配置提前终止
超参数优化有助于微调模型,并选择使模型性能最佳的超参数值。
为了找到最佳模型,可能是一场永无休止的追求。 你始终必须考虑是否值得测试新的超参数值的时间和费用,才能找到性能更好的模型。
扫描作业中的每个试验都会使用超参数值的新组合训练一个新模型。 如果训练新模型不会生成明显更好的模型,则可能需要停止扫描作业并使用到目前为止性能最佳的模型。
在 Azure 机器学习中配置扫描作业时,还可以设置最大试用版数。 更复杂的方法是,当较新的模型不会产生显著更好的结果时,可能会停止扫描作业。 若要根据模型的性能停止扫描作业,可以使用 提前终止策略。
何时使用提前终止策略
是否想要使用早期终止策略可能取决于正在使用的搜索空间和采样方法。
例如,可以选择对 离散 搜索空间使用 网格采样 方法,从而最多产生六次试验。 在六次试验中,最多将训练六个模型,并可能不需要提前终止策略。
在搜索空间中使用连续超参数时,早期终止策略尤其有用。 连续超参数提供无限数量的可能值可供选择。 使用连续超参数和随机或贝伊斯采样方法时,你很可能想要使用早期终止策略。
配置提前终止策略
选择使用提前终止策略时,有两个主要参数:
-
evaluation_interval:指定要评估策略的时间间隔。 每次记录试验的主要指标都会被视为一个间隔。 -
delay_evaluation:指定何时开始评估策略。 此参数确保至少有一个最低数量的试验在不受提前终止策略影响的情况下完成。
新模型可能只会比以前的模型稍微好一些。 若要确定模型应比以前的试验性能更好的程度,有三种提前终止选项:
-
强盗策略:使用
slack_factor(相对)或slack_amount(绝对)。 任何新模型都必须在性能最佳的模型的宽延范围内执行。 - 中值停止策略:使用主要指标平均值的中值。 任何新模型的性能都必须优于中值。
