练习:保护、监视和优化已迁移的数据库
你是 AdventureWorks 组织中的一名数据库开发人员。 AdventureWorks 已经将自行车和自行车零件直接出售给最终用户和分销商十多年来。 其系统将信息存储在以前迁移到 Azure Database for PostgreSQL 的数据库中。
执行迁移后,需要确保系统性能良好。 你决定使用可用于监视服务器的 Azure 工具。 为了缓解争用和延迟导致的响应时间缓慢的可能性,你决定实现读取复制。 需要监视生成的系统,并将结果与灵活的服务器体系结构进行比较。
在本练习中,你将执行以下任务:
- 为 Azure Database for PostgreSQL 服务配置 Azure 指标。
- 运行模拟查询数据库的多个用户的示例应用程序。
- 查看指标。
设置环境
在 Cloud Shell 中运行这些 Azure CLI 命令,使用 adventureworks 数据库的副本创建 Azure Database for PostgreSQL。 最后一个命令打印服务器名称。
SERVERNAME="adventureworks$((10000 + RANDOM % 99999))"
PUBLICIP=$(wget http://ipecho.net/plain -O - -q)
git clone https://github.com/MicrosoftLearning/DP-070-Migrate-Open-Source-Workloads-to-Azure.git workshop
az postgres server create \
--resource-group <rgn>[sandbox resource group name]</rgn> \
--name $SERVERNAME \
--location westus \
--version 10 \
--storage-size 5120
az postgres db create \
--name azureadventureworks \
--server-name $SERVERNAME \
--resource-group <rgn>[sandbox resource group name]</rgn>
az postgres server firewall-rule create \
--resource-group <rgn>[sandbox resource group name]</rgn> \
--server $SERVERNAME \
--name AllowMyIP \
--start-ip-address $PUBLICIP --end-ip-address $PUBLICIP
PGPASSWORD=Pa55w.rdDemo psql -h $SERVERNAME.postgres.database.azure.com -U awadmin@$SERVERNAME -d postgres -f workshop/migration_samples/setup/postgresql/adventureworks/create_user.sql
