排查 Azure Kubernetes 服务中的 API 服务器和 etcd 问题
本指南旨在帮助识别和解决在大型 Microsoft Azure Kubernetes 服务 (AKS) 部署中 API 服务器中可能遇到的任何不太可能的问题。
Microsoft已以 5,000 个节点和 200,000 个 Pod 的规模测试 API 服务器的可靠性和性能。 包含 API 服务器的群集能够自动横向扩展和交付 Kubernetes 服务级别目标(SLO)。 如果遇到高延迟或超时,可能是因为分布式 etc 目录(etcd)上存在资源泄漏,或者有问题的客户端有过多的 API 调用。
先决条件
Kubernetes kubectl 工具。 若要使用 Azure CLI 安装 kubectl,请运行 az aks install-cli 命令。
已启用并发送到 Log Analytics 工作区的 AKS 诊断日志(特别是 kube-audit 事件)。 若要确定日志是使用特定于资源模式还是 Azure 诊断模式收集的,请检查Azure 门户中的“诊断设置”边栏选项卡。
AKS 群集的标准层。 如果使用免费层,则 API 服务器和 etcd 包含有限的资源。 免费层中的 AKS 群集不提供高可用性。 这通常是 API 服务器和 etcd 问题的根本原因。
用于直接在 AKS 节点上运行命令的 kubectl-aks 插件,而无需使用 Kubernetes 控制平面。
基本运行状况检查
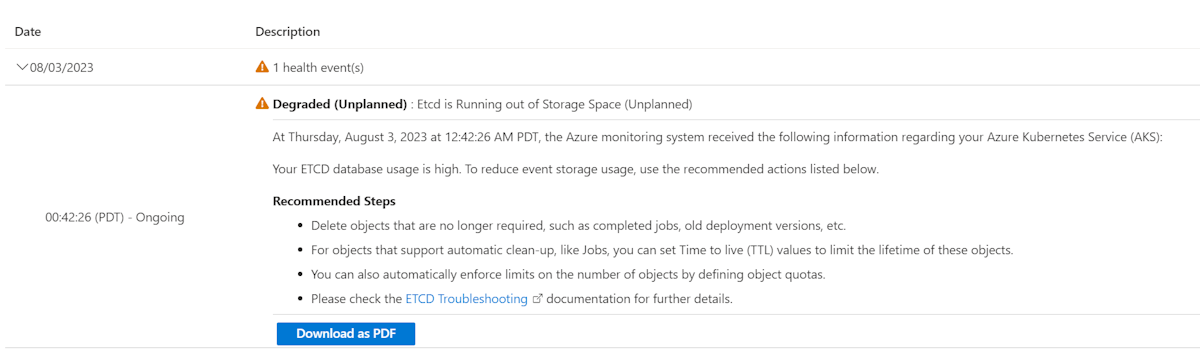
资源运行状况事件
AKS 为关键组件停机提供资源运行状况事件。 在继续操作之前,请确保资源运行状况中没有报告关键事件。
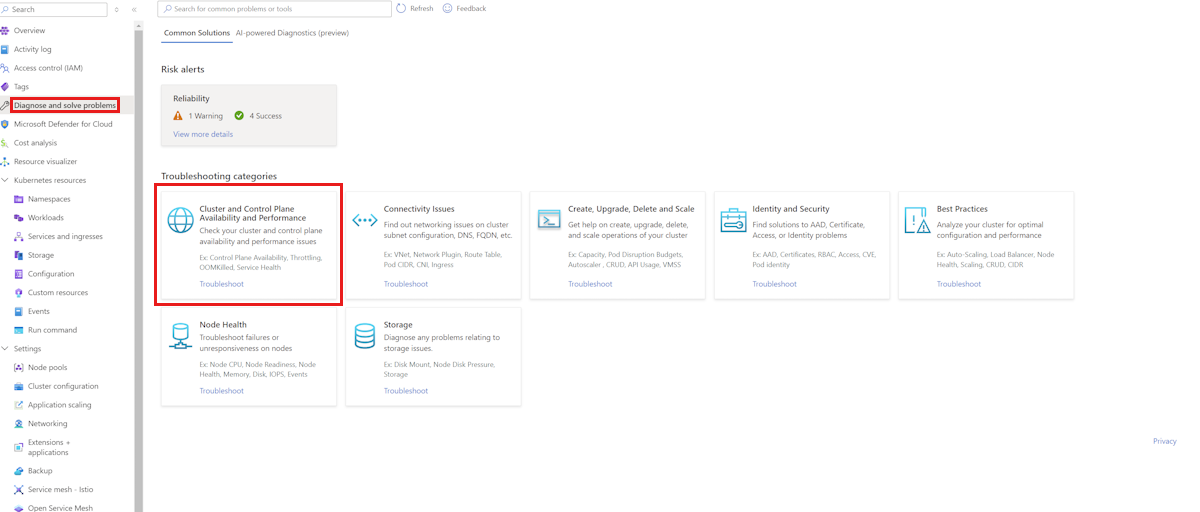
诊断和解决问题
AKS 提供群集 和控制平面可用性和性能的专用故障排除类别。


现象
下表概述了 API 服务器故障的常见症状:
| 症状 | 说明 |
|---|---|
| API 服务器的超时 | AKS API 服务器 SLA 中无法保证的频繁超时。 例如, kubectl 命令超时。 |
| 高延迟 | 导致 Kubernetes SLO 失败的高延迟。 例如,该 kubectl 命令需要 30 秒以上的时间列出 Pod。 |
处于状态或面临 Webhook 调用失败的 CrashLoopbackOff API 服务器 Pod |
验证是否没有任何阻止对 API 服务器的调用的自定义允许 Webhook(例如 Kyverno 策略引擎)。 |
故障排除清单
如果遇到高延迟时间,请按照以下步骤确定有问题的客户端和失败的 API 调用类型。
步骤 1:按请求数确定顶级用户代理
若要确定哪些客户端生成了大多数请求(并且可能是 API 服务器加载最多),请运行类似于以下代码的查询。 以下查询按发送的 API 服务器请求数列出前 10 个用户代理。
AKSAudit
| where TimeGenerated between(now(-1h)..now()) // When you experienced the problem
| summarize count() by UserAgent
| top 10 by count_
| project UserAgent, count_
注意
如果查询未返回任何结果,则可能选择了错误的表来查询诊断日志。 在特定于资源的模式下,数据将写入各个表,具体取决于资源的类别。 诊断日志将写入 AKSAudit 表。 在 Azure 诊断模式下,所有数据都写入 AzureDiagnostics 表。 有关详细信息,请参阅 Azure 资源日志。
尽管知道哪些客户端生成了最高的请求量,但单独生成高请求量可能不是问题的原因。 更好地指示每个客户端在 API 服务器上生成的实际负载是它们遇到的响应延迟。
步骤 2:识别和绘制每个用户代理 API 服务器请求的平均延迟
若要确定按时间图绘制的每个用户代理的 API 服务器请求的平均延迟,请运行以下查询:
AKSAudit
| where TimeGenerated between(now(-1h)..now()) // When you experienced the problem
| extend start_time = RequestReceivedTime
| extend end_time = StageReceivedTime
| extend latency = datetime_diff('millisecond', end_time, start_time)
| summarize avg(latency) by UserAgent, bin(start_time, 5m)
| render timechart
此查询是“按请求数标识顶级用户代理”部分中查询的后续操作。 它可能会让你更深入地了解一段时间内每个用户代理生成的实际负载。
