在 HBase 中执行基准测试
Yahoo!云服务基准测试 (YCSB) 是用于评估 NoSQL 数据库管理系统的相对性能的开源规范和程序套件。 在此练习中,你将针对两个 HBase 群集的性能运行基准测试,其中一个群集启用了加速写入功能。 你的任务是了解这两种选项之间的性能差异。 练习之前的准备工作
如果要执行练习中的步骤,请确保具有以下各项:
- 有权创建 HDInsight HBase 群集的 Azure 订阅。
- 对 SSH 客户端(如 Windows 系统的 Putty 以及 Mac book 的 Terminal)的访问权限
通过 Azure 管理门户预配 HDInsight HBase 群集
要以新的体验在 Azure 管理门户上预配 HDInsight HBase,请执行以下步骤。
转到 Azure 门户。 使用 Azure 帐户凭据登录。
首先,我们要创建一个高级块 Blob 存储帐户。 在“新建”页面上单击“存储帐户”。
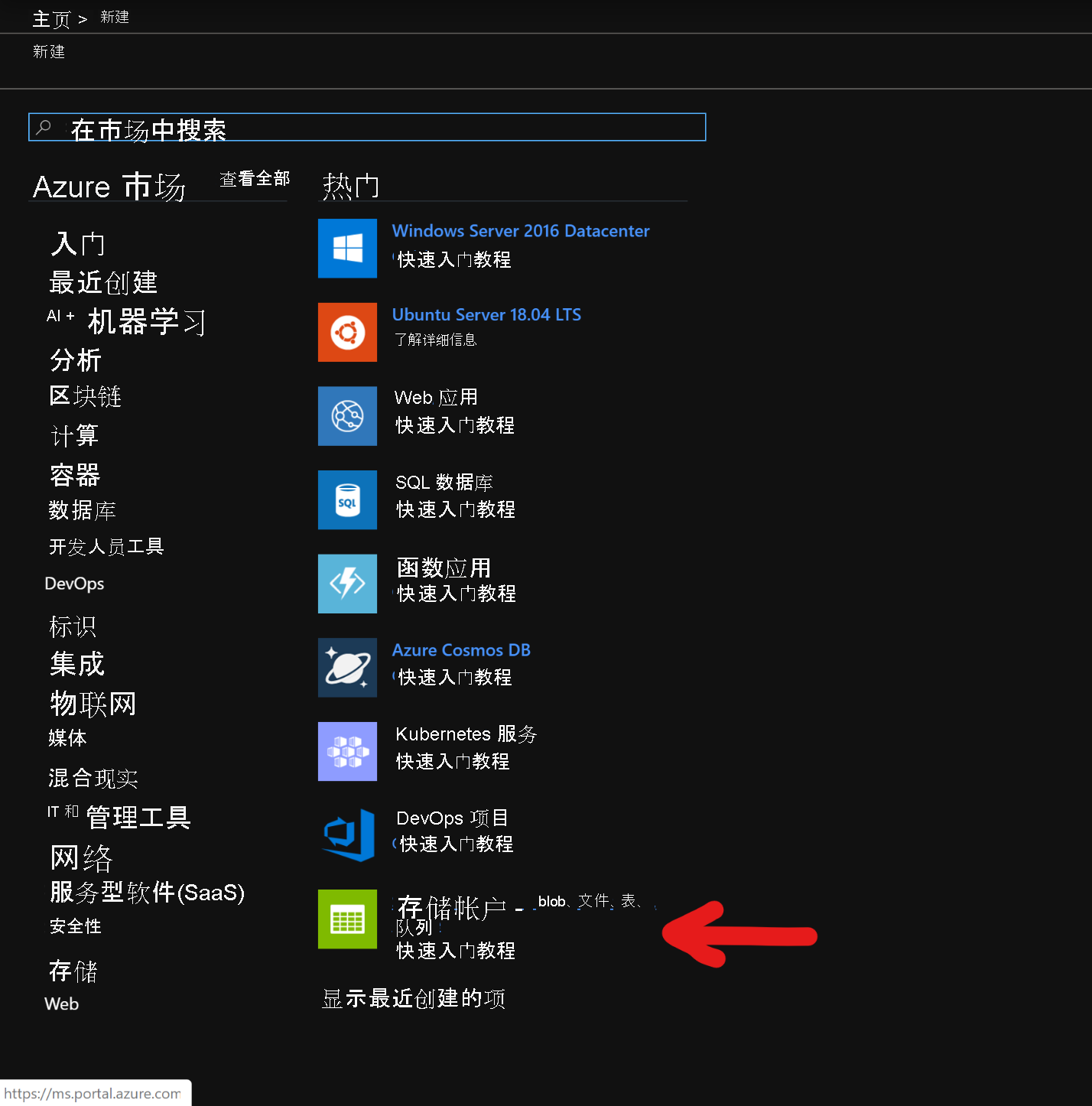
在“创建存储帐户”页中,填充以下字段
订阅:应自动填充订阅详细信息
资源组:输入用于保存 HDInsight HBase 部署的资源组
存储帐户名称:输入在高级群集中使用的存储帐户名称。
区域:输入部署区域的名称(请确保群集和存储帐户位于同一区域)
性能:高级
帐户类型: BlockBlobStorage
复制:本地冗余存储(LRS)
群集登录用户名:输入群集管理员的用户名(默认值:管理员)
将所有其他选项卡保留为默认值,然后单击“查看 + 创建”以创建存储帐户。
创建存储帐户后,单击左侧的“访问密钥”,并复制“key1”。 稍后我们将在群集创建过程中使用它。
现在,让我们开始部署带有加速写入的 HDInsight HBase 群集。 选择“创建资源”->“分析”->“HDInsight”
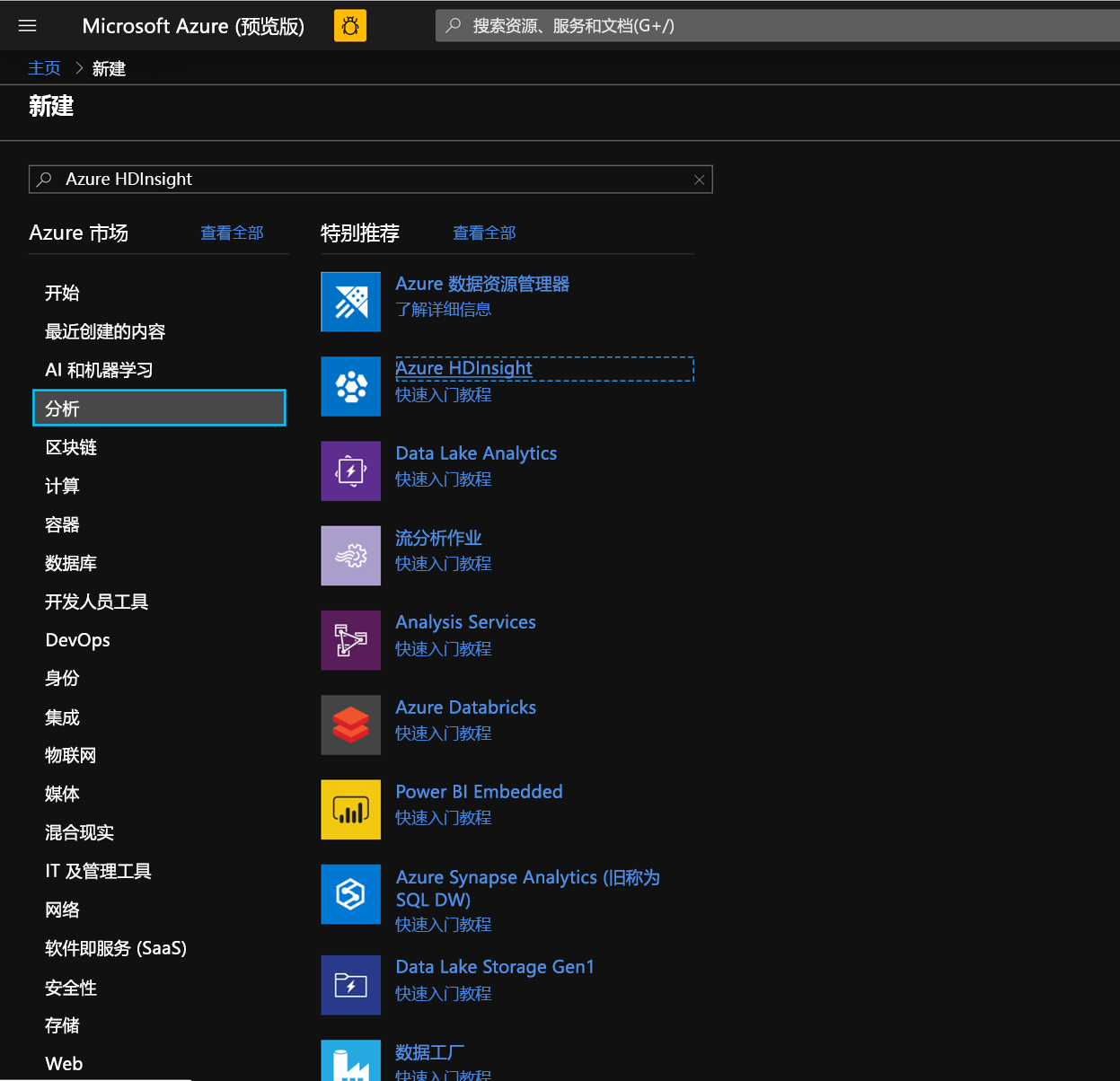
在“基本信息”选项卡中填充以下字段以创建 HBase 群集。
订阅:应自动填充订阅详细信息
资源组:输入用于保存 HDInsight HBase 部署的资源组
群集名称:输入群集名称。 如果该群集名称可用,将出现绿色勾号。
区域:输入部署区域的名称
群集类型:群集类型 - HBase。 版本 - HBase 2.0.0(HDI 4.0)
群集登录用户名:输入群集管理员的用户名(默认值:管理员)