PGPASSWORD=Pa55w.rd psql -h $SERVERNAME.postgres.database.azure.com -U azureuser@$SERVERNAME -d azureadventureworks -f workshop/migration_samples/setup/postgresql/adventureworks/adventureworks.sql 2> /dev/null
echo "Your PostgreSQL server name is:\n"
echo $SERVERNAME.postgres.database.azure.com
为 Azure Database for PostgreSQL 服务配置 Azure 指标
使用 Web 浏览器打开新的标签页,然后导航到 Azure 门户。
在 Azure 门户中,选择“所有资源”。
从 adventureworks 开始,选择 Azure Database for PostgreSQL 服务器名称。
在“监视”下,选择“指标”。
在图表页上,添加以下指标:
财产 价值 范围 adventureworks[nnn] 指标命名空间 PostgreSQL 服务器标准指标 度量 活动连接 集合体 Avg 此指标显示每分钟与服务器建立的平均连接数。
选择“添加指标,然后添加以下指标:
财产 价值 范围 adventureworks[nnn] 指标命名空间 PostgreSQL 服务器标准指标 度量 CPU 百分比 集合体 Avg 选择“添加指标,然后添加以下指标:
财产 价值 范围 adventureworks[nnn] 指标命名空间 PostgreSQL 服务器标准指标 度量 内存百分比 集合体 Avg 选择“添加指标,然后添加以下指标:
财产 价值 范围 adventureworks[nnn] 指标命名空间 PostgreSQL 服务器标准指标 度量 IO 百分比 集合体 Avg 这三个指标显示了测试应用程序如何使用资源。
将图表的时间范围设置为 过去 30 分钟。
选择 固定到仪表板,然后选择 固定。
运行模拟查询数据库的多个用户的示例应用程序
在 Azure 门户中,在 Azure Database for PostgreSQL 服务器的页面上,在 设置下,选择 连接字符串。 将 ADO.NET 连接字符串复制到剪贴板。
移动到 ~/workshop/migration_samples/code/postgresql/AdventureWorksSoakTest 文件夹。
cd ~/workshop/migration_samples/code/postgresql/AdventureWorksSoakTest使用代码编辑器打开 App.config 文件:
code App.config将 Database 的值替换为 azureadventureworks ,并将 ConectionString0 替换为剪贴板中的连接字符串。 将 用户 ID 更改为 azureuser@adventureworks[nnn],并将 密码 设置为 Pa55w.rd。 完成的文件应类似于以下示例:
<?xml version="1.0" encoding="utf-8" ?> <configuration> <appSettings> <add key="ConnectionString0" value="Server=adventureworks101.postgres.database.azure.com;Database=azureadventureworks;Port=5432;User Id=azureuser@adventureworks101;Password=Pa55w.rd;Ssl Mode=Require;" /> <add key="ConnectionString1" value="INSERT CONNECTION STRING HERE" /> <add key="ConnectionString2" value="INSERT CONNECTION STRING HERE" /> <add key="NumClients" value="100" /> <add key="NumReplicas" value="1"/> </appSettings> </configuration>注释
暂时忽略 ConnectionString1 和 ConnectionString2 设置。 稍后将在实验室中更新这些项目。
保存更改并关闭编辑器。
在 Cloud Shell 提示符下,运行以下命令以生成并运行应用:
dotnet run应用启动时,它会生成线程,每个线程模拟用户。 线程执行循环,运行一系列查询。 你将看到消息,如以下消息开始显示:
Client 48 : SELECT * FROM purchasing.vendor Response time: 630 ms Client 48 : SELECT * FROM sales.specialoffer Response time: 702 ms Client 43 : SELECT * FROM purchasing.vendor Response time: 190 ms Client 57 : SELECT * FROM sales.salesorderdetail Client 68 : SELECT * FROM production.vproductanddescription Response time: 51960 ms Client 55 : SELECT * FROM production.vproductanddescription Response time: 160212 ms Client 59 : SELECT * FROM person.person Response time: 186026 ms Response time: 2191 ms Client 37 : SELECT * FROM person.person Response time: 168710 ms执行后续步骤时,使应用保持运行状态。
查看指标
返回到 Azure 门户。
在左侧窗格中,选择 仪表板。
应会看到显示 Azure Database for PostgreSQL 服务的指标的图表。
选择图表以在 指标 窗格中将其打开。
允许应用运行几分钟(越长越好)。 随着时间的流逝,图表中的指标应类似于下图所示的模式:
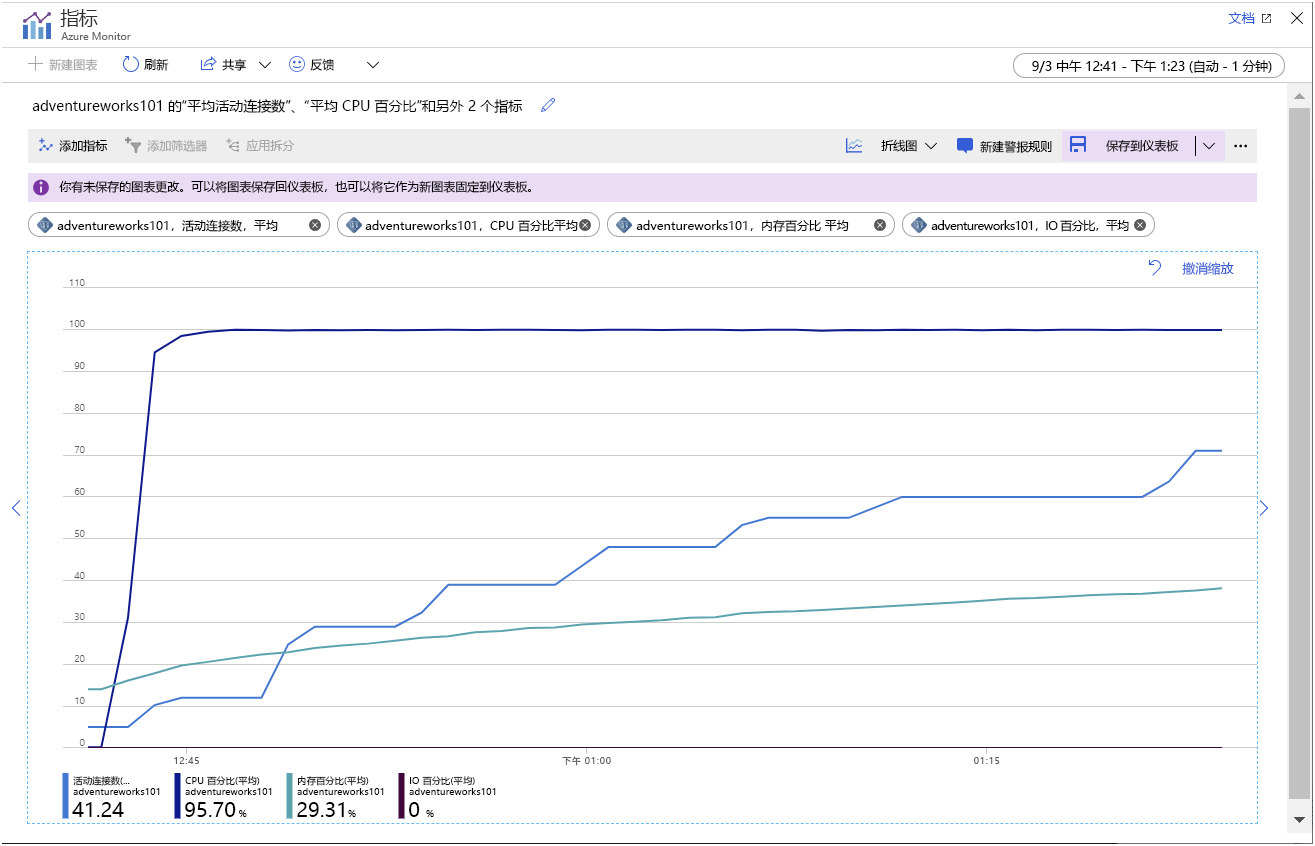
此图表突出显示以下几点:
- CPU 以完整容量运行;利用率达到 100% 非常快。
- 连接数缓慢上升。 示例应用程序旨在快速连续启动 101 个客户端,但服务器一次只能处理打开几个连接。 图表中每个“步骤”添加的连接数越来越小,“步骤”之间的时间正在增加。 大约 45 分钟后,系统只能建立 70 个客户端连接。
- 随着时间推移,内存利用率不断增加。
- IO 利用率接近零。 客户端应用程序所需的所有数据当前都缓存在内存中。
如果使应用程序运行时间足够长,则会看到连接开始失败,并显示下图所示的错误消息。
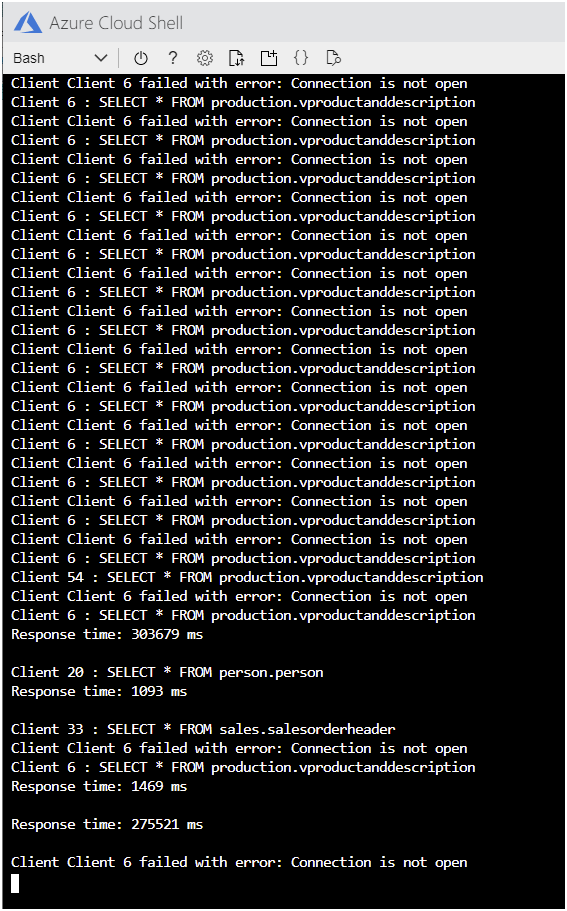
在 Cloud Shell 中,按 Enter 停止应用程序。
配置服务器以收集查询性能数据
在 Azure 门户中,在 Azure Database for PostgreSQL 服务器的页面上,在 设置下,选择 服务器参数。
在 服务器参数 页上,将以下参数设置为下表中指定的值。
参数 价值 pg_qs.max_query_text_length 6000 pg_qs.query_capture_mode ALL pg_qs.replace_parameter_placeholders ON pg_qs.retention_period_in_days 7 pg_qs.track_utility ON pg_stat_statements.track ALL pgms_wait_sampling.history_period 100 pgms_wait_sampling.query_capture_mode ALL 选择 保存。
使用查询存储检查应用程序运行的查询
返回到 Cloud Shell,并重启示例应用:
dotnet run允许应用在继续之前运行 5 分钟左右。
使应用保持运行状态并切换到 Azure 门户
在 Azure Database for PostgreSQL 服务器的页面上,在 智能性能下,选择 Query Performance Insight。
在 查询性能见解 页上的“长时间运行的查询”选项卡上,将 查询数 设置为 10,将 设置为平均 ,并将 时间段设置为“过去 6 小时”。
在图表上方,选择“放大(带有”+“符号的放大镜图标)几次,以驻留在最新数据上。
根据应用程序运行的时间,你将看到如下所示的图表。 查询存储每 15 分钟聚合一次查询的统计信息,因此每个条形显示每 15 分钟期间每个查询消耗的相对时间:
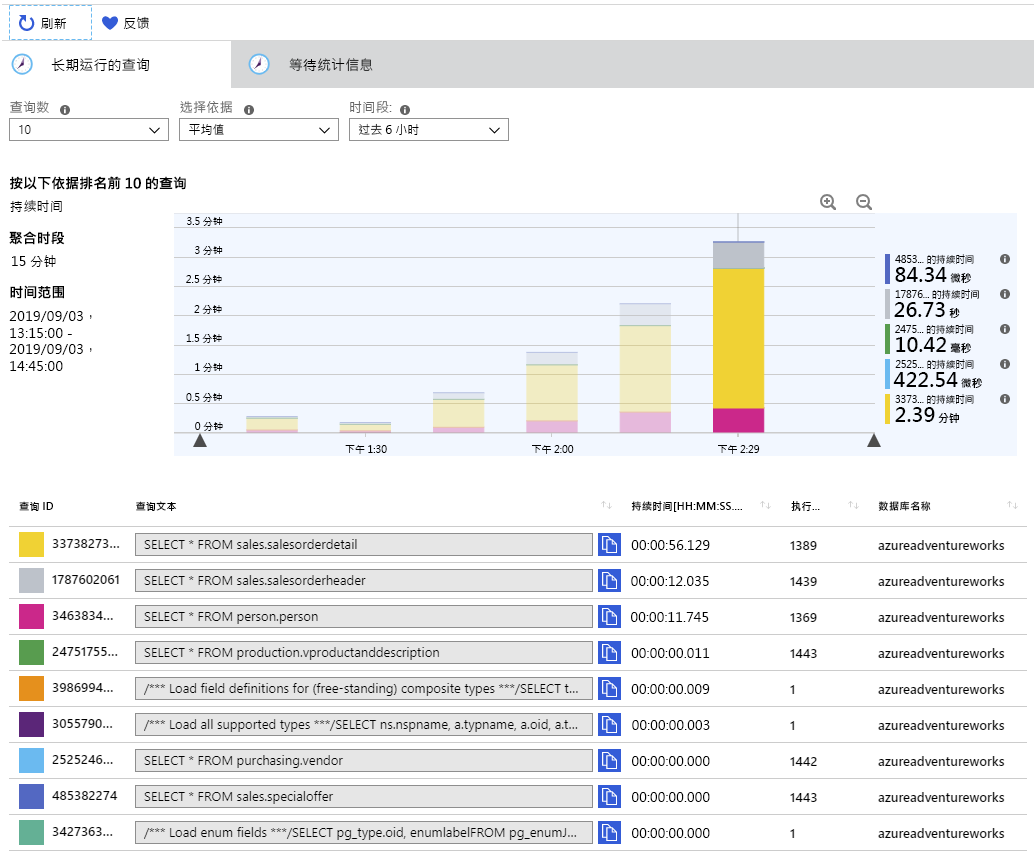 捕获的长时间运行的查询的统计信息
捕获的长时间运行的查询的统计信息
将鼠标悬停在每个条形上,以查看该时间段内查询的统计信息。 系统花费大部分时间执行的三个查询包括:
SELECT * FROM sales.salesorderdetail SELECT * FROM sales.salesorderheader SELECT * FROM person.person此信息对于管理员监视系统非常有用。 通过深入了解用户和应用运行的查询,可以了解执行的工作负载,并可能向应用程序开发人员提出建议,了解如何改进其代码。 例如,应用程序是否需要从 sales.salesorderdetail 表中检索所有 121,000 行?
