了解 Apache Spark
Apache Spark 是分布式数据处理框架,通过协调群集中多个处理节点的工作,实现大规模数据分析。
Spark 的工作原理
Apache Spark 应用程序在群集上作为一组独立的进程运行,由主程序(称为驱动器程序)中的 SparkContext 对象进行协调。 SparkContext 连接到群集管理器,该管理器通过 Apache Hadoop YARN 的实现跨应用程序分配资源。 连接后,Spark 会获取群集中节点上的执行器来运行应用程序代码。
SparkContext 在群集节点上运行主函数和并行操作,然后收集操作的结果。 节点在文件系统中读取和写入数据,并将转换后的数据缓存为内存中的弹性分布式数据集 (RDD)。
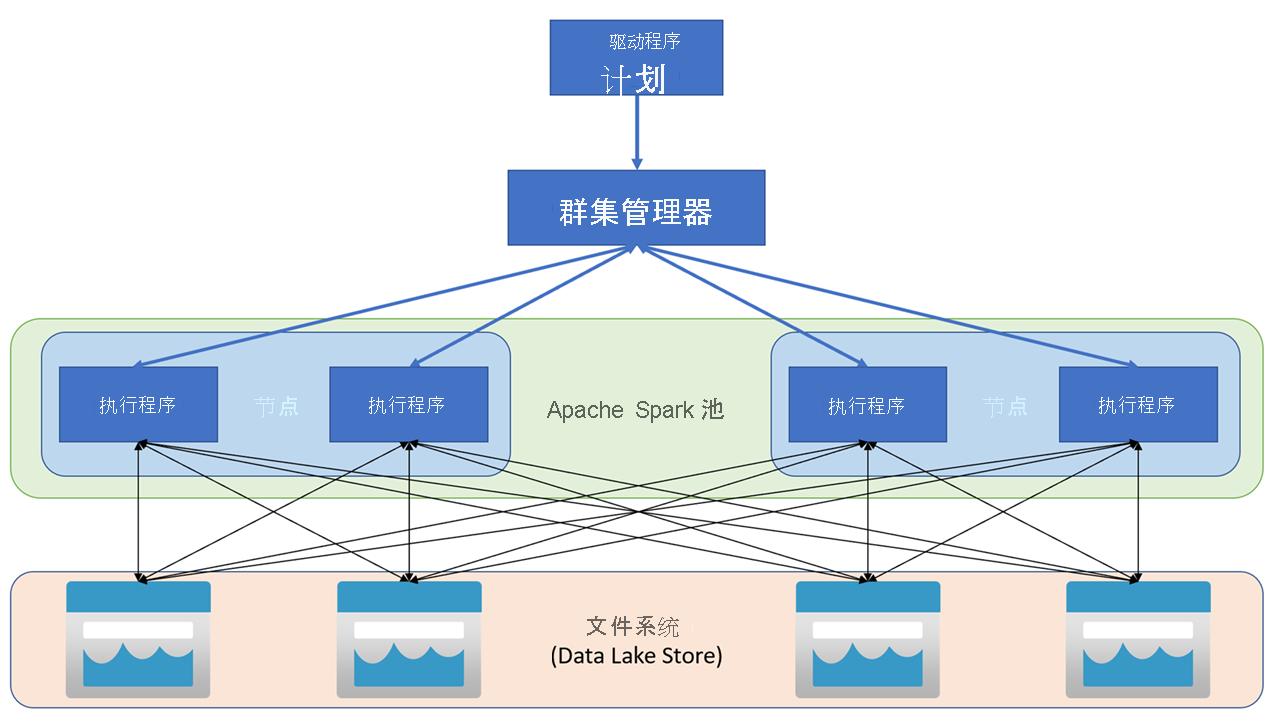
SparkContext 负责将应用程序转换为有向无环图 (DAG)。 该图由在节点上的执行程序进程内执行的各个任务构成。 每个应用程序获取自己的执行程序进程,这些进程在整个应用程序持续时间内保留,并以多个线程运行任务。
Azure Synapse Analytics 中的 Spark 池
在 Azure Synapse Analytics 中,群集作为 Spark 池实现,该池为 Spark 操作提供运行时。 可以使用 Azure 门户在 Azure Synapse Analytics 工作区中或在 Azure Synapse Studio 中创建一个或多个 Spark 池。 定义 Spark 池时,可以为池指定配置选项,包括:
- Spark 池的名称。
- 用于池中节点的虚拟机 (VM) 的大小,包括使用支持 GPU 的硬件加速节点的选项。
- 池中的节点数,以及池大小是固定的,还是可将单个节点联机以动态自动缩放群集;在后面这种情况下,可以指定活动节点的最小和最大数目。
- 要用于池的 Spark 运行时的版本;这决定了各个组件的版本,例如 Python、Java 和安装的其他组件。
提示
有关 Spark 池配置选项的详细信息,请参阅 Azure Synapse Analytics 文档中的 Azure Synapse Analytics 中的 Apache Spark 池配置。
Azure Synapse Analytics 工作区中的 Spark 池是无服务器池 - 它们按需启动并在空闲时停止。