提示
通过分析此数据,可以识别模式和异常,这些模式和异常可以指示 AKS 群集或应用程序出现问题。 例如,你可能会注意到特定用户遇到高延迟。 此方案可以指示导致 API 服务器或 etcd 上过多负载的 API 调用的类型。
步骤 3:识别给定用户代理的 API 调用错误
运行以下查询,针对给定客户端的不同资源类型对 API 调用的第 99 百分位 (P99) 延迟进行制表:
AKSAudit
| where TimeGenerated between(now(-1h)..now()) // When you experienced the problem
| extend HttpMethod = Verb
| extend Resource = tostring(ObjectRef.resource)
| where UserAgent == "DUMMYUSERAGENT" // Filter by name of the useragent you are interested in
| where Resource != ""
| extend start_time = RequestReceivedTime
| extend end_time = StageReceivedTime
| extend latency = datetime_diff('millisecond', end_time, start_time)
| summarize p99latency=percentile(latency, 99) by HttpMethod, Resource
| render table
此查询的结果可用于识别上游 Kubernetes SLO 失败的 API 调用类型。 在大多数情况下,有问题的客户端可能会对一组太大的对象或对象发出过多 LIST 的调用。 遗憾的是,没有硬性可伸缩性限制可用于指导用户了解 API 服务器可伸缩性。 API 服务器或 etcd 可伸缩性限制取决于 Kubernetes 可伸缩性阈值中解释的各种因素。
原因 1:网络规则阻止从代理节点到 API 服务器的流量
网络规则可以阻止代理节点和 API 服务器之间的流量。
若要验证配置错误的网络策略是否阻止了 API 服务器和代理节点之间的通信,请运行以下 kubectl-aks 命令:
kubectl aks config import \
--subscription <mySubscriptionID> \
--resource-group <myResourceGroup> \
--cluster-name <myAKSCluster>
kubectl aks check-apiserver-connectivity --node <myNode>
配置导入命令检索群集中所有节点的虚拟机规模集信息。 然后, check-apiserver-connectivity 命令使用此信息来验证 API 服务器与指定节点之间的网络连接,特别是其基础规模集实例的网络连接。
注意
如果命令的 check-apiserver-connectivity 输出包含 Connectivity check: succeeded 消息,则网络连接将不受阻碍。
解决方案 1:修复网络策略以删除流量阻塞
如果命令输出指示发生了连接失败,请重新配置网络策略,以便它不会不必要地阻止代理节点和 API 服务器之间的流量。
原因 2:冒犯客户端泄漏 etcd 对象并导致 etcd 速度变慢
一个常见问题是持续创建对象,而无需删除 etcd 数据库中未使用的对象。 当 etcd 处理任何类型的对象过多(超过 10,000 个)时,这可能会导致性能问题。 此类对象的更改的快速增加也可能导致超过 etcd 数据库大小(默认为 4 GB)。
若要检查 etcd 数据库使用情况,请导航到“诊断并解决Azure 门户中的问题。 通过在搜索框中搜索“etcd”来运行 Etcd 可用性问题诊断工具。 诊断工具显示使用情况明细和数据库总大小。

如果只想快速查看 etcd 数据库的当前大小(以字节为单位),请运行以下命令:
kubectl get --raw /metrics | grep -E "etcd_db_total_size_in_bytes|apiserver_storage_size_bytes|apiserver_storage_db_total_size_in_bytes"
注意
对于不同的 Kubernetes 版本,上一命令中的指标名称不同。 对于 Kubernetes 1.25 及更早版本,请使用 etcd_db_total_size_in_bytes。 对于 Kubernetes 1.26 到 1.28,请使用 apiserver_storage_db_total_size_in_bytes。
解决方案 2:为对象创建、删除对象或限制 etcd 中的对象生存期定义配额