-
截断选择策略:使用
truncation_percentage,这是最低表现试验的百分比。 任何新模型的性能必须优于性能最低的试验。
强盗策略
如果目标性能指标低于迄今为止最好的试验,并且相差超过指定的边距,可以使用强盗策略来停止试验。
例如,以下代码应用一个延迟为五次试用的强盗策略,每隔一次评估策略,并允许绝对的松散量为 0.2。
from azure.ai.ml.sweep import BanditPolicy
sweep_job.early_termination = BanditPolicy(
slack_amount = 0.2,
delay_evaluation = 5,
evaluation_interval = 1
)
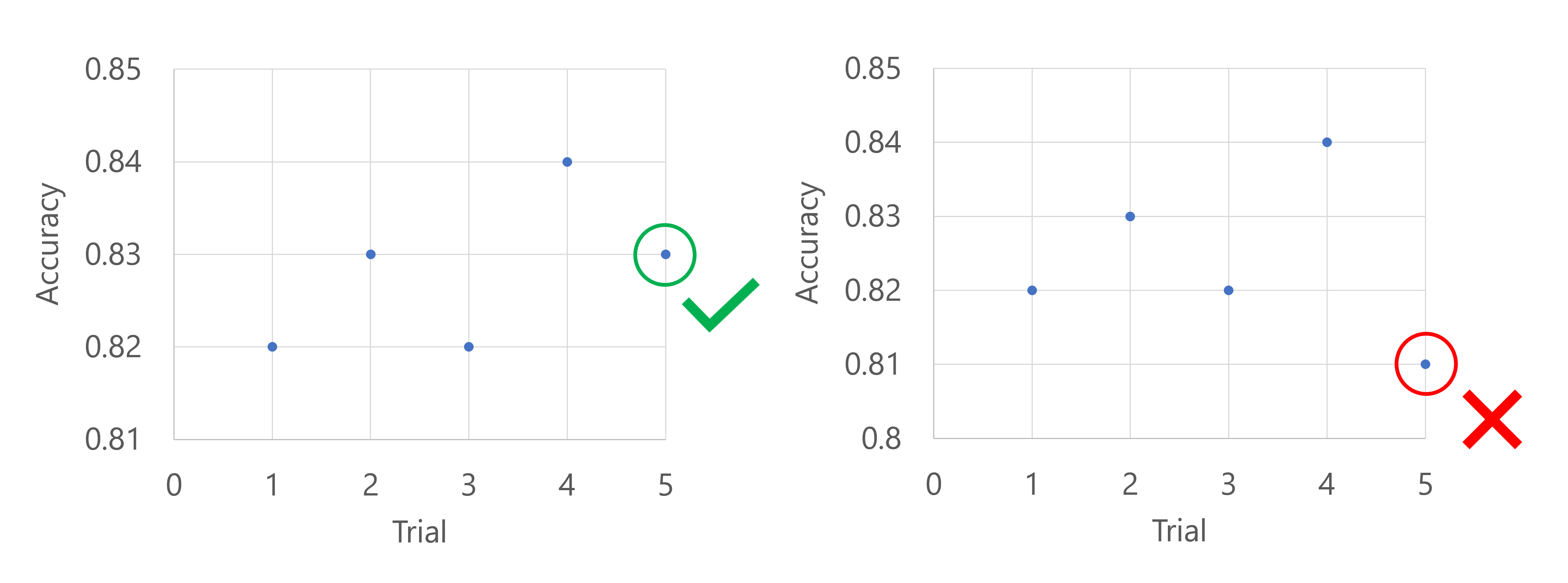
假设主要指标是模型的准确性。 在前五次试验之后,性能最佳的模型的准确性为 0.9,任何新模型的性能都需要优于 (0.9-0.2) 或 0.7。 如果新模型的准确性高于 0.7,则扫描作业将继续。 如果新模型的准确性分数低于 0.7,则策略将终止扫描作业。
使用强盗策略时,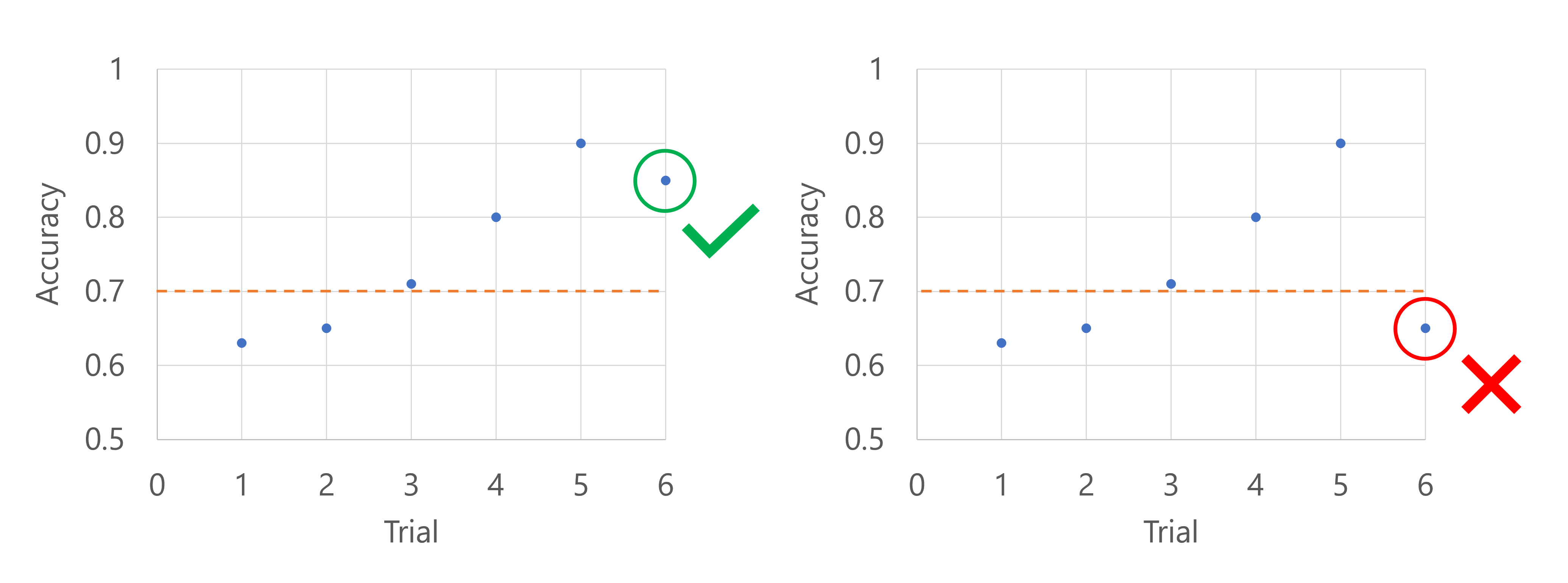
还可以使用 slack 因子应用强盗策略,它将性能指标作为比率而不是绝对值进行比较。
中值停止策略
中值停止策略会放弃那些目标性能指标低于所有试验的运行平均值中位数的试验。
例如,以下代码应用了延迟五次试验的中值停止策略,并在每个间隔评估该策略。
from azure.ai.ml.sweep import MedianStoppingPolicy