检查使用查询存储发生的任何等待
选择“等待统计信息” 选项卡。
将 时间段 设置为 “过去 6 小时”,将 “分组 依据”设置为“事件”,并将 最大组数 设置为 5。
与 长时间运行的查询 选项卡一样,数据每 15 分钟聚合一次。 下表显示系统受两种类型的等待事件的约束:
- 客户端:ClientWrite。 当服务器将数据(结果)写入客户端时,将发生此等待事件。 它不会 指示写入数据库时产生的等待。
- 客户端:ClientRead。 当服务器正在等待从客户端读取数据(查询请求或其他命令)时,会发生此等待事件。 它 与从数据库读取所花费的时间关联的。
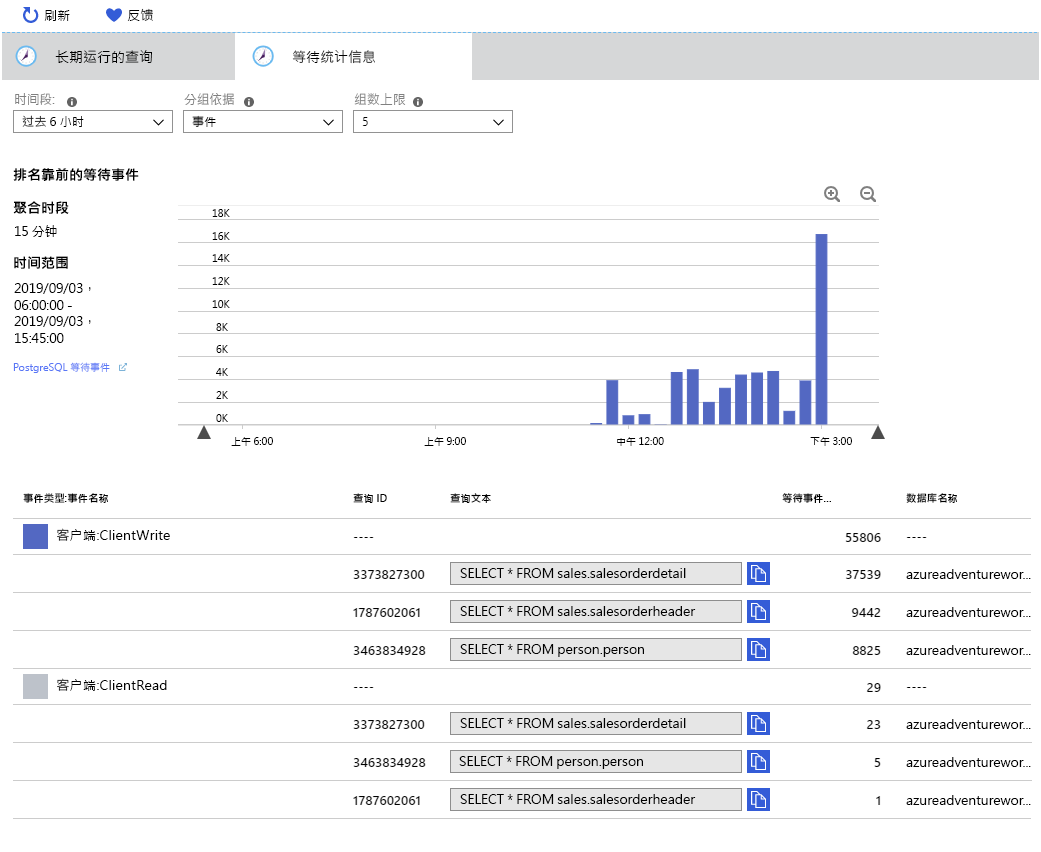 捕获的等待统计信息的图像
捕获的等待统计信息的图像
注释
读取和写入数据库由 IO 事件指示,而不是 客户端 事件。 示例应用程序不会产生任何 IO 等待,因为它所需的所有数据在首次读取后缓存在内存中。 如果指标显示内存运行不足,则可能会看到 IO 等待事件开始发生。
返回到 Cloud Shell,然后按 Enter 停止示例应用程序。
将副本添加到 Azure Database for PostgreSQL 服务
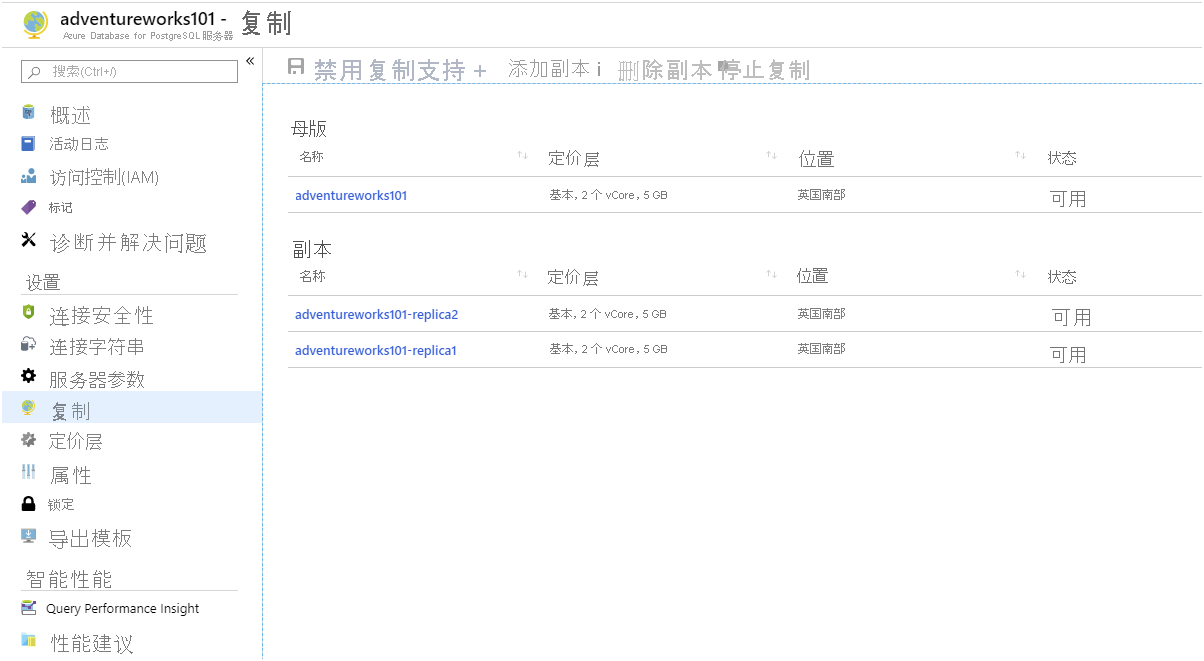
在 Azure 门户中,在 Azure Database for PostgreSQL 服务器的页面上,在 设置下,选择 复制。
在 复制 页上,选择 + 添加副本。
在 PostgreSQL 服务器 页上,在 服务器名称 框中,键入 adventureworks[nnn]-replica1,然后选择 OK。
创建第一个副本时(需要几分钟),重复上一步,并添加名为 adventureworks[nnn]-replica2 的另一个副本。
