选择合适的 MPI 库
HB120_v2、HB60 和 HC44 SKU 都支持 InfiniBand 网络互连。 因为 PCI express 是通过单根输入/输出 (SR-IOV) 虚拟化实现虚拟化的,所以这些 HPC VM 上提供所有热门 MPI 库(HPCX、OpenMPI、Intel MPI、MVAPICH 和 MPICH)。
当前可以通过 InfiniBand 通信的 HPC 群集的限制是 300 个 VM。 下表列出了通过 InfiniBand 通信的紧密耦合 MPI 应用程序中支持的最大并行进程数。
| SKU | 最大并行进程数 |
|---|---|
| HB120_v2 | 36000 个进程 |
| HC44 | 13200 个进程 |
| HB60 | 18000 个进程 |
注意
这些限制将来可能会发生更改。 如果你的紧密耦合 MPI 作业需要更高的限制,请提交支持请求。 可能会根据你的情况提高限制。
如果 HPC 应用程序推荐特定的 MPI 库,请先试用该版本。 如果可以灵活选择 MPI,并想要获得最佳性能,请尝试 HPCX。 总体而言,HPCX MPI 为 InfiniBand 接口使用 UCX 框架时表现最佳,并具有所有 Mellanox InfiniBand 硬件和软件功能的优势。
下图比较了热门的 MPI 库体系结构。
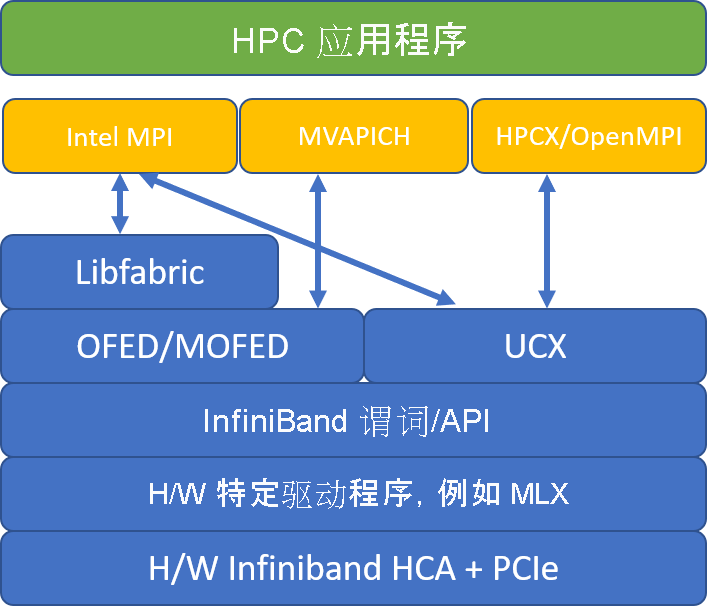
HPCX 和 OpenMPI 兼容 ABI,因此你可以使用通过 OpenMPI 生成的 HPCX 动态运行 HPC 应用程序。 同样,Intel MPI、MVAPICH 和 MPICH 也兼容 ABI。
为了防止通过低级硬件访问产生任何安全漏洞,来宾 VM 无法访问队列对 0。 这不会对最终用户 HPC 应用程序产生任何影响,但可能会妨碍某些低级别工具正常运行。
HPCX 和 OpenMPI mpirun 参数
以下命令说明了一些适用于 HPCX 和 OpenMPI 的建议 mpirun 参数:
mpirun -n $NPROCS --hostfile $HOSTFILE --map-by ppr:$NUMBER_PROCESSES_PER_NUMA:numa:pe=$NUMBER_THREADS_PER_PROCESS -report-bindings $MPI_EXECUTABLE
在该命令中:
| 参数 | 说明 |
|---|---|
$NPROCS |
指定 MPI 进程的数量。 例如:-n 16。 |
$HOSTFILE |
指定包含主机名或 IP 地址的文件,以指示 MPI 进程运行的位置。 例如:--hostfile hosts。 |
$NUMBER_PROCESSES_PER_NUMA |
指定在每个 NUMA 域中运行的 MPI 进程数。 例如,若要为每个 NUMA 指定四个 MPI 进程,请使用 --map-by ppr:4:numa:pe=1。 |
$NUMBER_THREADS_PER_PROCESS |
指定每个 MPI 进程拥有的线程数量。 例如,若要为每个 NUMA 指定一个 MPI 进程和四个线程,请使用 --map-by ppr:1:numa:pe=4。 |
-report-bindings |
打印 MPI 进程映射到内核,这对验证 MPC 进程固定是否正确十分有用。 |
$MPI_EXECUTABLE |
