探索解决方案体系结构
开始之前,我们来探索一下体系结构以了解所有要求。 将模型投入到生产意味着你需要缩放解决方案并与其他团队合作。 与数据科学家、数据工程师和基础结构团队一起,你决定使用以下方法:
- 所有数据都将存储在由数据工程师管理的 Azure Blob 存储中。
- 基础结构团队将创建必要的 Azure 资源,例如 Azure 机器学习工作区。
- 数据科学家将专注于内部循环:即开发和训练模型。
- 机器学习工程师将采用经过训练的模型,并将它部署在外部循环中。
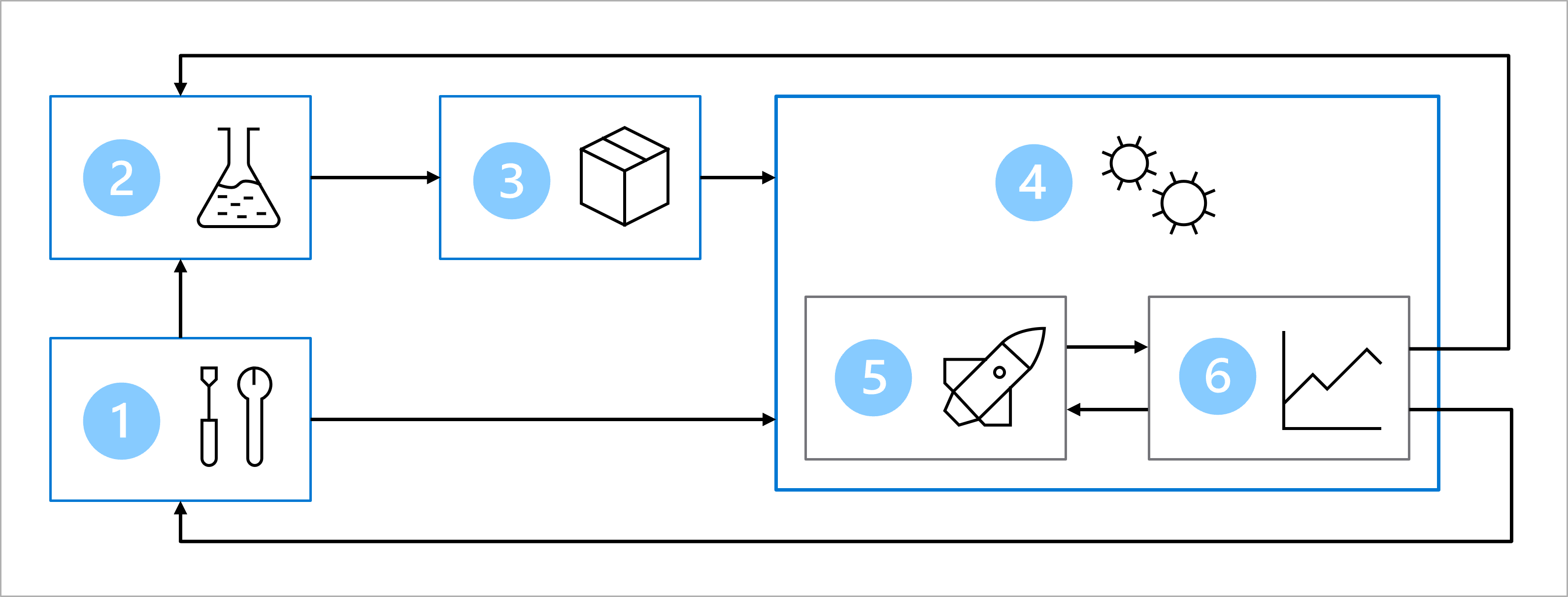
与更大的团队一起,你设计了一个实现机器学习操作 (MLOps) 的体系结构。
注意
此图是 MLOps 体系结构的简化表示形式。 若要查看更详细的体系结构,请浏览 MLOps (v2) 解决方案加速器中的各种用例。
MLOps 体系结构的主要目标是创建可靠且可重现的解决方案。 实现此目标包括以下内容:
- 设置:为解决方案创建所有必需的 Azure 资源。
- 模型开发(内部循环):浏览并处理数据来训练和评估模型。
- 持续集成:打包并注册模型。
- 模型部署(外部循环):部署模型。
- 持续部署:测试模型并提升到生产环境。
- 监视:监视模型和终结点性能。
