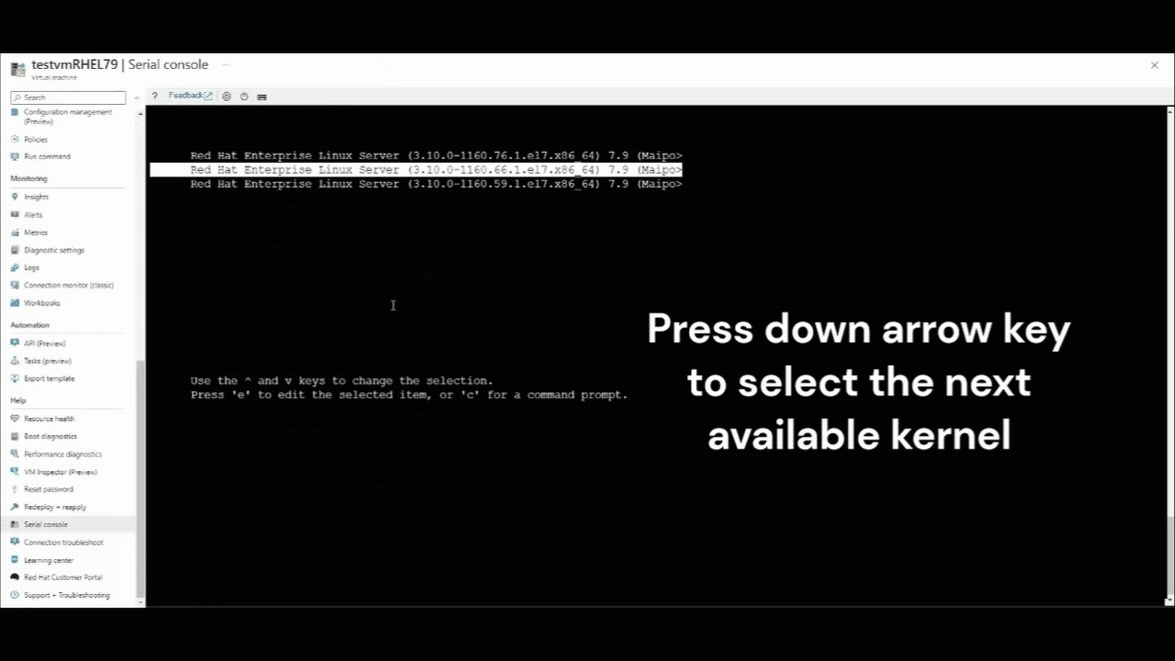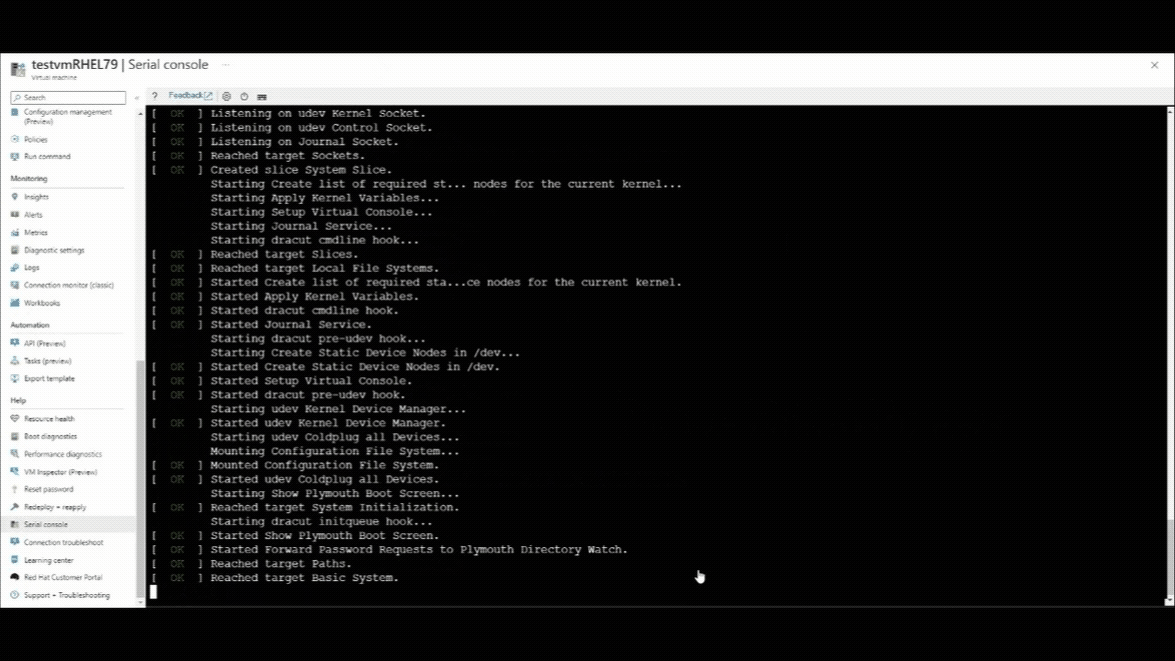
GRUB_DEFAULT根据手动更改默认内核版本中的指示,更改 /etc/default/grub 文件中的变量。 这是一项永久性更改。

注意
如果 GRUB 菜单中只列出了一个内核版本,请按照 脱机故障排除方法从修复 VM 中排查 此问题。
使用修复 VM (ALAR 脚本)
在 Azure Cloud Shell 中运行以下 bash 命令以创建修复 VM。 有关详细信息,请参阅 使用 Azure Linux 自动修复(ALAR)修复 Linux VM - 内核选项。
az vm repair create --verbose -g $RGNAME -n $VMNAME --repair-username rescue --repair-password 'password!234' --copy-disk-name repairdiskcopy运行以下命令,将损坏的内核替换为以前安装的版本:
az vm repair run --verbose -g $RGNAME -n $VMNAME --run-id linux-alar2 --parameters kernel --run-on-repair az vm repair restore --verbose -g $RGNAME -n $VMNAME
注意
如果系统中只安装了一个内核版本,请按照 脱机故障排除方法从修复 VM 中排查 此问题。
手动更改默认内核版本
若要从修复 VM(在 chroot 内部)或正在运行的 VM 上修改默认内核版本,请执行以下步骤:
注意
如果内核降级回滚完成,请选择最新的内核版本,而不是较旧的内核版本。
RHEL 7、Oracle Linux 7 和 CentOS 7
通过运行以下命令之一验证 GRUB 配置文件中的可用内核列表:
第 1 代 VM:
cat /boot/grub2/grub.cfg | grep menuentry第 2 代 VM:
cat /boot/efi/EFI/*/grub.cfg | grep menuentry
通过运行以下命令设置新的默认内核并指定相应的内核标题:
# grub2-set-default 'Red Hat Enterprise Linux Server, with Linux 3.10.0-123.el7.x86_64'注意
替换为
Red Hat Enterprise Linux Server, with Linux 3.10.0-123.el7.x86_64相应的菜单项标题。运行以下命令验证新的默认内核是否为所需内核:
grub2-editenv list请确保将 /etc/default/grub 文件中变量的值
GRUB_DEFAULT设置为saved。 若要对其进行修改,请确保 重新生成 GRUB 配置文件 以应用更改。
RHEL 8/9 和 CentOS 8
运行以下命令列出可用的内核:
ls -l /boot/vmlinuz-*运行以下命令设置新的默认内核:
grubby --set-default /boot/vmlinuz-4.18.0-372.19.1.el8_6.x86_64注意
替换为
4.18.0-372.19.1.el8_6.x86_64相应的内核版本。运行以下命令验证新的默认内核是否为所需内核:
grubby --default-kernel
SLES 12/15、Ubuntu 18.04/20.04
运行以下命令列出 GRUB 配置文件中的可用内核:
第 1 代 VM:
SLES 12/15:
cat /boot/grub2/grub.cfg | grep menuentryUbuntu 18.04/20.04:
cat /boot/grub/grub.cfg | grep menuentry
第 2 代 VM:
cat /boot/efi/EFI/*/grub.cfg | grep menuentry
通过修改 /etc/default/grub 文件中变量的值
