练习 - 将 Kafka 数据流式传输到 Jupyter Notebook 并为数据设定窗口
Kafka 群集正在将数据写入其日志,该操作可通过 Spark 结构化流处理。
Spark 笔记本包含在你克隆的示例中,因此你需要将该笔记本上传到 Spark 群集才能使用它。
将 Python 笔记本上传到 Spark 群集
在 Azure 门户中,单击“主页”>“HDInsight 群集”,然后选择刚刚创建的 Spark 群集(而不是 Kafka 群集)。
在“群集仪表板”窗格中,单击“Jupyter Notebook”。

提示输入凭据时,请输入管理员的用户名,并输入创建群集时创建的密码。 此时将显示 Jupyter 网站。
单击“PySpark”,然后在 PySpark 页中单击“上传”。
导航到你从 GitHub 下载示例的位置,选择 RealTimeStocks.ipynb 文件,依次单击“打开”、“上传”,然后在 Internet 浏览器中单击“刷新”。
笔记本上传到 PySpark 文件夹后,单击“RealTimeStocks.ipynb”在浏览器中打开笔记本。
将光标放置在笔记本的第一个单元格中,然后按 Shift+Enter,运行该单元格。
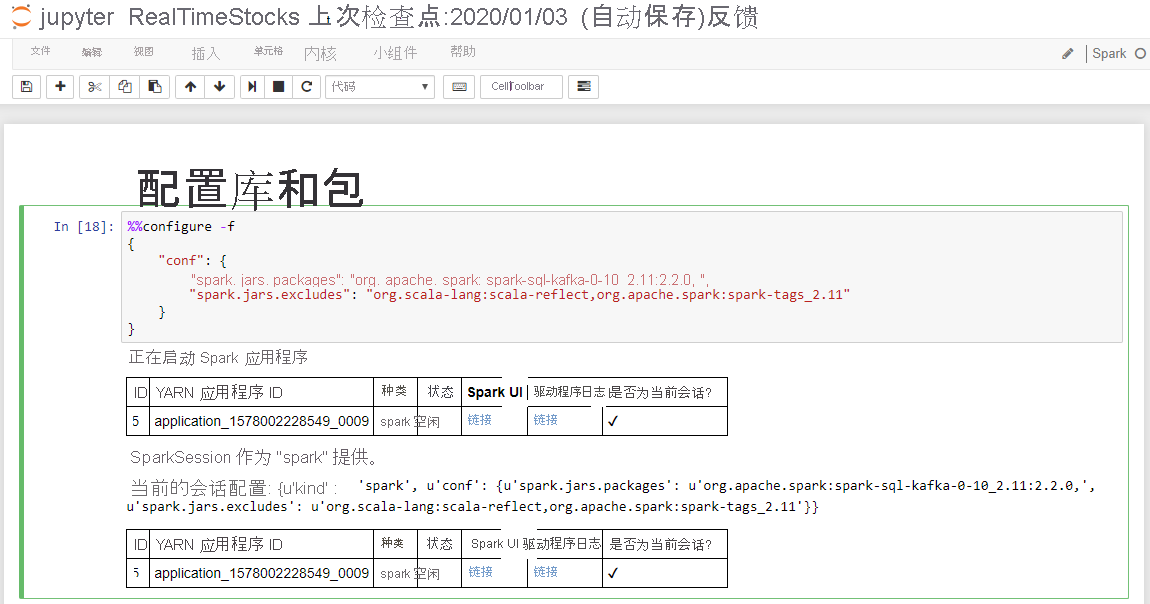
如果“配置库和包”单元格显示“启动 Spark 应用程序”消息和如以下屏幕截图所示的其他信息,说明该单元格的操作已成功完成。