sweep_job.early_termination = MedianStoppingPolicy(
delay_evaluation = 5,
evaluation_interval = 1
)
假设主要指标是模型的准确性。 当第六次试验记录准确性时,该指标需要高于到目前为止准确度分数的中值。 假设到目前为止准确度分数的中位数为 0.82。 如果新模型的准确性高于 0.82,则扫描作业将继续。 如果新模型的准确性分数低于 0.82,则策略将停止扫描作业,并且不会训练新模型。
使用中值停止策略的两个示例关系图:一个模型表现良好,另一个模型表现欠佳。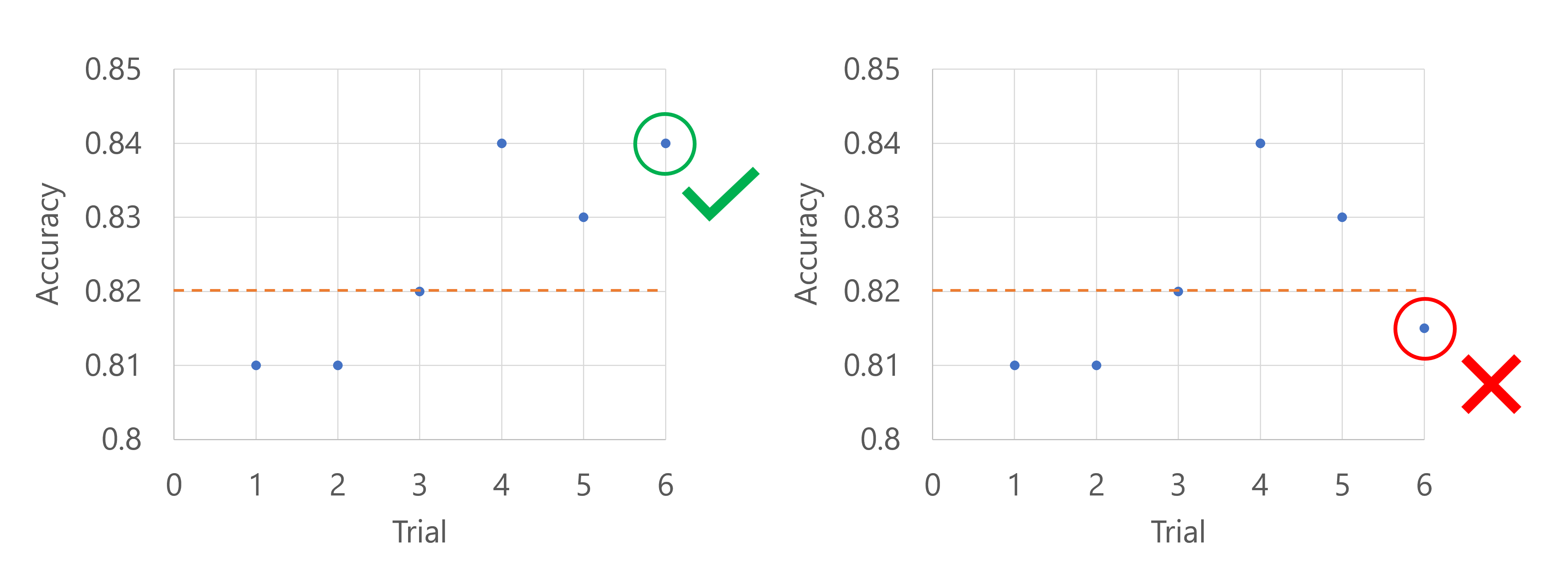
截断选择策略
截断选择策略根据为 X指定的 truncation_percentage 值,在每个评估间隔取消每个试验 X% 的最低性能。
例如,以下代码应用一个延迟为四次试验的截断选择策略,每隔一次评估策略,并使用截断百分比为 20%。
from azure.ai.ml.sweep import TruncationSelectionPolicy
sweep_job.early_termination = TruncationSelectionPolicy(
evaluation_interval=1,
truncation_percentage=20,
delay_evaluation=4
)
假设主要指标是模型的准确性。 记录第五次试验的准确性时,指标应 不 目前最差的 20 个试验%。 在这种情况下,20 个% 转换为一次试验。 换句话说,如果第五次试验 不是 到目前为止表现最差的模型之一,扫查任务将继续。 如果第五次试验的准确性得分是迄今为止所有试验中最低的,扫面任务将停止。
使用截断选择策略时,