群集登录密码:输入用于群集登录的密码(默认值:sshuser)
确认群集登录密码:确认在上一步中输入的密码
安全外壳 (SSH) 用户名:输入 SSH 登录用户(默认值:sshuser)
将群集登录密码用于 SSH:勾选此框,可为 SSH 群集和 Ambari 登录等场景采用同样的密码。
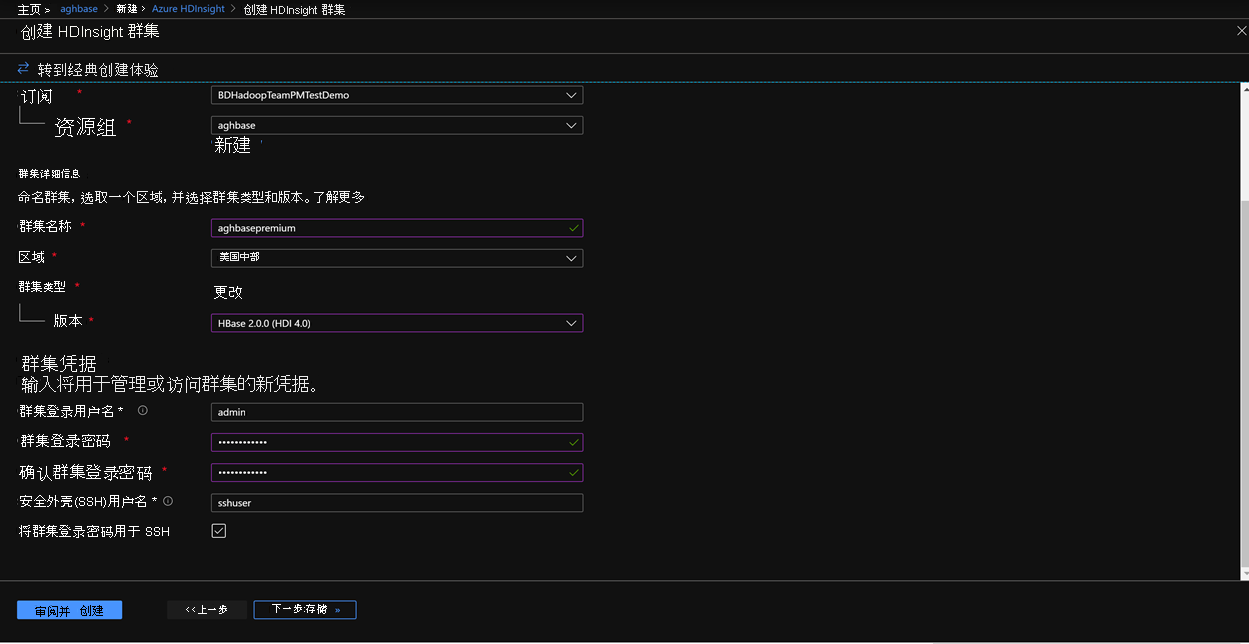
单击“下一步: 存储”,以打开“存储”选项卡并填充以下字段
主存储类型:Azure 存储。
选择方法:选择单选按钮使用访问密钥
存储帐户名称:输入之前创建的高级块 Blob 存储帐户的名称
访问密钥:输入之前复制的 key1 访问密钥
容器: HDInsight 会给出一个推荐的默认容器名称。 可以选择此名称,也可以创建自己的名称。
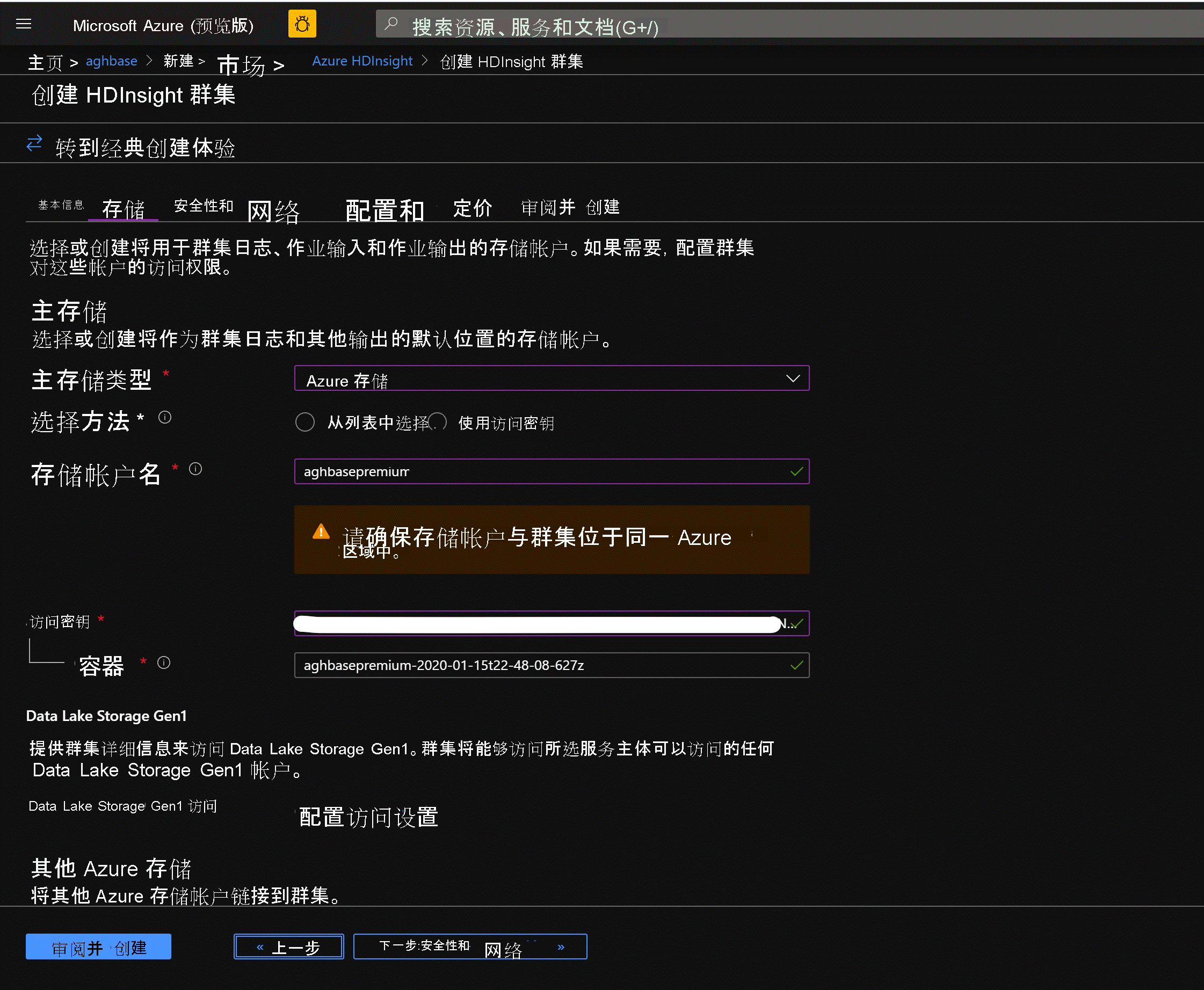
将其他选项卡保留为默认值,并向下滚动以勾选“启用 HBase 加速写入”复选框。(注意,稍后我们将使用相同的步骤创建第二个不启用加速写入的群集,即不勾选此复选框。)
将“安全 + 网络”边栏选项卡保留为默认设置(不进行任何更改),然后转至“配置 + 定价”选项卡。
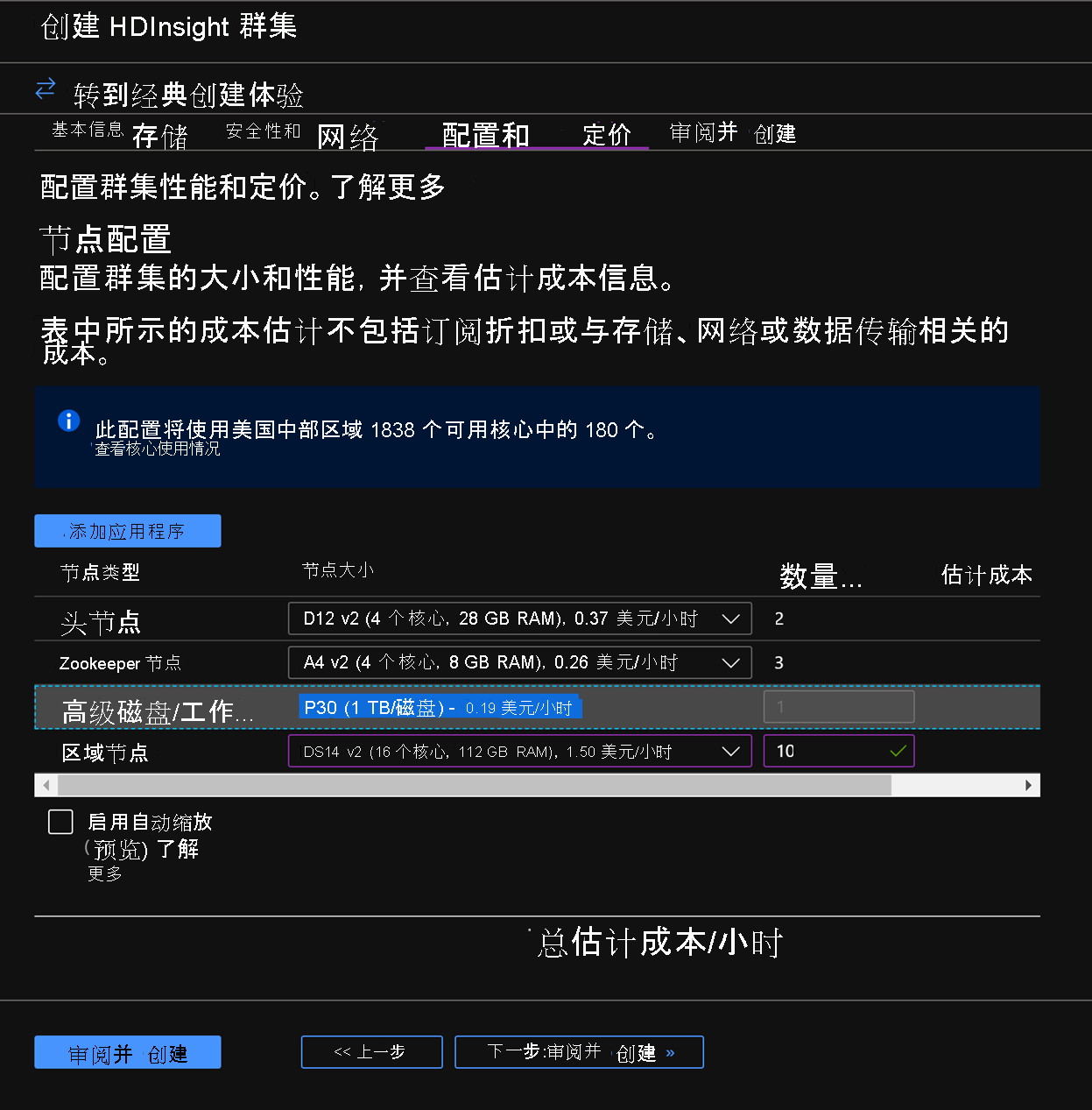
在“配置 + 定价”选项卡中,请注意观察,“节点配置”部分现在有一个标题为“每个工作器节点的高级磁盘”的行项。
将区域节点选择为“10”,并将“节点大小”选择为“DS14v2”,也可以选择较小的 VM 数量和 VM SKU 大小,但请确保两个群集的节点数量以及 VM SKU 是一致的,从而保证比较时的奇偶性。
单击“下一步: 查看 + 创建”
在“查看 + 创建”选项卡中,请确保“存储”部分下的“HBase 加速写入”已启用。
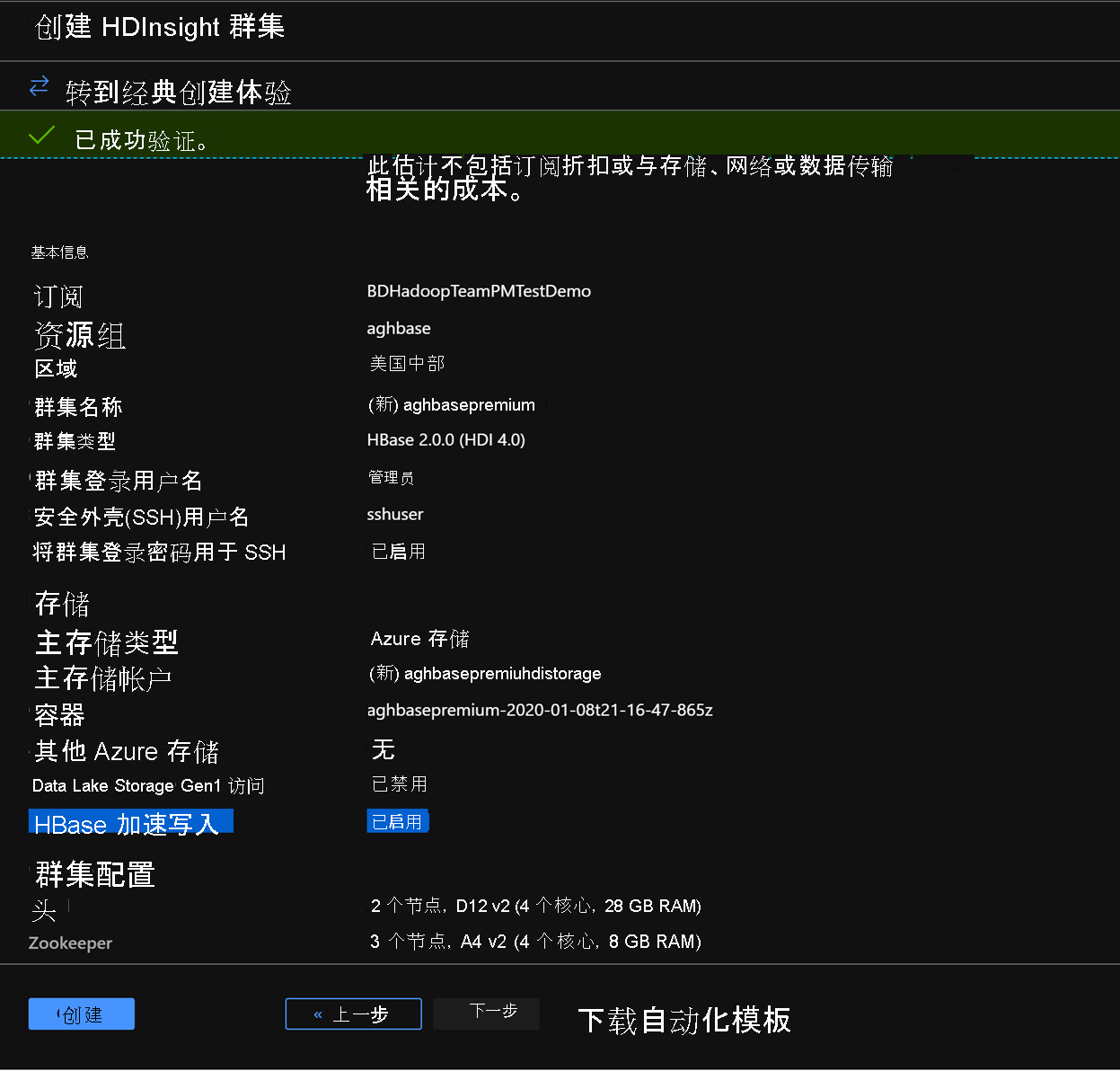
单击“创建”以开始部署启用加速写入的第一个群集。
再次重复相同的步骤来创建第二个 HDInsight HBase 群集,这一次不启用加速写入。 请注意观察以下变化
使用默认推荐的常规 Blob 存储帐户
请勿勾选“存储”选项卡上的“启用加速写入”复选框。
请注意观察,在此群集的“配置 + 定价”选项卡中,这次“节点配置”部分就没有“每个工作器节点的高级磁盘”行项了。
