选择适当的计算目标
在 Azure 机器学习中,计算目标 是运行作业的物理或虚拟计算机。
了解可用的计算类型
Azure 机器学习支持用于试验、训练和部署的多种计算类型。 通过具有多种类型的计算,可以根据需求选择最合适的计算目标类型。
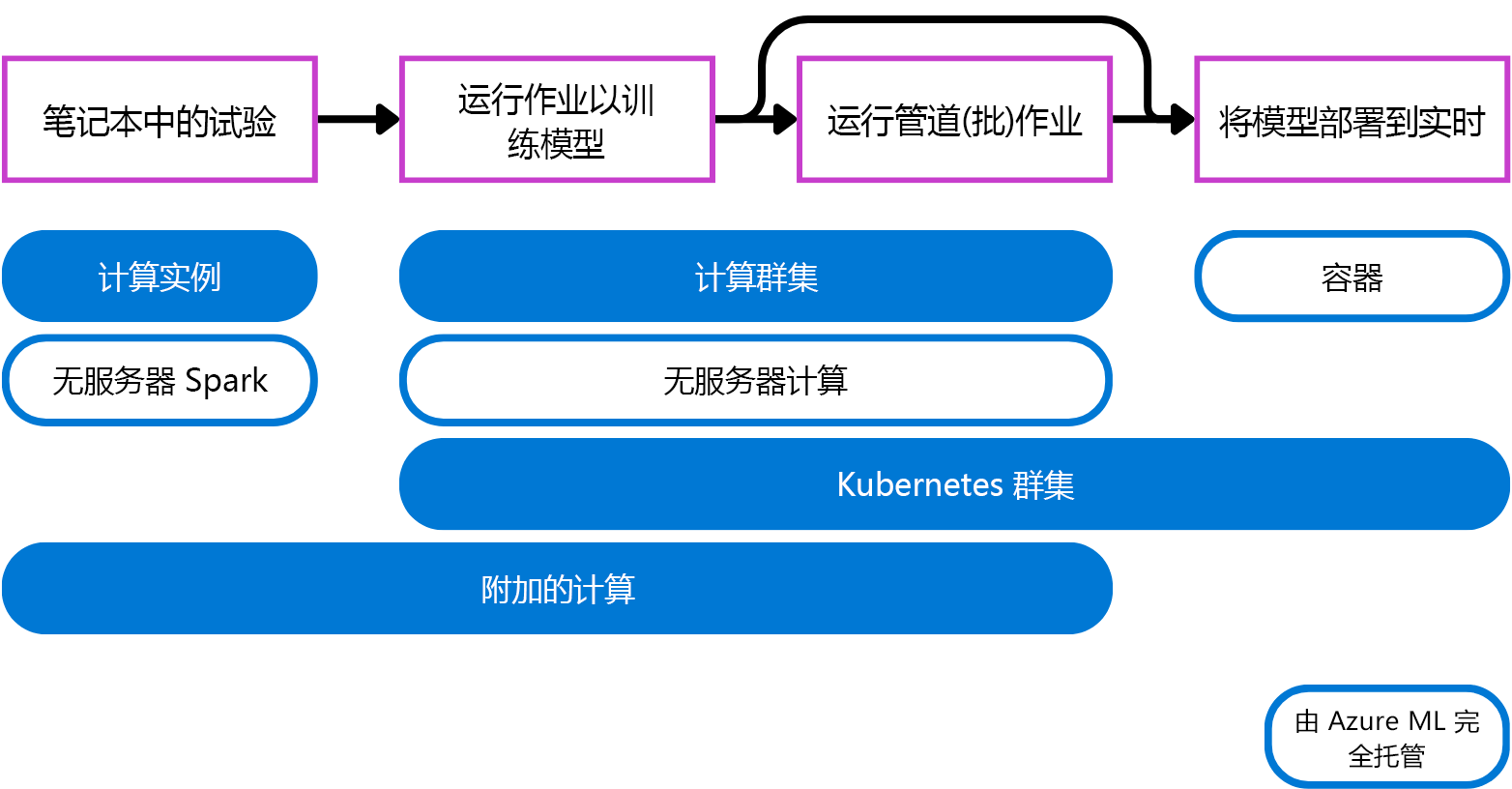
- 计算实例:行为类似于虚拟机,主要用于运行笔记本。 它非常适合 实验。
- 计算群集:自动纵向扩展或缩减以满足需求的虚拟机的多节点群集。 运行需要处理大量数据的脚本的经济高效方法。 群集还允许使用并行处理来分发工作负荷,并减少运行脚本所需的时间。
- Kubernetes 群集:基于 Kubernetes 技术的群集,让你能够更好地控制计算的配置和管理方式。 您可以将自托管的 Azure Kubernetes (AKS) 群集附加到云计算中,或者将 Arc Kubernetes 群集附加以支持本地工作负载。
- 附加的计算:允许将现有计算(如 Azure 虚拟机或 Azure Databricks 群集)附加到工作区。
- 无服务器计算:可用于训练作业的完全托管按需计算。
注意
Azure 机器学习提供创建和管理自己的计算或使用完全由 Azure 机器学习管理的计算的选项。
何时使用哪种类型的计算?
一般情况下,在使用计算目标时,可以遵循一些最佳做法。 若要了解如何选择适当的计算类型,提供了几个示例。 请记住,你使用的计算类型始终取决于你的特定情况。
选择用于试验的计算目标
假设你是一名数据科学家,你被要求开发一个新的机器学习模型。 你可能有一小部分训练数据,你可以使用这些数据进行试验。
在试验和开发期间,你更喜欢在 Jupyter 笔记本中工作。 笔记本体验更能受益于持续运行的计算资源。
许多数据科学家熟悉在本地设备上运行笔记本。 由 Azure 机器学习管理的云替代项是一个 计算实例。 或者,如果想要利用 Spark 的分布式计算能力,还可以选择 Spark 无服务器计算 在笔记本中运行 Spark 代码。
为生产选择计算目标
试验后,可以通过运行 Python 脚本来训练模型,以便为生产做好准备。 当想要随时间推移连续重新训练模型时,脚本将更易于自动执行和计划。 可以将脚本作为(管道)任务运行。
迁移到生产环境时,需要计算目标准备好处理大量数据。 使用的数据越多,机器学习模型就越好。
使用脚本训练模型时,需要按需计算目标。 计算群集 在需要执行脚本时会自动水平扩展,脚本执行完成后则会自动缩小规模。 如果您想要一种不需要创建和管理的替代方案,可以使用 Azure 机器学习的 无服务器计算。
选择用于部署的计算目标
使用模型生成预测时所需的计算类型取决于是要进行批量预测还是实时预测。
对于批处理预测,可以在 Azure 机器学习中运行管道作业。 计算目标(如计算群集和 Azure 机器学习的无服务器计算)非常适合按需且可缩放的管道作业。
需要实时预测时,需要一种连续运行的计算类型。 因此,实时部署受益于更轻量(因此更具成本效益)的计算。 容器非常适合实时部署。 将模型部署到托管联机终结点时,Azure 机器学习会创建和管理容器,以便运行模型。 或者,可以附加 Kubernetes 群集来管理必要的计算以生成实时预测。