GRUB_DEFAULT来设置新的默认内核。 对于系统中安装的最新内核版本,默认值为 0。 下一个可用内核设置为“1>2”。vi /etc/default/grub GRUB_DEFAULT="1>2"注意
有关如何配置
GRUB_DEFAULT变量的详细信息,请参阅 SUSE 启动加载程序 GRUB2 和 Ubuntu Grub2/Setup。 作为参考:顶级菜单项值为 0,第一个顶级子菜单值为 1,每个嵌套菜单值以 0 开头。 例如,“1>2”是第一个子菜单的第三个菜单项。重新生成 GRUB 配置文件以应用更改。 按照重新安装 GRUB 中的 说明,为相应的 Linux 分发版和 VM 生成重新生成 GRUB 配置文件 。
内核恐慌 - 未同步:VFS:无法在未知块上装载根 fs(0,0)
发生此错误的原因是最近的系统更新(内核)。 它最常出现在基于 RHEL 的分发版中。 可以从 Azure 串行控制台识别此问题。 你将看到以下任何错误消息:
“内核恐慌 - 未同步:VFS:无法在未知块(0,0)上装载根 fs”
[ 301.026129] Kernel panic - not syncing: VFS: Unable to mount root fs on unknown-block(0,0) [ 301.027122] CPU: 0 PID: 1 Comm: swapper/0 Tainted: G ------------ T 3.10.0-1160.36.2.el7.x86_64 #1 [ 301.027122] Hardware name: Microsoft Corporation Virtual Machine/Virtual Machine, BIOS 090008 12/07/2018 [ 301.027122] Call Trace: [ 301.027122] [<ffffffff82383559>] dump_stack+0x19/0x1b [ 301.027122] [<ffffffff8237d261>] panic+0xe8/0x21f [ 301.027122] [<ffffffff8298b794>] mount_block_root+0x291/0x2a0 [ 301.027122] [<ffffffff8298b7f6>] mount_root+0x53/0x56 [ 301.027122] [<ffffffff8298b935>] prepare_namespace+0x13c/0x174 [ 301.027122] [<ffffffff8298b412>] kernel_init_freeable+0x222/0x249 [ 301.027122] [<ffffffff8298ab28>] ? initcall_blcklist+0xb0/0xb0 [ 301.027122] [<ffffffff82372350>] ? rest_init+0x80/0x80 [ 301.027122] [<ffffffff8237235e>] kernel_init+0xe/0x100 [ 301.027122] [<ffffffff82395df7>] ret_from_fork_nospec_begin+0x21/0x21 [ 301.027122] [<ffffffff82372350>] ? rest_init+0x80/0x80 [ 301.027122] Kernel Offset: 0xc00000 from 0xffffffff81000000 (relocation range: 0xffffffff80000000-0xffffffffbfffffff)“error: file '/initramfs-*.img' not found”
error:找不到文件“/initramfs-3.10.0-1160.36.2.el7.x86_64.img”。
此类错误表示未生成 initramfs 文件,GRUB 配置文件在修补过程后缺少 initrd 条目,或者 GRUB 手动配置错误。
在重新启动服务器之前,我们建议通过运行以下命令之一来验证 GRUB 配置和 /boot 内容。 请务必确保完成更新,并且没有缺少 initramfs 文件。
基于 BIOS - Gen1 系统