将区域节点选择为“10”,并将“节点大小”选择为“DS14v2”。另请注意,缺少 DS 系列 VM 类型(与之前一样)。 (也可以选择较小的 VM 数量和 VM SKU 大小,但请确保两个群集的节点数量以及 VM SKU 是一致的,从而保证比较时的奇偶性)
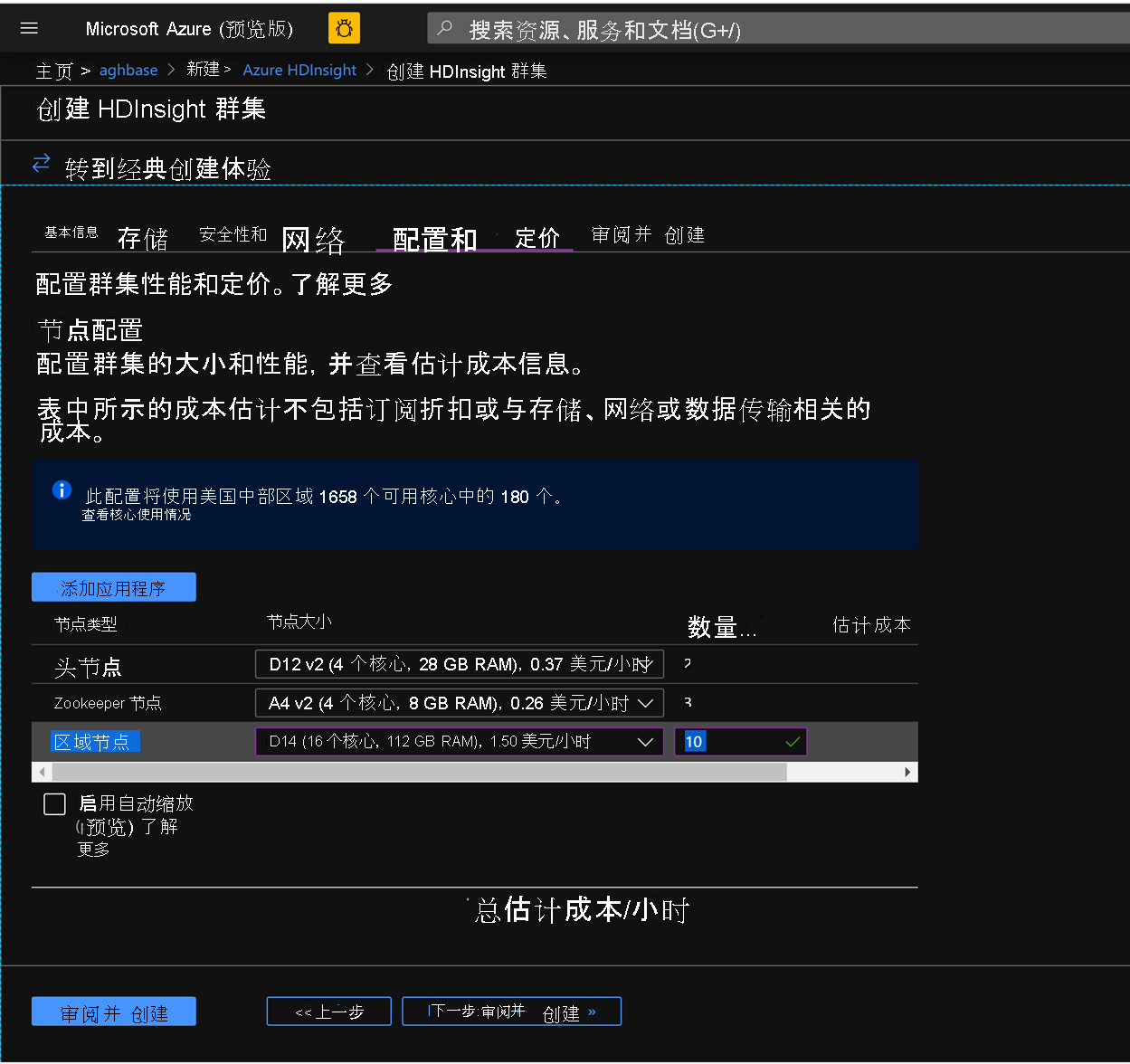
单击“创建”以开始部署未启用加速写入的第二个群集。
现在我们已完成群集部署,接下来的部分,我们将在这两个群集上设置并运行 YCSB 测试。

运行 YCSB 测试
登录到 HDInsight shell
在两个群集上设置和运行 YCSB 测试的步骤是相同的。
在 Azure 门户上的群集页上导航到“SSH + 群集登录”,并使用主机名和 SSH 路径通过 SSH 连接到群集。 路径应采用以下格式。
ssh <sshuser>@<clustername>.azurehdinsight.net
创建表
运行以下步骤以创建 HBase 表,这些表将用于加载数据集
启动 HBase Shell 并设置表示表拆分数的参数。 设置表拆分数(10* 区域服务器的数量)
创建用于运行测试的 HBase 表
退出 HBase shell
hbase(main):018:0> n_splits = 100 hbase(main):019:0> create 'usertable', 'cf', {SPLITS => (1..n_splits).map {|i| "user#{1000+i*(9999-1000)/n_splits}"}} hbase(main):020:0> exit
下载 YSCB 存储库
下载来自以下目标的 YCSB 存储库
$ curl -O --location https://github.com/brianfrankcooper/YCSB/releases/download/0.17.0/ycsb-0.17.0.tar.gz解压缩文件夹以访问内容
$ tar xfvz ycsb-0.17.0.tar.gz此操作会创建一嗝 ycsb-0.17.0 文件夹。 移动至此文件夹中
在两个群集中运行写入量很大的工作负荷
使用下面的命令,通过以下参数启动写入量很大的工作负荷
workloads/workloada:表示需要运行的附加工作负荷
table:填入之前创建的 HBase 表的名称
columnfamily:填入之前创建的表中的 HBase columfamily 名称的值
recordcount:要插入的记录数(本例中为 100 万)
