了解 Spark
若要更好地了解如何在 Azure Databricks 中使用 Apache Spark 处理和分析数据,请务必了解底层体系结构。
高层次概述
从较高层面来说,Azure Databricks 服务在 Azure 订阅中启动和管理 Apache Spark 群集。 Apache Spark 群集是一组计算机,它们被视为单台计算机并处理从笔记本发出的命令的执行。 通过群集可处理要跨多台计算机并行化的数据,以提高规模和性能。 它们由 Spark 驱动程序节点和工作器节点组成。 驱动程序节点将工作发送到工作器节点,并指示它们从指定数据源中拉取数据。
在 Databricks 中,笔记本接口通常是驱动程序。 此驱动程序包含程序的主循环,并在群集上创建分布式数据集,然后将操作应用于这些数据集。 驱动程序通过 SparkSession 对象访问 Apache Spark,而不考虑部署位置。
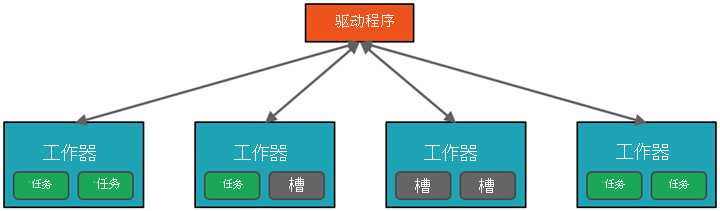
Microsoft Azure 管理群集,并根据使用情况和配置群集时所用的设置,在需要时自动缩放群集。 还可以启用自动终止功能,使 Azure 可以在非活动状态达到指定分钟数后终止群集。
Spark 作业详细信息
提交到群集的工作会根据需要拆分为多个独立作业。 这是在群集节点间分布工作的方式。 作业会进一步细分为任务。 作业的输入划分为一个或多个分区。 这些分区是每个槽的工作单元。 在任务之间,可能需要重新组织分区并通过网络进行共享。
Spark 高性能的秘诀是并行性。 垂直缩放(通过向单一计算机添加资源)受限于有限数量的 RAM、线程和 CPU 速度;但群集水平缩放,根据需要向群集添加新节点。
Spark 在两个级别上并行化作业:
- 第一级并行化是执行程序 - 在工作器节点上运行的 Java 虚拟机 (JVM),通常是每个节点一个实例。
- 第二级并行化是槽 - 其数量由每个节点的核心与 CPU 数量确定。
- 每个执行程序具有多个槽,并行化任务可以分配到这些槽。
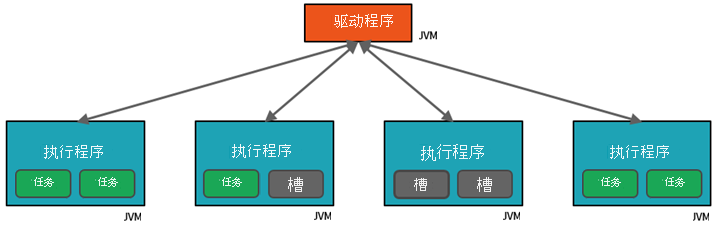
JVM 天然是多线程的,但是单个 JVM(如驱动程序上协调工作的 JVM)具有有限的上限。 通过将工作拆分为多个任务,驱动程序可以将工作单元分配给工作器节点上执行程序中的 *槽,以实现并行执行。 此外,驱动程序决定如何划分数据,以便可以分布数据来进行并行处理。 因此,驱动程序向每个任务分配一个数据分区,以便每个任务都知道要处理的数据片段。 启动后,每个任务都会提取分配给它的数据分区。
作业和阶段
根据正在执行的工作,可能需要多个并行作业。 每个作业分为多个阶段。 可将该作业类比为建造房子:
- 第一阶段是打好地基。
- 第二个阶段是砌墙。
- 第三阶段是建造屋顶。
尝试不按顺序执行这些步骤是没有意义的,并且实际上也不可行。 同样,Spark 将每项工作分成多个阶段,确保一切都按正确顺序执行。
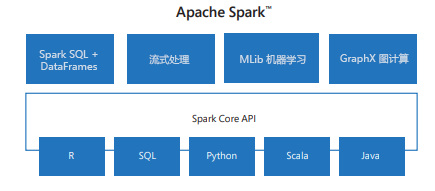
模块化
Spark 包括用于从 SQL 到流式处理和机器学习的任务的库,使其成为数据处理任务的工具。 一些 Spark 库包括:
- Spark SQL:用于处理结构化数据。
- SparkML:用于机器学习。
- GraphX:用于图形处理。
- Spark 流式处理:用于实时数据处理。
兼容性
Spark 可以在各种分布式系统上运行,包括 Hadoop YARN、Apache Mesos、Kubernetes 或 Spark 自己的群集管理器。 它还读取和写入到各种数据源,如 HDFS、Cassandra、HBase 和 Amazon S3。