练习:训练机器学习模型
你从制造设备中收集了正常设备和故障设备的传感器数据。 现在,你想使用 Model Builder 来训练机器学习模型,用于预测机器是否会出现故障。 通过使用机器学习来自动监视这些设备,你可以提供更及时和更可靠的维护,这样可以节省公司的资金。
添加新的机器学习模型 (ML.NET) 项
若要开始训练过程,需要向新的或现有的 .NET 应用程序添加新的机器学习模型 (ML.NET) 项。
创建 C# 类库
由于你是从头开始,因此请创建一个新的 C# 类库项目,你将在其中添加机器学习模型。
启动 Visual Studio。
在“开始”窗口中,选择“创建新项目”。
在“创建新项目”对话框的搜索栏中键入“类库”。
在选项列表中,选择“类库”。 确保语言为 C#,然后选择“下一步”。

在“项目名称”文本框中,输入“PredictiveMaintenance”。 保留所有其他字段的默认值,然后选择“下一步”。
从“框架”下拉列表中选择“.NET 6.0 (预览版)”,然后选择“创建”以搭建 C# 类库的基架。

将机器学习添加到项目中
类库项目在 Visual Studio 中打开后,可以将机器学习模型添加到项目中。
在 Visual Studio 解决方案资源管理器中,右键单击项目。
选择“添加”>“机器学习模型”。
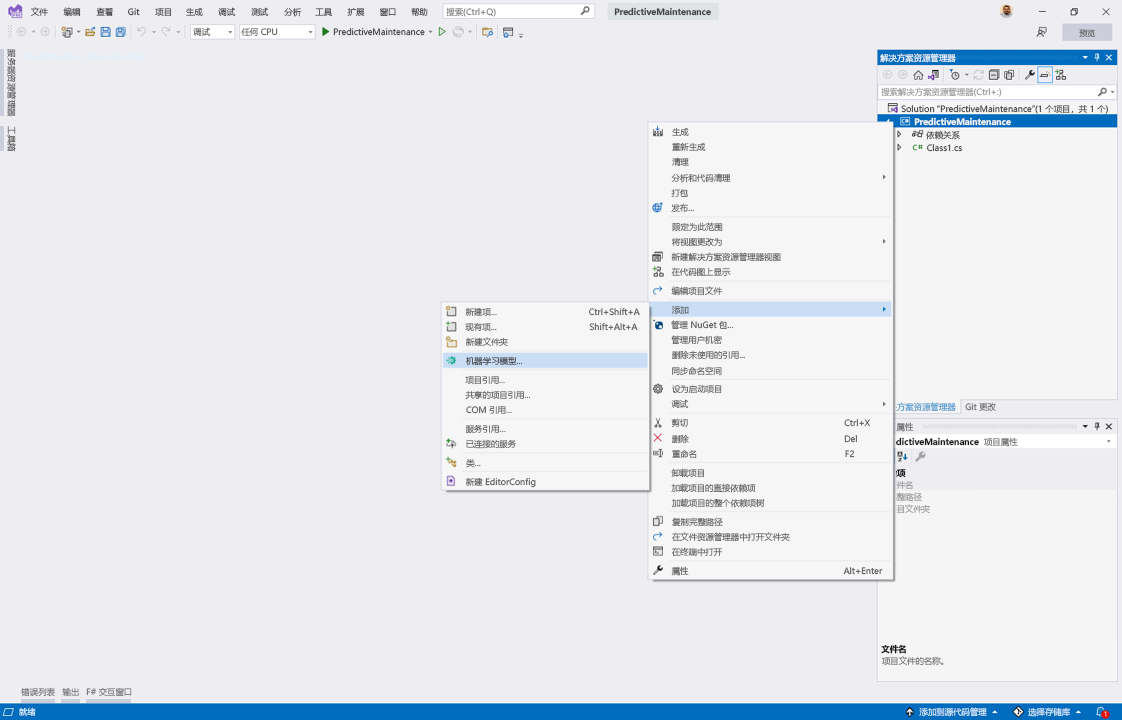
在“添加新项”对话框的新项列表中,选择“机器学习模型 (ML.NET)”。
在“名称”文本框中,使用“PredictiveMaintenanceModel.mbconfig”作为模型的名称,然后选择“添加”。