# ls -l /boot # cat /boot/grub2/grub.cfg基于 UEFI - Gen2 系统
# ls -l /boot # cat /boot/efi/EFI/*/grub.cfg
使用 Azure 修复 VM ALAR 脚本重新生成缺少的 initramfs
使用 Azure Cloud Shell 运行以下 Bash 命令行来创建修复 VM。 有关详细信息,请参阅 使用 Azure Linux 自动修复(ALAR)修复 Linux VM - initrd 选项。
az vm repair create --verbose -g $RGNAME -n $VMNAME --repair-username rescue --repair-password 'password!234' --copy-disk-name repairdiskcopy重新生成 initrd/initramfs 映像,如果缺少 initrd 条目,则重新生成 GRUB 配置文件。 为此,请运行以下命令:
az vm repair run --verbose -g $RGNAME -n $VMNAME --run-id linux-alar2 --parameters initrd --run-on-repair az vm repair restore --verbose -g $RGNAME -n $VMNAME执行还原命令后,重启原始 VM 并验证它是否能够启动。
手动重新生成缺少 initramfs
重要
确定启动问题的特定内核版本。 可以从相应的内核恐慌错误中提取版本信息。
请参阅以下屏幕截图作为示例。 内核恐慌错误显示内核版本为“3.10.0-1160.59.1.el7.x86_64”:
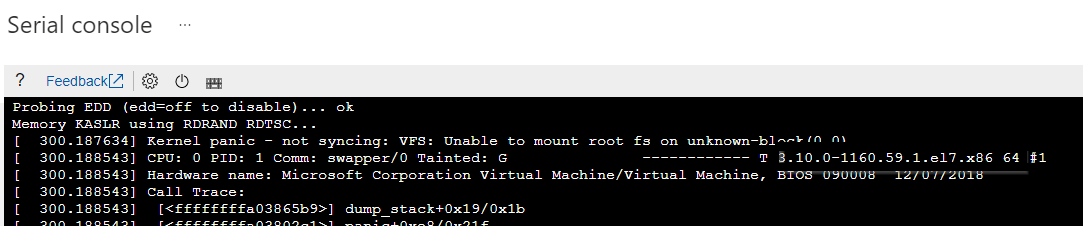
通过运行以下命令之一重新生成缺少的 initramfs 文件:
RHEL/CentOS/Oracle Linux 7/8
sudo depmod -a 3.10.0-1160.59.1.el7.x86_64 sudo dracut -f /boot/initramfs-3.10.0-1160.59.1.el7.x86_64.img 3.10.0-1160.59.1.el7.x86_64重要
替换为
3.10.0-1160.59.1.el7.x86_64相应的内核版本。SLES 12/15
sudo depmod -a 5.3.18-150300.38.53-azure sudo dracut -f /boot/initrd-5.3.18-150300.38.53-azure 5.3.18-150300.38.53-azure重要
替换为
5.3.18-150300.38.53-azure相应的内核版本。Ubuntu 18.04
sudo depmod -a 5.4.0-1077-azure sudo mkinitramfs -k -o /boot/initrd.img-5.4.0-1077-azure重要
替换为
5.4.0-1077-azure相应的内核版本。
重新生成 GRUB 配置文件。 按照重新安装 GRUB 中的说明,为相应的 Linux 分发版和 VM 生成重新生成 GRUB 配置文件
如果从修复 VM 执行上述步骤,请按照脱机故障排除中的步骤 3 进行操作。 如果从 Azure 串行控制台执行上述步骤,请遵循 联机故障排除 方法。
通过最新的内核版本重启 VM。
内核恐慌 - 未同步:尝试终止 init
从 Azure 串行控制台中识别此问题。 你将看到如下所示的输出:
dracut Warning: Boot has failed. To debug this issue add "rdshell" to the kernel command line.
Kernel panic - not syncing: Attempted to kill init!
Pid: 1, comm: init Not tainted 2.6.32-754.17.1.el6.x86_64 #1
Call Trace:
[<ffffffff81558bfa>] ? panic+0xa7/0x18b
[<ffffffff81130370>] ? perf_event_exit_task+0xc0/0x340
