评估分类模型
机器学习的很大一部分是关于评估模型工作情况的。 此评估发生在训练期间,帮助塑造模型,训练后,帮助我们判断模型是否可以在现实世界中使用。 分类模型需要评估,就像回归模型一样,尽管我们执行此评估的方式有时可能稍微复杂一些。
复习一下成本
请记住,在训练期间,我们会计算模型的表现有多糟糕,并将此称为成本或损失。例如,在线性回归中,我们经常使用称为均方误差 (MSE) 的指标。 MSE 的计算方式为比较预测和实际标签、计算差值的平方并取结果的平均值。 我们可以使用 MSE 来适应模型,并报告其运行情况。
用于分类的成本函数
分类模型将根据其输出概率(例如 40% 的雪崩几率)或最终标签(no avalanche 或 avalanche)进行判断。 在训练期间使用概率可能很有利。 模型中的细微变化将反映在概率变化中,即使它们不足以更改最终决策。 如果要估算模型的实际性能,对成本函数使用最终标签会更有用。 例如,在测试集上。 因为对于实际使用,我们将使用最终标签,而不是概率。
对数损失
对数损失是简单分类最常用的成本函数之一。 对数损失应用于输出概率。 与 MSE 类似,少量错误会导致较小的成本,而中等数量的错误会导致较大的成本。 对于正确答案为 0 (false) 的标签,我们绘制下图中的对数损失。
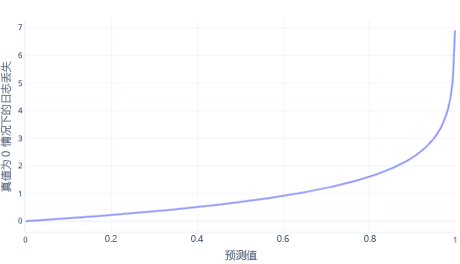
x 轴显示了可能的模型输出(概率从 0 到 1),y 轴显示了成本。 如果模型非常确信正确的响应为 0(例如,预测 0.1)。 则成本较低,因为在这种情况下,正确的响应为 0。 如果模型有把握地错误地预测结果(例如,预测 0.9),则成本会变得很高。 事实上,在 x=1 时,成本非常高,因此我们将此处的 x 轴裁剪为 0.999,使图形保持可读。
为什么不选择 MSE?
MSE 和对数损失是类似的指标。 逻辑回归支持对数损失有一些复杂原因,但还有一些更简单的原因。 例如,对数损失比 MSE 对错误答案的惩罚力度要强得多。 例如,在下图中,如果正确答案为 0,则高于 0.8 的预测比 MSE 的对数损失成本要高。
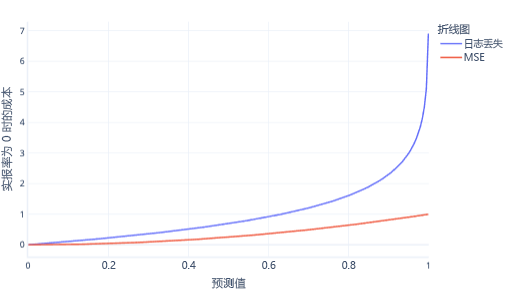
以这种方式拥有更高的成本有助于模型更快地学习,因为线的斜率更陡峭。 同样,对数损失有助于模型更确信地给出正确答案。 请注意,在上图中,小于 0.2 的值的 MSE 成本非常小,斜率几乎是水平的。 此关系会使接近正确的模型的训练速度变慢。 对于这些值,对数损失具有更陡峭的斜率,这有助于模型更快地学习。
成本函数的限制
使用单一成本函数对模型进行人工评估始终受到限制,因为它不会告诉你模型犯了什么样的错误。 例如,考虑我们的雪崩预测方案。 较高的对数损失值可能意味着模型在没有雪崩时反复预测雪崩。 或者它可能意味着反复地无法预测随后发生的雪崩。
为了更好地理解我们的模型,使用多个数字来评估它们是否运行良好会更容易。 我们在其他学习材料中涵盖此更大的主题,但我们将在以下练习中涉及到此主题。