几秒钟后,系统会将名为 PredictiveMaintenanceModel.mbconfig 的文件到项目中。
选择场景
第一次将机器学习模型添加到项目时,将打开 Model Builder 屏幕。 现在可以选择场景。
你的用例是尝试确定机器是否损坏。 由于只存在两种选项,而你要确定机器的状态,因此数据分类场景最合适。
在 Model Builder 屏幕的“场景”步骤中,选择“数据分类”场景。 选择此场景后,将立即进入“环境”步骤。

选择环境
对于数据分类场景,仅支持使用 CPU 的本地环境。
- 在 Model Builder 屏幕的“环境”步骤中,默认选择“本地(CPU)”。 保留默认选择的环境。
- 选择下一步。

加载和准备数据
选择场景和训练环境后,便可以加载和准备使用 Model Builder 收集的数据。
准备数据
在选择的文本编辑器中打开文件。
原始列名包含特殊括号字符。 若要防止分析数据时出现问题,请从列名中删除特殊字符。
原始标题:
UDI,Product ID,Type,Air temperature [K],Process temperature [K],Rotational speed [rpm],Torque [Nm],Tool wear [min],Machine failure,TWF,HDF,PWF,OSF,RNF更新的标题:
UDI,Product ID,Type,Air temperature,Process temperature,Rotational speed,Torque,Tool wear,Machine failure,TWF,HDF,PWF,OSF,RNF保存更改后的 ai4i2020.csv 文件。
选择数据源类型
预测性维护数据集是 CSV 文件。
在 Model Builder 屏幕的“数据”步骤中,在“数据源类型”处选择“文件(csv、tsv、txt)”。
提供数据的位置
选择“浏览”按钮,并使用文件资源管理器提供 ai4i2020.csv 数据集的位置。
选择标签列
从“要预测的列(标签)”下拉列表中选择“计算机故障”。

选择高级数据选项
默认情况下,所有不是标签的列都用作特征。 某些列包含冗余信息,而其他列不提供预测的信息。 使用高级数据选项可忽略这些列。
选择“高级数据选项”。
在“高级数据选项”对话框中,选择“列设置”选项卡。
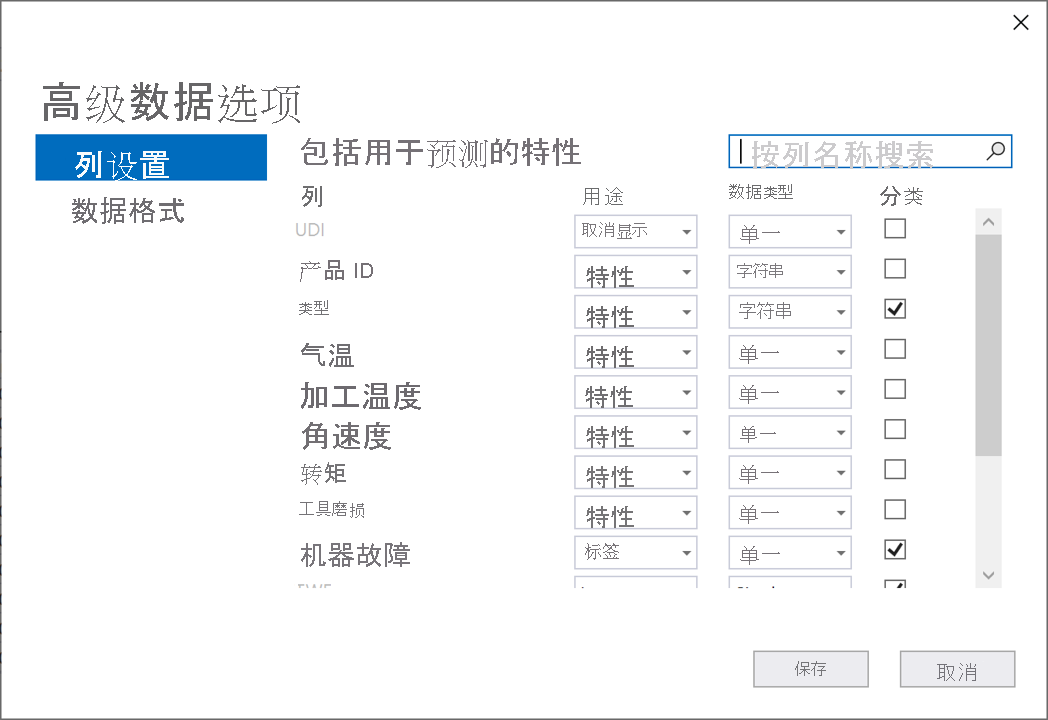
按如下所示配置列设置:
列数 目的 数据类型 分类 UDI 忽略 Single 产品 ID 功能 字符串 类型 功能 字符串 X Air temperature 功能 Single Process temperature 功能 Single Rotational speed 功能 Single 转矩 功能 Single Tool wear 功能 Single Machine failure 标签 Single X TWF 忽略 Single X HDF 忽略 Single X PWF 忽略 Single X OSF 忽略 Single X RNF 忽略 Single X 选择“保存”。
在 Model Builder 屏幕的“数据”步骤中,选择“下一步”。