[<ffffffff81086433>] ? do_exit+0x853/0x860
[<ffffffff811a33b5>] ? fput+0x25/0x30
[<ffffffff81564272>] ? system_call_after_swapgs+0xa2/0x152
[<ffffffff81086498>] ? do_group_exit+0x58/0xd0
[<ffffffff81086527>] ? sys_exit_group+0x17/0x20
[<ffffffff81564357>] ? system_call_fastpath+0x35/0x3a
[<ffffffff8156427e>] ? system_call_after_swapgs+0xae/0x152
这种内核崩溃是由于以下可能的原因造成的:
有关原因详细信息和解决方案,请参阅以下部分。 确保从 chroot 环境中的修复/救援 VM 执行命令,如脱机故障排除中的指示。
缺少重要文件和目录
由于人为错误,缺少重要的 Linux 文件和目录。 例如,文件被意外删除或文件系统损坏。
将 OS 磁盘的副本附加到修复 VM 并使用 chroot 装载相应的文件系统后,验证 OS 磁盘内容。 可以将输出与运行同一 OS 版本的工作 VM 中的输出进行比较。
ls -l / ls -l /usr/lib ls -l /usr/lib64 ls -lR / | more从备份还原缺少的文件。 有关详细信息,请参阅 从 Azure 虚拟机备份恢复文件。 根据缺少的文件数,执行完整 VM 还原可能更好。 有关详细信息,请参阅如何还原 Azure 门户 中的 Azure VM 数据。
缺少重要的系统核心库和包
重要系统核心库、文件或包将从系统中删除或已损坏。 若要解决此问题,请重新安装受影响的库、文件或包。 此解决方案适用于基于 RPM 的分发,例如 Red Hat/CentOS/SUSE VM。 对于其他 Linux 分发版,建议 从备份还原 VM。
若要执行重新安装,请执行以下步骤:
使用与受影响 VM 相同的 OS 版本和生成的原始映像创建救援 VM。
访问救援 VM 中的 chroot 环境以解决问题。
sudo chroot /rescue命令输出将指示哪个库丢失或损坏,如下所示:
/bin/bash: error while loading shared libraries: libc.so.6: cannot open shared object file: No such file or directory验证所有系统包及其在救援 VM 中的相应状态。 将输出与运行同一 OS 版本的正常运行的 VM 进行比较。
sudo rpm --verify --all --root=/rescue下面是该命令输出的示例:
error: Failed to dlopen /usr/lib64/rpm-plugins/systemd_inhibit.so /lib64/librt.so.1: undefined symbol: __pthread_attr_copy, version GLIBC_PRIVATE S.5....T. c /etc/dnf/dnf.conf S.5....T. c /etc/ssh/sshd_config .M....... /boot/efi/EFI/BOOT/BOOTX64.EFI .M....... /boot/efi/EFI/BOOT/fbx64.efi .M....... /boot/efi/EFI/redhat/BOOTX64.CSV .M....... /boot/efi/EFI/redhat/mmx64.efi .M....... /boot/efi/EFI/redhat/shimx64-redhat.efi .M....... /boot/efi/EFI/redhat/shimx64.efi missing /run/motd.d .M....... g /var/spool/anacron/cron.daily .M....... g /var/spool/anacron/cron.monthly .M....... g /var/spool/anacron/cron.weekly missing /lib64/libc-2.28.so <------- .M....... /boot/efi/EFI/redhat S.5....T. c /etc/security/pwquality.conf输出行