threadcount:线程数,可以有所不同,但是需要在试验中保持不变
-cp /etc/hbase/conf:指向 HBase 配置设置
-s | tee -a:提供一个文件名来写入输出。
bin/ycsb load hbase12 -P workloads/workloada -p table=usertable -p columnfamily=cf -p recordcount=1000000 -p threadcount=4 -cp /etc/hbase/conf -s | tee -a workloada.dat
运行写入量很大的工作负荷,将 100 万行加载到之前创建的 HBase 表。
注意
请忽略提交命令后可能会出现的警告。
启用加速写入的 HDInsight HBase 的示例结果
运行以下命令:
```CMD $ bin/ycsb load hbase12 -P workloads/workloada -p table=usertable -p columnfamily=cf -p recordcount=1000000 -p threadcount=4 -cp /etc/hbase/conf -s | tee -a workloada.dat ```阅读结果:
```CMD 2020-01-10 16:21:40:213 10 sec: 15451 operations; 1545.1 current ops/sec; est completion in 10 minutes [INSERT: Count=15452, Max=120319, Min=1249, Avg=2312.21, 90=2625, 99=7915, 99.9=19551, 99.99=113855] 2020-01-10 16:21:50:213 20 sec: 34012 operations; 1856.1 current ops/sec; est completion in 9 minutes [INSERT: Count=18560, Max=305663, Min=1230, Avg=2146.57, 90=2341, 99=5975, 99.9=11151, 99.99=296703] .... 