请等待两个副本的状态从 部署 更改为 可用,然后再继续。
显示 Azure Database for PostgreSQL 的复制页的
配置副本以启用客户端访问
- 选择 adventureworks[nnn]-replica1 副本的名称。 你将被重定向到此副本的 Azure Database for PostgreSQL 页的页面。
- 在“设置”下,选择“连接安全性”。
- 在 连接安全性 页上,设置 允许访问 Azure 服务ON,然后选择“保存”。 此设置允许使用 Cloud Shell 运行的应用程序访问服务器。
- 保存设置后,重复上述步骤,并允许 Azure 服务访问 adventureworks[nnn]-replica2 副本。
重启每个服务器
注释
配置复制不需要重启服务器。 此任务的目的是清除每个服务器中的内存和任何多余的连接,以便再次运行应用程序时收集的指标 干净。
- 转到 adventureworks[nnn] 服务器的页面。
- 在“概述” 页上,选择“重启”。
- 在“重启服务器 对话框中,选择”是“。
- 等待服务器重启,然后再继续。
- 按照相同的过程,重启 adventureworks[nnn]-replica1 和 adventureworks[nnn]-replica2 服务器。
将示例应用程序重新配置为使用副本
在 Cloud Shell 中,编辑 App.config 文件。
code App.config为 ConnectionString1 添加连接字符串,并 ConnectionString2 设置。 这些值应与 ConnectionString0的值相同,但文本 adventureworks[nnn] 替换为 adventureworks[nnn]-replica1 和 adventureworks[nnn]-replica2Server 和 User Id 元素。