此时,在项目中会创建 Azure 机器学习工作区,数据将存储在 Azure Blob 存储中,并且数据科学团队已训练了模型。
你希望通过将模型部署到生产环境,从内部循环和模型开发移动到外部循环。 因此,你需要将数据科学团队的输出转换为 Azure 机器学习中可靠且可重现的管道。
通过确保将所有代码存储为脚本并将脚本作为 Azure 机器学习作业执行,从而更轻松地自动执行模型训练并在将来重新训练模型。
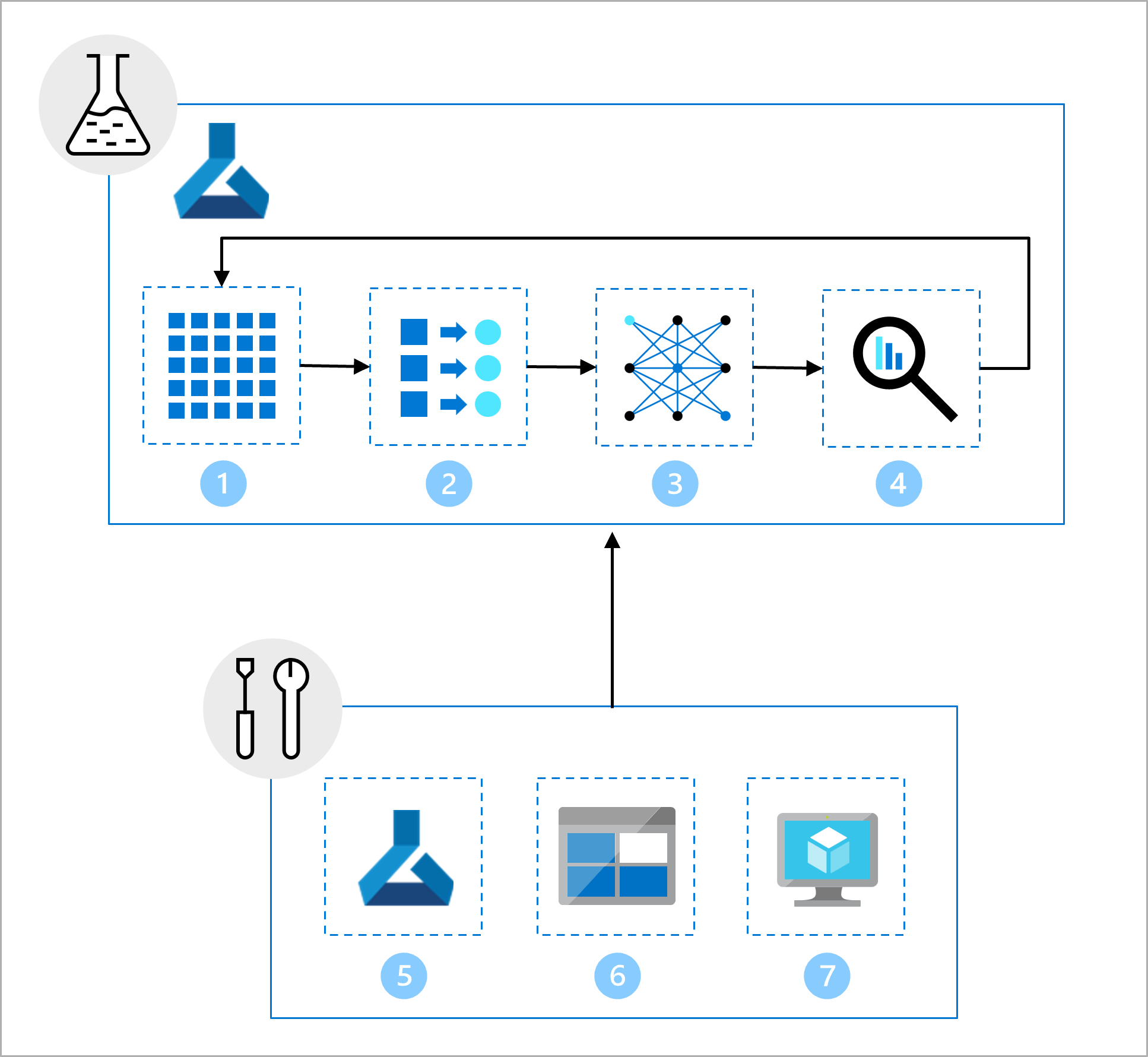
数据科学团队一直在着手模型开发的工作。 他们给了你一个 Jupyter 笔记本,其中包括以下任务:
- 读取和浏览数据。
- 执行特征工程。
- 定型模型。
- 评估模型。
在设置过程中,基础结构团队创建了:
- Azure 机器学习开发 (dev) 工作区,可供数据科学团队用于探索和试验。
- 工作区中的数据资产,引用了包含数据的 Azure Blob 存储中的文件夹。
- 运行笔记本和脚本所需的计算资源。
对于 MLOps,你的第一项任务是转换数据科学家手中的工作,以便可以轻松地自动执行模型开发。 虽然数据科学团队在 Jupyter 笔记本中工作,但你需要使用脚本并使用 Azure 机器学习作业来执行这些脚本。 作业的输入将为基础结构团队创建的数据资产,该资产指向连接到 Azure 机器学习工作区的 Azure Blob 存储上的数据。