2020-01-10 16:30:10:213 520 sec: 972048 operations; 1866.7 current ops/sec; est completion in 15 seconds [INSERT: Count=18667, Max=91199, Min=1209, Avg=2140.52, 90=2469, 99=7091, 99.9=22591, 99.99=66239] 2020-01-10 16:30:20:214 530 sec: 988005 operations; 1595.7 current ops/sec; est completion in 7 second [INSERT: Count=15957, Max=38847, Min=1257, Avg=2502.91, 90=3707, 99=8303, 99.9=21711, 99.99=38015] ... ... 2020-01-11 00:22:06:192 564 sec: 1000000 operations; 1792.97 current ops/sec; [CLEANUP: Count=8, Max=80447, Min=5, Avg=10105.12, 90=268, 99=80447, 99.9=80447, 99.99=80447] [INSERT: Count=8512, Max=16639, Min=1200, Avg=2042.62, 90=2323, 99=6743, 99.9=11487, 99.99=16495] [OVERALL], RunTime(ms), 564748 [OVERALL], Throughput(ops/sec), 1770.7012685303887 [TOTAL_GCS_PS_Scavenge], Count, 871 [TOTAL_GC_TIME_PS_Scavenge], Time(ms), 3116 [TOTAL_GC_TIME_%_PS_Scavenge], Time(%), 0.5517505152740692 [TOTAL_GCS_PS_MarkSweep], Count, 0 [TOTAL_GC_TIME_PS_MarkSweep], Time(ms), 0 [TOTAL_GC_TIME_%_PS_MarkSweep], Time(%), 0.0 [TOTAL_GCs], Count, 871 [TOTAL_GC_TIME], Time(ms), 3116 [TOTAL_GC_TIME_%], Time(%), 0.5517505152740692 [CLEANUP], Operations, 8 [CLEANUP], AverageLatency(us), 10105.125 [CLEANUP], MinLatency(us), 5 [CLEANUP], MaxLatency(us), 80447 [CLEANUP], 95thPercentileLatency(us), 80447 [CLEANUP], 99thPercentileLatency(us), 80447 [INSERT], Operations, 1000000 [INSERT], AverageLatency(us), 2248.752362 [INSERT], MinLatency(us), 1120 [INSERT], MaxLatency(us), 498687 [INSERT], 95thPercentileLatency(us), 3623 [INSERT], 99thPercentileLatency(us), 7375 [INSERT], Return=OK, 1000000 ```浏览测试的结果。 例如,从上述结果中可以观察到:
- 运行此测试花费了 538663 毫秒(8.97 分钟)
- “Return=OK, 1000000”表示 100 万条输入全都成功写入**
- 写入吞吐量为每秒 1856 个操作
- 95% 的插入存在 3389 毫秒的延迟
- 较少的插入花费了更多的时间,也许是因为工作负荷较高而被区域服务器阻止了
未启用加速写入的 HDInsight HBase 的示例结果
运行以下命令:
$ bin/ycsb load hbase12 -P workloads/workloada -p table=usertable -p columnfamily=cf -p recordcount=1000000 -p threadcount=4 -cp /etc/hbase/conf -s | tee -a workloada.dat阅读结果:
2020-01-10 23:58:20:475 2574 sec: 1000000 operations; 333.72 current ops/sec; [CLEANUP: Count=8, Max=79679, Min=4, Avg=9996.38, 90=239, 99=79679, 99.9 =79679, 99.99=79679] [INSERT: Count=1426, Max=39839, Min=6136, Avg=9289.47, 90=13071, 99=27535, 99.9=38655, 99.99=39839] [OVERALL], RunTime(ms), 2574273 [OVERALL], Throughput(ops/sec), 388.45918828344935 [TOTAL_GCS_PS_Scavenge], Count, 908 [TOTAL_GC_TIME_PS_Scavenge], Time(ms), 3208 [TOTAL_GC_TIME_%_PS_Scavenge], Time(%), 0.12461770760133055 [TOTAL_GCS_PS_MarkSweep], Count, 0 [TOTAL_GC_TIME_PS_MarkSweep], Time(ms), 0 [TOTAL_GC_TIME_%_PS_MarkSweep], Time(%), 0.0 [TOTAL_GCs], Count, 908 [TOTAL_GC_TIME], Time(ms), 3208 [TOTAL_GC_TIME_%], Time(%), 0.12461770760133055 [CLEANUP], Operations, 8 [CLEANUP], AverageLatency(us), 9996.375 [CLEANUP], MinLatency(us), 4 [CLEANUP], MaxLatency(us), 79679 [CLEANUP], 95thPercentileLatency(us), 79679 [CLEANUP], 99thPercentileLatency(us), 79679 [INSERT], Operations, 1000000 [INSERT], AverageLatency(us), 10285.497832 [INSERT], MinLatency(us), 5568 [INSERT], MaxLatency(us), 1307647 [INSERT], 95thPercentileLatency(us), 18751 [INSERT], 99thPercentileLatency(us), 33759 [INSERT], Return=OK, 1000000比较结果:
参数 Unit 已启用加速写入 未启用加速写入 [OVERALL], RunTime(ms) 毫秒 567478 2574273 [OVERALL], Throughput(ops/sec) 操作数/秒 1770 388 [INSERT], Operations 操作数 1000000 1000000 [INSERT], 95thPercentileLatency(us) 微秒 3623 18751 [INSERT], 99thPercentileLatency(us) 微秒 7375 33759 [INSERT], Return=OK 记录数 1000000 1000000 例如,我们可以观察结果,并对比以下内容:
- [OVERALL], RunTime(ms):总执行时间(毫秒)
- [OVERALL], Throughput(ops/sec):所有线程上每秒的操作数
- [INSERT], Operations:插入操作的总数,下面还有与之关联的平均、最小、最大、95% 和 99% 延迟
- [INSERT], 95thPercentileLatency(us):95% 的插入操作具有该值下的数据点
- [INSERT], 99thPercentileLatency(us):99% 的插入操作具有该值下的数据点
- [INSERT], Return=OK:“Record OK”表示所有插入操作都已成功,旁边还有操作计数
请考虑尝试使用一系列其他工作符合进行比较。 示例包括:
读取占大部分的(分为 95% 读取和 5% 写入):workloadb
bin/ycsb run hbase12 -P workloads/workloadb -p table=usertable -p columnfamily=cf -p recordcount=1000000 -p operationcount=100000 -p threadcount=4 -cp /etc/hbase/conf -s | tee -a workloadb.dat仅读取的(分为 100% 读取和 0% 写入):workloadc
bin/ycsb run hbase12 -P workloads/workloadc -p table=usertable -p columnfamily=cf -p recordcount=1000000 -p operationcount=100000 -p threadcount=4 -cp /etc/hbase/conf -s | tee -a workloadc.dat