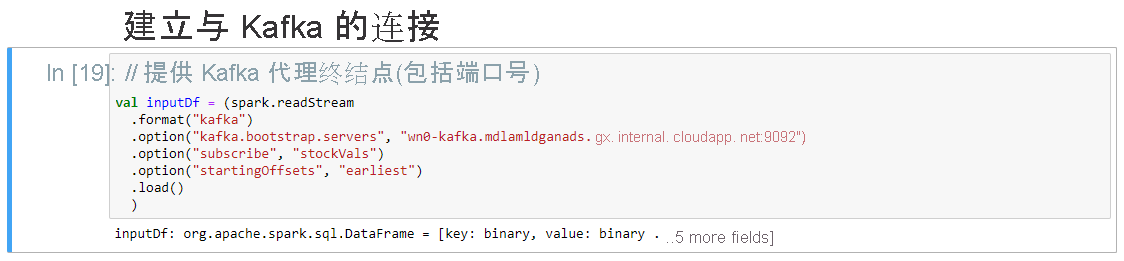
在“设置与 Kafka 的连接”单元格中的 .option("kafka.bootstrap.servers", "") 行中,在第二组引号间输入 Kafka 中转站。 例如, .option("kafka.bootstrap.servers", "wn0-kafka.mdlamldganads.gx.internal.cloudapp.net:9092"),然后单击“Shift+Enter”来运行单元格。
“设置与 Kafka 的连接”单元格显示消息 inputDf: org.apache.spark.sql.DataFrame = [key: binary, value: binary ...5 more fields] 时,说明它已成功完成。 Spark 使用 readStream API 读取数据。
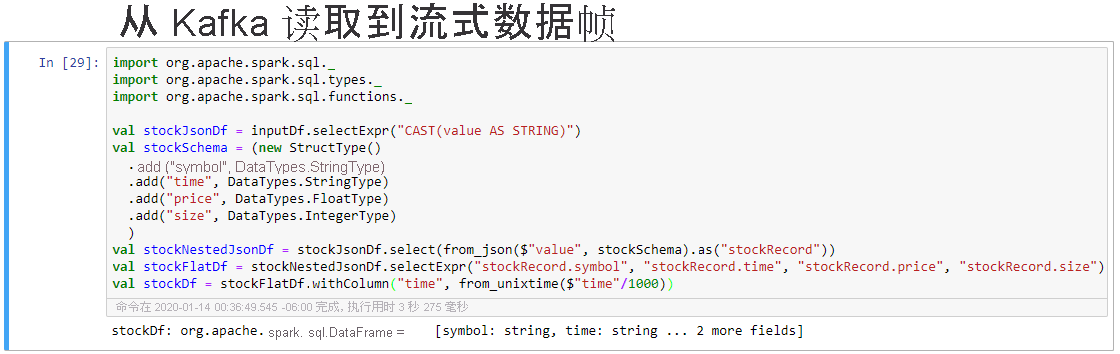
选择“从 Kafka 读取到流式数据帧”单元格,然后单击“Shift+Enter”来运行单元格。
单元格显示以下消息时,说明它已成功完成:stockDf: org.apache.spark.sql.DataFrame = [symbol: string, time: string ...2 more fields]