missing /lib64/libc-2.28.so与步骤 2 中的上一个错误相关,并指示 缺少 libc-2.28.so 包。 但是, 可以修改 libc-2.28.so 包。 在这种情况下,输出将显示.M.....而不是missing。 libc-2.28.so 包在以下步骤中作为示例引用。在救援 VM 中,验证哪个包包含库 /lib64/libc-2.28.so。
sudo rpm -qf /lib64/libc-2.28.soglibc-2.28-127.0.1.el8.x86_64注意
输出将显示需要重新安装的包,包括包名称和版本。 包版本可能与受影响的 VM 上安装的版本不同。
在受影响的 VM 中,验证已安装哪个版本的 glibc 包。
sudo rpm -qa --all --root=/rescue | grep -i glibcglibc-common-2.28-211.0.1.el8.x86_64 glibc-gconv-extra-2.28-211.0.1.el8.x86_64 glibc-2.28-211.0.1.el8.x86_64 <---- glibc-langpack-en-2.28-211.0.1.el8.x86_64下载包 glibc-2.28-211.0.1.el8.x86_64。 可以使用包管理工具(例如
yumdownloader或zypper install --download-only <packagename>取决于正在运行的 OS)从 OS 供应商的官方网站或救援 VM 下载它。下面是使用
yumdownloader该工具的示例:cd /tmp sudo yumdownloader glibc-2.28-211.0.1.el8.x86_64Last metadata expiration check: 0:03:24 ago on Thu 25 May 2023 02:36:25 PM UTC. glibc-2.28-211.0.1.el8.x86_64.rpm 8.7 MB/s | 2.2 MB 00:00在救援 VM 中重新安装受影响的包。
sudo rpm -ivh --root=/rescue /tmp/glibc-*.rpm --replacepkgs --replacefileswarning: /tmp/glibc-2.28-211.0.1.el8.x86_64.rpm: Header V3 RSA/SHA256 Signature, key ID ad986da3: NOKEY Verifying... ################################# [100%] Preparing... ################################# [100%] Updating / installing... 1:glibc-2.28-211.0.1.el8 ################################# [100%]访问救援 VM 中的 chroot 环境以验证重新安装。
sudo chroot /rescue关闭救援 VM 并将 OS 磁盘交换到受影响的 VM。
文件权限错误
由于人为错误(例如,有人在 chmod 777 或其他重要的 OS 文件系统上运行 / )而修改了系统范围的文件权限。 若要解决此问题,请还原文件权限。 此解决方案适用于基于 RPM 的分发,例如 Red Hat/CentOS/SUSE VM。 对于其他 Linux 分发版,建议 从备份还原 VM。
若要还原文件权限,请在将 OS 磁盘的副本附加到修复 VM 并使用 chroot 装载相应的文件系统后运行以下命令:
rpm -a --setperms
rpm --setugids --all
chmod u+s /bin/sudo
chmod 660 /etc/sudoers.d/*
chmod 644 /etc/ssh/*.pub