训练模型
使用 Model Builder 和 AutoML 训练模型。
设置训练时间
Model Builder 根据文件大小自动设置训练时长。 在这种情况下,为帮助 Model Builder 浏览更多模型,请为训练时间提供更大的数字。
- 在 Model Builder 屏幕的“训练”步骤中,将“训练时间(秒)”设置为 30。
- 选择“训练”。
跟踪训练过程

训练过程开始后,Model Builder 将浏览各种模型。 系统会在训练结果和 Visual Studio 输出窗口中跟踪训练过程。 训练结果提供有关在整个训练过程中找到的最佳模型的信息。 输出窗口提供详细信息,例如所用算法的名称、训练花费的时间以及该模型的性能指标。
同一算法名称可能会多次显示。 出现这种情况是因为 Model Builder 除了尝试不同的算法之外,还为这些算法尝试不同的超参数配置。
评估模型
使用评估指标和数据来测试模型的性能。
检查模型
在 Model Builder 屏幕的“评估”步骤中,你可以检查为最佳模型选择的评估指标和算法。 请记住,如果结果不同于本模块中提到的结果也没关系,因为选择的算法和超参数可能不同。
测试模型
在“评估”步骤的“尝试模型”部分中,可以提供新数据并评估预测结果。

在“示例数据”部分,你可以为模型提供输入数据进行预测。 每个字段对应于用于训练模型的列。 这是验证模型行为是否符合预期的简便方法。 默认情况下,Model Builder 使用数据集中的第一行预填充示例数据。
接下来测试模型,看是否能生成预期结果。
在“示例数据”部分中,输入以下数据。 这些数据源自数据集中 UID 为 161 的行。
列 值 产品 ID L47340 类型 L Air temperature 298.4 Process temperature 308.2 Rotational speed 1282 转矩 60.7 Tool wear 216 选择“预测”。
评估预测结果
“结果”部分显示模型进行的预测以及该预测的置信度。
如果查看数据集中 UID 161 的“Machine failure”列,你会注意到值为 1。 这与“结果”部分中置信度最高的预测值相同。
如果需要,可以继续使用不同的输入值来尝试模型,并评估预测。
祝贺你! 你训练出一个用来预测机器故障的模型。 下一单元将介绍模型使用。