将 NumReplicas 设置为 3。
App.config 文件现在应如下所示:
<configuration> <appSettings> <add key="ConnectionString0" value="Server=adventureworks101.postgres.database.azure.com;Database=azureadventureworks;Port=5432;User Id=azureuser@adventureworks101;Password=Pa55w.rd;Ssl Mode=Require;" /> <add key="ConnectionString1" value="Server=adventureworks101-replica1.postgres.database.azure.com;Database=azureadventureworks;Port=5432;User Id=azureuser@adventureworks101-replica1;Password=Pa55w.rd;Ssl Mode=Require;" /> <add key="ConnectionString2" value="Server=adventureworks101-replica2.postgres.database.azure.com;Database=azureadventureworks;Port=5432;User Id=azureuser@adventureworks101-replica2;Password=Pa55w.rd;Ssl Mode=Require;" /> <add key="NumClients" value="100" /> <add key="NumReplicas" value="3"/> </appSettings> </configuration>保存文件并关闭编辑器。
再次启动运行的应用:
dotnet run应用程序按以前一样运行。 但是,这一次,请求分布在三个服务器中。
允许应用运行几分钟,然后再继续。
监视应用并观察性能指标的差异
使应用保持运行状态并返回到 Azure 门户。
在左侧窗格中,选择 仪表板。
选择图表以在 指标 窗格中将其打开。
请记住,此图表显示 adventureworks*[nnn]* 服务器的指标,但不显示副本。 每个副本的负载应大致相同。
示例图表演示从启动到 30 分钟内为应用程序收集的指标。 图表显示 CPU 使用率仍然很高,但内存利用率较低。 此外,大约 25 分钟后,系统为超过 30 个连接建立了连接。 这似乎与之前的配置相比并不有利,在 45 分钟后支持 70 个连接。 但是,工作负荷现在分布在三台服务器上,这些服务器都在同一级别执行,并且已建立所有 101 个连接。 此外,系统能够在不报告任何连接故障的情况下继续运行。
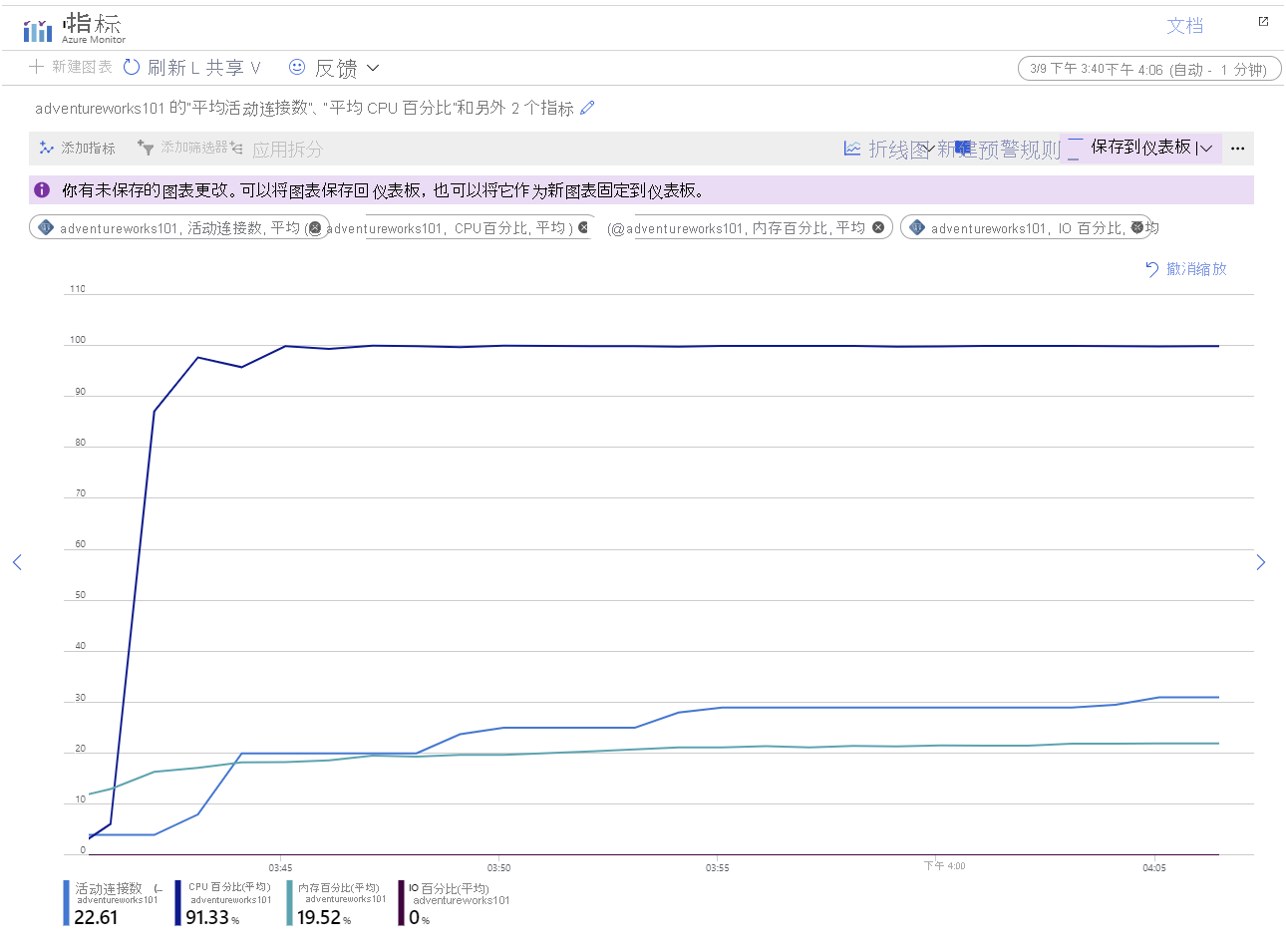
可以通过纵向扩展到具有更多 CPU 核心的更高定价层来解决 CPU 使用率问题。 本实验室中使用的示例系统使用具有 2 个核心的 Basic 定价层运行。 更改为 常规用途 定价层可提供多达 64 个核心。
返回到 Cloud Shell 并按 Enter 以停止应用。
你已了解如何使用 Azure 门户中提供的工具监视服务器活动。 你还了解了如何配置复制,并了解了创建只读副本如何在读取密集型数据方案中分配工作负荷。