chmod 640 /etc/ssh/*.key
注意
不要在运行生产系统上运行此命令。
如果在手动恢复相应的文件权限后仍然存在此问题,请从备份执行还原。
缺少分区
/usr如果、/opt、/var、/home/tmp和/文件系统分布在不同的分区中,由于分区级别存在问题,数据可能不可访问,这可能是由于分区调整操作或其他分区时出错造成的。
在此方案中,如果记录原始分区表布局,并且每个原始分区的起始和结束扇区完全相同,并且不会对系统进行进一步修改(如创建新的文件系统),使用与 fdisk(MBR 分区表)或 gdisk(GPT 分区表)等工具相同的原始布局重新创建分区,以获取对缺少文件系统的访问权限。
如果此方法不起作用,请从备份执行还原。
SELinux 问题
错误的 SELinux 权限可能会阻止系统访问重要文件。 若要解决此问题,请执行以下步骤:
若要验证系统是否因 SELinux 权限错误而出现问题,请通过将 selinux=0 内核选项添加到 GRUB linux16 行来启动禁用 SELinux 的系统。
如果系统能够启动,请运行以下命令,在启动时触发 SELinux relabel 并重新启动系统:
touch /.autorelabel如果 VM 仍无法启动,请从备份中执行完整 VM 还原。 有关详细信息,请参阅如何还原 Azure 门户 中的 Azure VM 数据。
其他与内核相关的启动问题
本文介绍 Azure 中标识的最常见 Linux 内核恐慌。 有关常见内核恐慌方案的详细信息,请参阅 Azure Linux VM 中的内核恐慌 - 常见内核恐慌事件。
还有其他一些重要的内核崩溃可能导致无启动或无安全 shell (SSH) 方案。
确保按照脱机故障排除中的说明,在 chroot 环境中执行修复 VM 中的任何命令。 如果系统已通过以前的内核版本启动,也可以使用根特权从原始 VM 执行这些命令,也可以sudo按照联机故障排除中的说明执行这些命令。
最近的内核升级
如果内核在最近的内核升级后崩溃,请通过以前的内核版本启动 VM。 有关详细信息,请参阅 旧版内核上的启动系统。
还可以检查 Linux 分发供应商是否已经发布了较新的内核版本并安装它。 有关如何安装最新内核版本的详细信息,请参阅 内核更新过程。
最近的内核降级
如果内核在最近内核降级后崩溃,请返回最新安装的内核。 还可以检查 Linux 分发供应商是否已经发布了较新的内核版本并安装它。 有关如何安装最新内核版本的详细信息,请参阅 内核更新过程。
若要通过最新的内核版本启动系统,请手动按照“更改默认内核版本”中的说明操作,但选择 GRUB 菜单中列出的第一个内核。 在手动修改中,可以将值设置为 GRUB_DEFAULT 0 并重新生成相应的 GRUB 配置文件。
内核模块更改
可能会遇到与新内核模块或缺少内核模块相关的内核恐慌。 若要获取导致问题的特定内核模块的详细信息(如果有),请检查相应的内核恐慌跟踪。
若要验证加载的内核模块和 /etc/modprobe.d/*.conf 文件中禁用的模块,请运行以下命令之一:
RHEL/CentOS/Oracle Linux 7/8
lsinitrd /boot/initramfs-3.10.0-1160.59.1.el7.x86_64.img lsmod cat /etc/modprobe.d/*.conf重要
替换为
3.10.0-1160.59.1.el7.x86_64相应的内核版本。SLES 12/15
lsinitrd /boot/initrd-5.3.18-150300.38.53-azure lsmod cat /etc/modprobe.d/*.conf重要
替换为
5.3.18-150300.38.53-azure相应的内核版本。Ubuntu 18.04
lsinitramfs /boot/initrd.img-5.4.0-1077-azure lsmod cat /etc/modprobe.d/*.conf重要
替换为
5.4.0-1077-azure相应的内核版本。
若要删除任何特定的内核模块,请运行以下命令并 根据需要重新生成 initramfs 。
rmmod <kernel_module_name>
