练习 - 构建机器学习模型
若要创建机器学习模型,你需要两个数据集:一个用于训练,另一个用于测试。 实际上,你通常只有一个数据集,因此请将其拆分为两个数据集。 在本练习中,你将对上一实验室中准备的 DataFrame 执行 80-20 拆分,以便你可以使用它来定型机器学习模型。 你还会将 DataFrame 分为特征列和标签列。 前者包含用作模型输入的列(例如,航班的出发地和目的地以及计划出发时间),而后者包含模型将尝试预测的列,在本示例中为 ARR_DEL15 列,其指示航班是否准点到达。
切换回到你在上一部分中创建的 Azure Notebook。 如果关闭了该笔记本,可重新登录 Microsoft Azure Notebooks 门户,打开笔记本,然后使用“单元格”->“全部运行”,在打开笔记本后重新运行笔记本中的所有单元格。
在笔记本末尾的新单元格中,输入并执行以下语句:
from sklearn.model_selection import train_test_split train_x, test_x, train_y, test_y = train_test_split(df.drop('ARR_DEL15', axis=1), df['ARR_DEL15'], test_size=0.2, random_state=42)第一个语句导入 Scikit-learn 的 train_test_split helper 函数。 第二行使用该函数将 DataFrame 拆分为包含 80% 原始数据的训练集,以及包含剩余 20% 原始数据的测试集。
random_state参数对用于执行拆分的随机数生成器播种,而第一个和第二个参数是包含特征列和标签列的 DataFrame。train_test_split返回四个 DataFrame。 使用以下命令显示包含用于训练的特征列的 DataFrame 中的行数和列数:train_x.shape现在,使用此命令显示包含用于测试的特征列的 DataFrame 中的行数和列数:
test_x.shape两个输出有何不同,为什么?
如果在另外两个 DataFrame train_y 和 test_y 上调用了 shape,你能预测会看到什么吗? 如果你不确定,请尝试并找出答案。
有许多类型的机器学习模型。 其中最常见的一个模型是回归模型,它使用回归算法之一来生成数字值,例如,一个人的年龄或信用卡交易是欺诈交易的概率。 你将定型一个分类模型,该模型寻求将一组输入解析为一组已知输出之一。 分类模型的典型示例是检查电子邮件并将其归类为“垃圾邮件”或“非垃圾邮件”的模型。你的模型将是二进制分类模型,可预测航班将准点到达还是晚点(“二进制”是因为只有两个可能的输出)。
使用 Scikit-learn 的好处之一是,你不必手动构建这些模型或实现其使用的算法。 Scikit-learn 包括用于实现常见机器学习模型的各种类。 其中之一是 RandomForestClassifier,它使多个决策树拟合数据,并使用平均方法来提高整体准确率及限制过度拟合。
在新单元格中执行以下代码来创建
RandomForestClassifier对象,并通过调用 fit 方法对其进行训练。from sklearn.ensemble import RandomForestClassifier model = RandomForestClassifier(random_state=13) model.fit(train_x, train_y)输出显示分类器中使用的参数,包括
n_estimators(指定每个决策树林中的树的数量),以及max_depth(指定决策树的最大深度)。 显示的值为默认值,但可以在创建RandomForestClassifier对象时对任意值进行替代。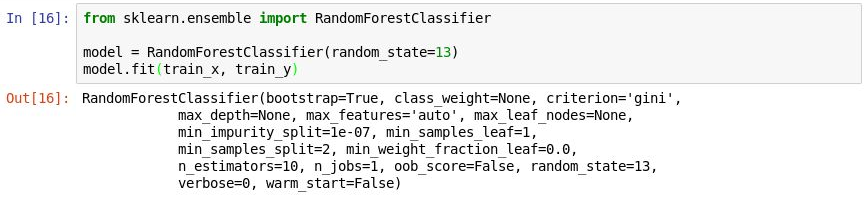
模型定型
现在,调用 predict 方法以使用
test_x中的值测试模型,然后使用 score 方法来确定模型的平均准确率:predicted = model.predict(test_x) model.score(test_x, test_y)确认看到以下输出:

测试模型
平均准确率为 86%,从表面上看似乎很好。 然而,平均准确率并不总是分类模型准确率的可靠指示器。 让我们更深入地探讨并确定模型的真实准确率,即它在确定航班是否准点到达方面的擅长程度。
有多种方法可用于度量分类模型的准确率。 二进制分类模型的最佳整体度量值之一是接收者工作特征曲线下面积(有时称为“ROC AUC”),它实质上量化了模型进行正确预测的频率,而不管结果如何。 在本单元中,你将计算之前构建的模型的 ROC AUC 分数,并了解该分数低于 score 方法输出的平均准确率的部分原因。 你还将了解估计模型准确率的其他方法。
在计算 ROC AUC 之前,你必须为测试集生成预测概率。 这些概率是模型可以预测的每个类或答案的估计值。 例如,
[0.88199435, 0.11800565]表示航班准点到达的几率为 89% (ARR_DEL15 = 0),不能准点到达的几率为 12% (ARR_DEL15 = 1)。 两个概率的总和为 100%。运行以下代码,从测试数据生成一组预测概率:
from sklearn.metrics import roc_auc_score probabilities = model.predict_proba(test_x)现在,使用以下语句通过 Scikit-learn 的 roc_auc_score 方法从概率生成 ROC AUC 分数:
roc_auc_score(test_y, probabilities[:, 1])确认输出显示分数为 67%:

生成 AUC 分数
为什么 AUC 分数低于上一练习中计算得出的平均准确率?
score方法的输出反映模型可以对测试集中的多少项进行正确预测。 此分数受到以下事实的影响:用于对模型定型和测试的数据集包含的代表准点到达的行数多于代表晚点到达的行数。 由于数据中的这种不平衡,预测航班准点到达可能会比预测航班晚点到达的正确率要高。ROC AUC 将这一点考虑在内,并提供准点或晚点的预测将为正确预测的可能性的更准确指示。
你可以通过生成混淆矩阵(也称为错误矩阵)来了解有关模型行为的详细信息。 混淆矩阵量化每个答案被正确分类或错误分类的次数。 具体而言,它量化了假正、假负、真正和真负的数量。 这很重要,因为如果使用包含 95% 的狗的数据集测试训练用于识别猫和狗的二进制分类模型,那么每次只需猜测“狗”,分数就可达到 95%。 但如果该模型根本不能识别猫,那就没有任何意义。
使用以下代码为你的模型生成混淆矩阵:
from sklearn.metrics import confusion_matrix confusion_matrix(test_y, predicted)输出中的第一行表示准点到达的航班。 该行的第一列显示正确预测为准点到达的航班的数量,而第二列则显示预测为晚点但实际未晚点的航班的数量。 由此可以看出,该模型似乎擅长预测航班准点到达。

生成混淆矩阵
但请看第二行,它代表晚点的航班。 第一列显示被错误预测为准点到达的晚点航班的数量。 第二列显示正确预测为晚点的航班的数量。 显然,该模型并不像预测航班将准点到达那样善于预测航班将晚点。 你在混淆矩阵中所需的内容是左上角和右下角的大数字,以及右上角和左下角的小数字(最好是零)。
分类模型的其他准确率度量值包括精确率和召回率。 假设向该模型提供了三个准点到达的航班和三个晚点到达的航班,并且它正确预测了其中两个准点到达的航班,但错误地将其中两个晚点到达的航班预测为准点到达。 在这种情况下,精确率将为 50%(在其分类为准点到达的四个航班中,实际上有两个航班准点到达),而其召回率为 67%(它正确识别了三个准点到达的航班中的两个)。 有关精确率和召回率的详细信息,请访问 https://en.wikipedia.org/wiki/Precision_and_recall
Scikit-learn 包含名为 precision_score 的便捷方法,可用于计算精确率。 若要量化模型的精确率,请执行以下语句:
from sklearn.metrics import precision_score train_predictions = model.predict(train_x) precision_score(train_y, train_predictions)检查输出。 模型的精确率如何?

度量精确率
Scikit-learn 还包含名为 recall_score 的方法,可用于计算召回率。 若要度量模型的召回率,请执行以下语句:
from sklearn.metrics import recall_score recall_score(train_y, train_predictions)模型的召回率如何?

度量召回率
使用“文件”->“保存和检查点”命令来保存笔记本。
在现实生活中,训练有素的数据科学家会寻找让模型变得更准确的方法。 除此之外,他们还会尝试不同的算法,并采取措施调整所选择的算法,以找到最佳参数组合。 另一个可能的措施是将数据集扩展到数百万行而不是几千行,并同时尝试减少晚点和准点到达之间的不平衡。 但就我们的目的而言,该模型保持原样就很好。