使用 Spark 直观呈现数据
分析数据查询结果的最直观的方法之一是将其可视化为图表。 Azure Synapse Analytics 中的笔记本在用户界面中提供了一些基本的图表绘制功能,并且当无法通过该功能获取所需内容时,可以使用众多 Python 图形库之一在笔记本中创建和显示数据可视化效果。
使用内置的笔记本图表
在 Azure Synapse Analytics 的 Spark 笔记本中显示数据帧或运行 SQL 查询时,结果显示在代码单元下。 默认情况下,结果呈现为表格,但也可以将结果视图更改为图表,并使用图表属性来自定义图表的数据可视化方式,如下所示:
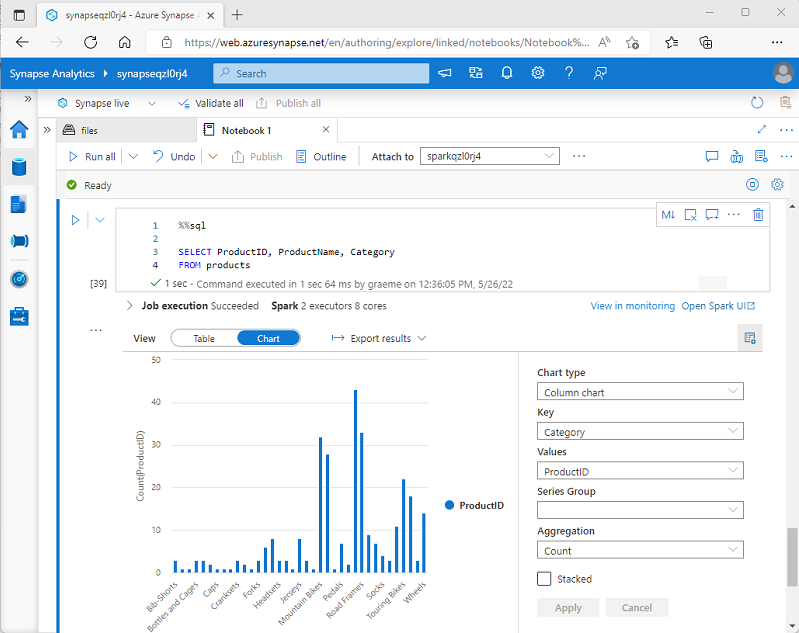
在处理不包含任何现有分组或聚合的查询结果并想以直观方式快速汇总数据时,笔记本中的内置图表功能非常有用。 如果想要更好地控制数据的格式设置方式或更好地显示查询中已聚合的值,应考虑使用图形包创建自己的可视化效果。
在代码中使用图形包
有许多图形包可用于在代码中创建数据可视化效果。 具体而言,Python 支持大量不同种类的包;其中大多数均基于基础 Matplotlib 库构建。 图形库的输出可以在笔记本中呈现,从而可以轻松将引入和操作数据的代码与内联数据可视化效果和标记单元格组合起来,以提供注释。
例如,可以使用以下 PySpark 代码对本模块前面探讨的假设产品数据进行聚合,并使用 Matplotlib 从聚合数据创建图表。
from matplotlib import pyplot as plt
# Get the data as a Pandas dataframe
data = spark.sql("SELECT Category, COUNT(ProductID) AS ProductCount \
FROM products \
GROUP BY Category \
ORDER BY Category").toPandas()
# Clear the plot area
plt.clf()
# Create a Figure
fig = plt.figure(figsize=(12,8))
# Create a bar plot of product counts by category
plt.bar(x=data['Category'], height=data['ProductCount'], color='orange')
# Customize the chart
plt.title('Product Counts by Category')
plt.xlabel('Category')
plt.ylabel('Products')
plt.grid(color='#95a5a6', linestyle='--', linewidth=2, axis='y', alpha=0.7)
plt.xticks(rotation=70)
# Show the plot area
plt.show()
Matplotlib 库要求数据位于 Pandas 数据帧而不是 Spark 数据帧中,因此使用了 toPandas 方法来转换数据帧。 然后代码创建一个具有指定大小的数字,并绘制具有一些自定义属性配置的条形图,然后显示生成的绘图。
代码生成的图表类似于下图:
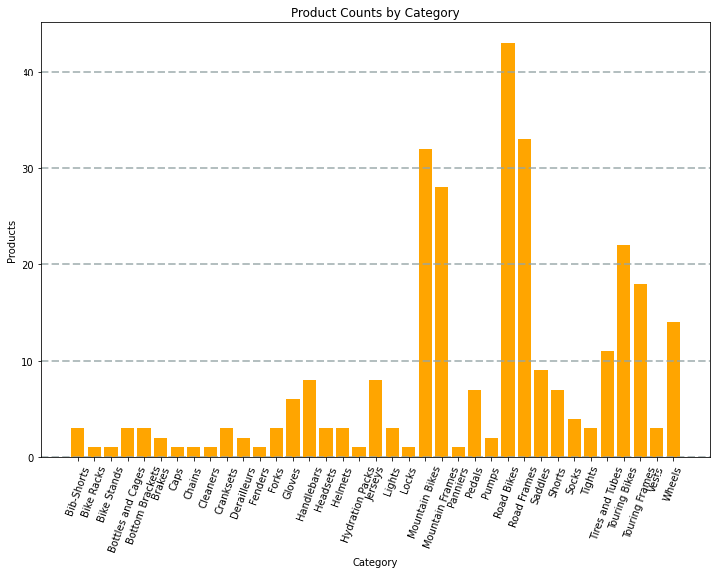
使用 Matplotlib 库可以创建多种图表:或如果需要,也可以使用其他库(如 Seaborn)创建高度自定义的图表。