在 MPI 库中指定 MPI 可执行文件生成的链接。 MPI 编译器包装器会自动执行此操作。 例如 mpicc 或 mpif90。 |
如果怀疑紧密耦合 MPI 应用程序正在进行大量的集体通信,则可以尝试启用分层集体 (HCOLL)。 若要启用这些功能,请使用以下参数:
-mca coll_hcoll_enable 1 -x HCOLL_MAIN_IB=<MLX device>:<Port>
Intel MPI mpirun 参数
Intel MPI 2019 版本从 Open Fabrics Alliance (OFA) 框架切换为 Open Fabrics Interfaces (OFI) 框架,当前支持 libfabric。 有两个访问接口可用于 InfiniBand 支持:mlx 和 verbs。 访问接口 mlx 是 HB 和 HC VM 上的首选访问接口。
下述建议的一些 mpirun 参数适用于 Intel MPI 2019 update 5+:
export FI_PROVIDER=mlx
export I_MPI_DEBUG=5
export I_MPI_PIN_DOMAIN=numa
mpirun -n $NPROCS -f $HOSTFILE $MPI_EXECUTABLE
在这些参数中:
| 参数 | 说明 |
|---|---|
FI_PROVIDER |
指定要使用的 libfabric 访问接口,它将影响所用的 API、协议和网络。 verbs 是另一种选择,但通常 mlx 的性能更佳。 |
I_MPI_DEBUG |
指定额外的调试输出级别,这可以提供有关进程的固定位置、使用的协议和网络的详细信息。 |
I_MPI_PIN_DOMAIN |
指定希望采用的固定进程的方式。 例如,可以固定到内核、套接字或 NUMA 域。 在本示例中,我们将此环境变量设为 numa,这意味着将进程固定到 NUMA 节点域。 |
你可以尝试其他一些选项,尤其是在集体操作占用大量时间的情况下。 Intel MPI 2019 update 5+ 支持访问接口 mlx,并使用 UCX 框架与 InfiniBand 通信。 它还支持 HCOLL。
export FI_PROVIDER=mlx
export I_MPI_COLL_EXTERNAL=1
MVAPICH mpirun 参数
下表包含若干建议的 mpirun 参数:
export MV2_CPU_BINDING_POLICY=scatter
export MV2_CPU_BINDING_LEVEL=numanode
export MV2_SHOW_CPU_BINDING=1
export MV2_SHOW_HCA_BINDING=1
mpirun -n $NPROCS -f $HOSTFILE $MPI_EXECUTABLE
在这些参数中:
| 参数 | 说明 |
|---|---|
MV2_CPU_BINDING_POLICY |
指定要使用的绑定策略,这将影响如何将进程固定到内核 ID。 在本例中,你指定 scatter,因此进程将在各个 NUMA 域中均匀分布。 |
MV2_CPU_BINDING_LEVEL |
指定固定进程的位置。 在这种情况下,将其设置为 numanode,这意味着将进程固定到 NUMA 域的各个单元。 |
MV2_SHOW_CPU_BINDING |
指定是否想要获取有关进程固定位置的调试信息。 |
MV2_SHOW_HCA_BINDING |
指定是否想要获取有关每个进程正在使用的主机通道适配器的调试信息。 |