缓解潜在危害
确定基线以及衡量解决方案生成的有害输出的方法后,可以采取措施缓解潜在危害,并在适当时重新测试修改后的系统,将危害层级与基线进行比较。
缓解生成式 AI 解决方案中的潜在危害涉及分层方法,其中缓解技术可在四个层级中的每一层级应用,如下所示:
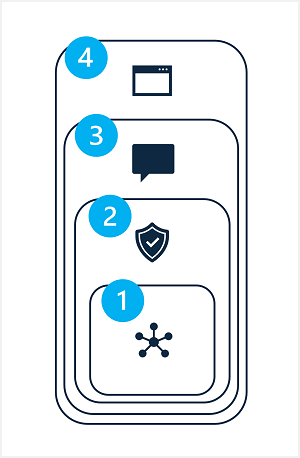
- Model
- 安全系统
- 元提示和接地
- 用户体验
1:模型层级
模型层由一个或多个处于解决方案核心的生成式 AI 模型组成。 例如,解决方案可能围绕 GPT-4 等模型构建。
可在模型层级应用的缓解措施包括:
- 选择适合预期解决方案用途的模型。 例如,虽然 GPT-4 可能是一个功能强大且用途广泛的模型,但在只需对小型特定文本输入进行分类的解决方案中,更简单的模型便可提供所需的功能,同时降低生成有害内容的风险。
- 使用自己的训练数据微调基础模型,使其生成的响应更有可能与你的解决方案场景相关并契合它的范围。
2:安全系统层级
安全系统层级包括平台级配置和功能,可帮助缓解危害。 例如,Azure AI Studio 包括对内容筛选器的支持,这些内容筛选器将应用标准来将四个潜在危害类别(仇恨、性、暴力和自残)的内容分类为四个严重性级别(安全、低、中和高),从而禁止显示提示和响应。
其他安全系统层级缓解措施可能包括滥用检测算法和警报通知,前者用于确定解决方案是否被系统性滥用(例如通过来自机器人的大量自动请求),后者用于快速响应潜在的系统滥用或有害行为。
3:元提示和接地层
元提示和接地层侧重于提交到模型的提示的构造。 可在此层应用的危害缓解技术包括:
- 指定为模型定义行为参数的元提示或系统输入。
- 应用提示工程将接地数据添加到输入提示,最大限度地提高相关、无害输出的可能性。
- 使用检索增强生成 (RAG) 方法从受信任的数据源检索上下文数据并将其包含在提示中。
4:用户体验层
用户体验层包括软件应用程序(用户通过软件应用程序与生成式 AI 模型进行交互)以及向用户和利益干系人描述解决方案使用方法的文档或其他用户资料。
设计应用程序用户界面以将输入限制为特定主题或类型,或者应用输入和输出验证可以降低潜在有害响应的风险。
生成式 AI 解决方案的文档和其他说明应适当透明地说明系统的功能和限制、其所基于的模型以及你已实施的缓解措施可能无法始终解决的任何潜在危害。