深度神经网络概念
在了解如何训练深度神经网络 (DNN) 机器学习模型之前,我们来考虑一下要实现的目标。 机器学习涉及根据特定观察对象的某些特征来预测标签。 简而言之,机器学习模型是从 x(特征)计算 y(标签)的函数:f(x)=y。
简单的分类示例
例如,假设你的观察包括对企鹅的一些测量值。

具体来说,这些测量值包括:
- 企鹅鸟喙的长度。
- 企鹅鸟喙的深度。
- 企鹅鳍状肢的长度。
- 企鹅的体重。
在这种情况下,特征 (x) 是具有四个值的向量,或者从数学角度上来说,x=[x1,x2,x3,x4]。
假设要预测的标签 (y) 是企鹅的物种,并且它可能是以下三个物种:
- 阿德利企鹅
- 白眉企鹅
- 帽带企鹅
这是分类问题的一个示例,在此过程中,机器学习模型必须预测观察对象最可能属于哪一类。 分类模型通过预测由每个类的概率组成的标签来实现此目的。 换言之,y 是三个概率值的向量;每个可能的类都具有一个概率值:y = [P(0),P(1),P(2)]。
你可以使用已经知道真正标签的观测值来训练机器学习模型。 例如,你可能获得了“阿德利企鹅”样本的以下特征测量值:
x=[37.3, 16.8, 19.2, 30.0]
你已经知道,这是“阿德利企鹅”(类 0)的示例,因此,理想的分类函数应生成一个指示类 0 的概率为 100%,而类 1 和类 2 的概率为 0% 的标签:
y=[1, 0, 0]
深度神经网络模型
那么,我们如何使用深度学习为企鹅分类模型建立分类模型? 我们来看一个示例:
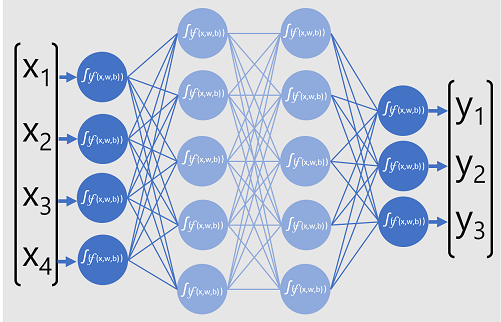
分类器的深度神经模型由多层人工神经元组成。 在本例中,共有四个层:
- 一个输入层,其中每个预计的输入 (x) 值都有一个神经元。
- 两个所谓的隐藏层,每层包含五个神经元。
- 一个包含三个神经元的输出层,每个要由模型预测的类的概率 (y) 值都有一个神经元。
由于网络的分层体系结构,这种模型有时称为“多层感知器”。 此外,请注意,输入层和隐藏层中的所有神经元均连接到后续层中的所有神经元,这是完全连接的网络的一个示例。
创建与此类似的模型时,必须定义支持模型将处理的特征数的输入层,以及反映预期生成的输出数的输出层。 你可以决定要包含的隐藏层的数量,以及每个隐藏层内的神经元的数量,但你无法控制这些层的输入和输出值,这些值由模型训练过程决定。
训练深度神经网络
深度神经网络的训练过程包含多个称为“时期”的迭代。 对于第一个时期,首先需要为权重分配随机初始化值 (w) 和偏差 (b) 值。 然后,该过程如下所示:
- 具有已知标签值的数据观察特征将提交到输入层。 通常情况下,这些观测值分组为多个批次(通常称为小型批处理)。
- 然后,神经元发挥其作用,并在激活后将结果传递到下一层,直到输出层生成预测。
- 将预测与实际的已知值进行比较,并对预测值和真实值之间的差异量(称为“损失”)进行计算。
- 根据结果,计算权重和偏差值的修订值以减少损失,并将这些调整反向传播到网络层中的神经元。
- 下一个时期使用修改后的权重和偏差值重复批量训练向前传递,有望通过减少损失来提高模型的准确性。
注意
将训练特征作为一个批处理,通过将多个观测值同时处理为具有权重和偏差的向量特征矩阵,提高训练过程的效率。 使用矩阵和向量运算的线性代数函数在 3D 图形处理中也很重要,这就是具有图形处理单元 (GPU) 的计算机比仅使用中央处理单元 (CPU) 的计算机能够针对深度学习模型训练提供更高性能的原因。
详细了解损失函数和反向传播
前文中对深度学习训练过程的描述中提到会对模型的损失进行计算,并用于调整权重和偏差值。 到底是如何做到这一点的呢?
计算损失
假设在训练过程中传递的其中一个示例包含“阿德利企鹅”样本(类 0)的特征。 网络的正确输出应为 [1, 0, 0]。 现在,假设网络生成的输出为 [0.4, 0.3, 0.3]。 比较一下,我们可以计算出每个元素的绝对差异(换而言之,每个预测的值与实际值的差距)为 [0.6, 0.3, 0.3]。
在现实中,由于要处理多个观测值,我们通常会对差异进行聚合(例如通过将各个差异值进行平方运算并计算平均值),因此我们最终会得到单一的平均损失值,例如 0.18。
优化器
现在,我们来了解其中的巧妙之处。 损失是使用函数计算的,该函数对网络最终层上的结果(也是一个函数)进行操作。 网络的最终层对先前层的输出(也是一个函数)进行处理。 所以实际上,从输入层到损失计算的整个模型只是一个大型的嵌套函数。 函数具有一些真正有用的特性,其中包括:
- 可以将函数概念化为绘制的线条,将其输出与其每个变量进行比较。
- 可以用微积分来计算函数在任何点对变量的导数。
我们来了解其中的第一个功能。 我们可以绘制函数的线条,以显示单个权重值与损失的比较情况,并在该线条上标记当前权重值与当前损失值匹配的点。
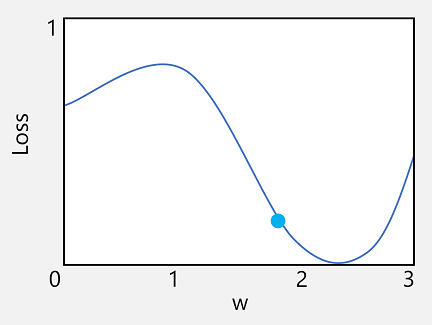
现在,我们应用函数的第二个特征。 函数对于给定点的导数指示函数输出(本例中为损失)的斜率(或梯度)相对于函数变量(本例中为权重值)的增减。 正导数表示该函数正在递增,负导数表示函数正在递减。 本例中,在当前权重值的绘制点处,函数具有向下的梯度。 换而言之,增加权重会产生减少损失的效果。
我们使用优化器为模型中的所有权重和偏差变量应用此相同的技巧,并确定需要在哪个方向上调整它们(向上或向下)才能减少模型中的总损失量。 有多种常用的优化算法,包括随机梯度下降 (SGD)、自适应学习速率 (ADADELTA)、自适应动力估计 (Adam) 等;所有这些算法都旨在确定如何调整权重和偏差以最大程度地减少损失。
学习速率
现在,下一个显而易见的问题是:优化器应该调整多少权重和偏差值? 如果查看权重值的绘图,会发现增加少量权重将按照函数线向下(减少损失),但是如果增加的量太多,函数线将再次向上,因此实际上可能会增加损失;在下一个时期后,可能会发现需要降低权重。
调整的大小由你为训练设置的参数(名为学习速率)控制。 较低的学习速率会导致较小的调整(因此,它可能需要更多的时期来最大程度地减小损失),而较高的学习速率会导致较大的调整(因此可能会完全遗漏最小的调整)。