若要防止 etcd 达到容量并导致群集停机,可以限制创建的最大资源数。 还可以减慢为资源实例生成的修订数。 若要限制可创建的对象数,可以 定义对象配额。
如果已标识不再使用但占用资源的对象,请考虑删除它们。 例如,可以删除已完成的作业以释放空间:
kubectl delete jobs --field-selector status.successful=1
对于支持 自动清理的对象,可以将生存时间(TTL)值设置为限制这些对象的生存期。 还可以标记对象,以便使用标签选择器批量删除特定类型的所有对象。 如果在 对象之间建立所有者引用 ,则删除父对象后,将自动删除任何依赖对象。
原因 3:有问题的客户端发出过多的 LIST 或 PUT 调用
如果确定 etcd 未重载太多对象,则有问题的客户端可能会对 API 服务器进行过多 LIST 或 PUT 调用。
解决方案 3a:优化 API 调用模式
请考虑优化客户端的 API 调用模式,以减少控制平面的压力。
解决方案 3b:限制控制平面压倒性的客户端
如果无法优化客户端,可以使用 Kubernetes 中的优先级和公平性 功能来限制客户端。 此功能可帮助保留控制平面的运行状况,并防止其他应用程序失败。
以下过程演示如何将有问题的客户端 LIST Pod API 设置为 5 个并发调用:
创建与 有问题的客户端的 API 调用模式匹配的 FlowSchema :
apiVersion: flowcontrol.apiserver.k8s.io/v1beta2 kind: FlowSchema metadata: name: restrict-bad-client spec: priorityLevelConfiguration: name: very-low-priority distinguisherMethod: type: ByUser rules: - resourceRules: - apiGroups: [""] namespaces: ["default"] resources: ["pods"] verbs: ["list"] subjects: - kind: ServiceAccount serviceAccount: name: bad-client-account namespace: default创建优先级较低的配置以限制客户端的错误的 API 调用:
apiVersion: flowcontrol.apiserver.k8s.io/v1beta2 kind: PriorityLevelConfiguration metadata: name: very-low-priority spec: limited: assuredConcurrencyShares: 5 limitResponse: type: Reject type: Limited观察 API 服务器指标中的限制调用。
kubectl get --raw /metrics | grep "restrict-bad-client"
原因 4:自定义 Webhook 可能会导致 API 服务器 Pod 中的死锁
自定义 Webhook(如 Kyverno)可能会导致 API 服务器 Pod 中的死锁。
检查与 API 服务器相关的事件。 你可能会看到类似于以下文本的事件消息:
发生内部错误:调用 webhook 失败“mutate.kyverno.svc-fail”:未能调用 Webhook:Post“https://kyverno-system-kyverno-system-svc.kyverno-system.svc:443/mutate/fail?timeout=10s":write unix @->/tunnel-uds/proxysocket: write: broken pipe: broken pipe
在此示例中,验证 Webhook 会阻止创建某些 API 服务器对象。 由于此方案可能在启动期间发生,因此无法创建 API 服务器和 Konnectivity Pod。 因此,Webhook 无法连接到这些 Pod。 此事件序列会导致死锁和错误消息。
解决方案 4:删除 Webhook 配置
若要解决此问题,请删除验证和改变 Webhook 配置。 若要在 Kyverno 中删除这些 Webhook 配置,请查看 Kyverno 故障排除文章。
第三方联系人免责声明
Microsoft 会提供第三方联系信息来帮助你查找有关本主题的其他信息。 此联系信息可能会更改,恕不另行通知。 Microsoft 不保证第三方联系信息的准确性。
第三方信息免责声明
本文中提到的第三方产品由 Microsoft 以外的其他公司提供。 Microsoft 不对这些产品的性能或可靠性提供任何明示或暗示性担保。
联系我们寻求帮助
如果你有任何疑问或需要帮助,请创建支持请求或联系 Azure 社区支持。 你还可以将产品反馈提交到 Azure 反馈社区。