如果系统服务使用特定的内核模块,请通过运行 systemctl disable <serviceName> 或 systemctl stop <serviceName> 命令禁用它。
操作系统最近配置更改
确定任何可能导致问题的最近内核配置更改。 若要解决问题,请调整这些设置或回滚配置更改。
运行以下命令,查找在以下任何文件中配置的持久性内核参数:
cat /etc/systctl.conf
cat /etc/sysctl.d/*
运行以下命令以分析当前内核参数及其当前值:
sysctl -a
注意
在正在运行的系统上运行此命令,而不是从 chroot 环境运行此命令。
可能缺少的文件
有关此类问题的详细信息,请参阅 缺少重要文件和目录。
文件权限错误
有关此类问题的详细信息,请参阅 错误的文件权限。
缺少分区
有关此类问题的详细信息,请参阅 “缺少分区”。
内核错误
从 Azure 串行控制台中识别此问题。 此类问题将类似于以下输出:
[5275698.017004] kernel BUG at XXX/YYY.c:72!
[5275698.017004] invalid opcode: 0000 [#1] SMP
此类内核崩溃与内核 bug 或第三方内核 bug 相关联。
若要修复内核 bug,请使用内核 BUG 字符串搜索供应商知识库,并在系统运行的相应内核版本中查找已知问题。 下面是一些重要的供应商资源:
-
此工具用于帮助诊断内核崩溃。 输入文本、 vmcore-dmesg.txt或文件(包括一个或多个内核 oops 消息)时,它将引导你诊断内核崩溃问题。
-
若要访问 Red Hat 资源,请将你的 Microsoft Azure 和 Red Hat 帐户相链接。 有关详细信息,请参阅 Microsoft Azure 客户如何访问 Red Hat 客户门户。
我们建议将所有系统保持最新,以排除任何可能已在最新内核版本中修复的 bug。 有关详细信息,请参阅内核更新过程。
如果需要供应商进一步分析,请配置并启用 kdump 以生成核心转储:
内核更新过程
若要安装最新的可用内核版本,请运行以下命令之一:
RHEL/CentOS/Oracle Linux
yum update kernelSLES 12/15
zypper refresh zypper update kernel*Ubuntu 18.04/20.04
apt update apt install linux-azure
若要重新安装特定的内核版本,请运行以下命令之一。 请确保未通过尝试重新安装的同一内核版本启动。 有关详细信息,请参阅 旧版内核上的启动系统。
RHEL/CentOS/Oracle Linux
yum reinstall kernel-3.10.0-1160.59.1.el7.x86_64重要
替换为
3.10.0-1160.59.1.el7.x86_64相应的内核版本。SLES 12/15
zypper refresh zypper install -f kernel-azure-5.3.18-150300.38.75.1.x86_64重要
替换为
kernel-azure-5.3.18-150300.38.75.1.x86_64相应的内核版本。Ubuntu 18.04/20.04
apt update apt install --reinstall linux-azure=5.4.0.1091.68重要
替换为
5.4.0.1091.68相应的内核版本。
若要更新系统并应用最新的可用更改,请运行以下命令之一:
RHEL/CentOS/Oracle Linux
yum updateSLES 12/15
zypper refresh zypper updateUbuntu 18.04/20.04
apt update apt upgrade
内核恐慌可能与以下任何项相关。 有关详细信息,请参阅 运行时内核崩溃。
- 应用程序工作负荷更改。
- 应用程序开发或应用程序 bug。
- 与性能相关的问题,等等。
后续步骤
如果特定的启动错误不是内核相关的启动问题,请参阅排查 Azure Linux 虚拟机启动错误,以获取进一步的故障排除选项。
联系我们寻求帮助
如果你有任何疑问或需要帮助,请创建支持请求或联系 Azure 社区支持。 你还可以将产品反馈提交到 Azure 反馈社区。