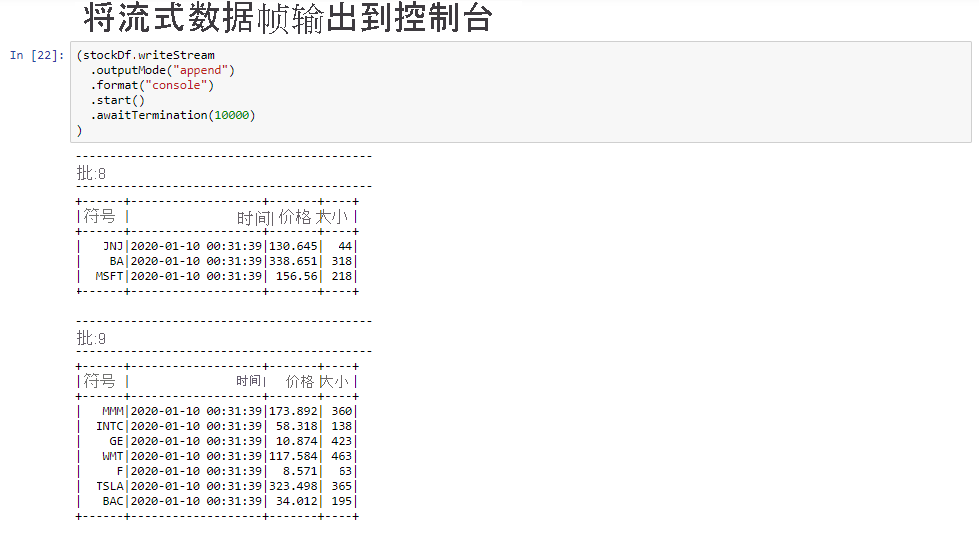
选择“将流式数据帧输出到控制台”单元格,然后单击“Shift+Enter”运行单元格。
当单元格显示类似下面的信息时,说明已成功完成。 输出显示在微批处理中传递的每个单元格的值,并且批处理每秒一次。
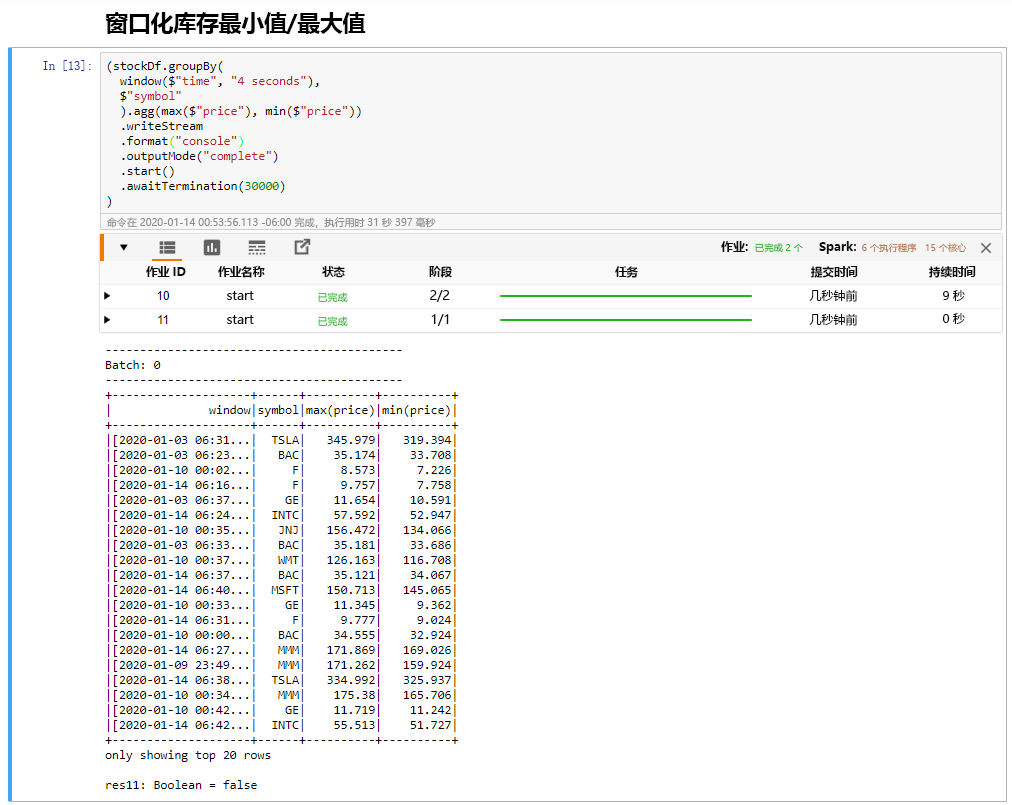
选择“分时段的股票最小值/最大值”单元格,然后单击“Shift+Enter”运行单元格。
当单元格在 4 秒的窗口(在单元格中定义)中为每只股票提供最高价格和最低价格时,说明已成功完成该单元格。 如上一个单元所述,使用 Spark 结构化流的一个好处是提供有关特定窗口的信息。
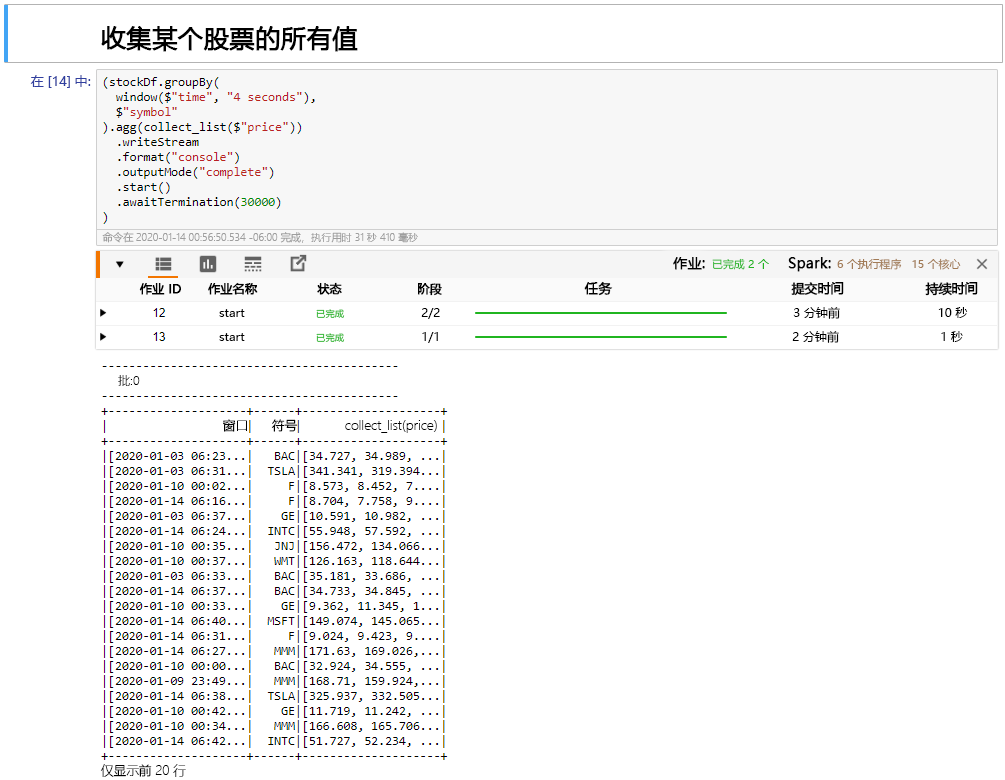
选择窗口单元格中的“收集股票的所有值”,然后单击“Shift+Enter”来运行单元格。
单元格提供一个股价表时,说它已成功完成。 outputMode 已完成,因此显示了所有数据。
在本单元中,你已将 Jupyter Notebook 上传到 Spark 群集,将其连接到 Kafka 群集,将 Python 制作者文件创建的流数据输出到 Spark 笔记本,为流数据定义了窗口,并在该窗口中显示了高低股价,还在表中显示了股票的所有值。 恭喜,你已成功使用 Spark 和 Kafka 执行结构化流!