使用接收者操作特征曲线分析分类
分类模型必须将样本分配给类别。 例如,它必须使用大小、颜色和运动等特征来确定对象是徒步旅行者还是树。
我们可通过多种方式改进分类模型。 例如,我们可以确保数据均衡、干净且已缩放。 我们还可更改模型体系结构,并使用超参数从数据和体系结构中挖掘出尽可能多的性能。 最终,我们找到最好的方法来提高测试(或留出)集的性能并声明模型准备就绪。
此时的模型优化可能很复杂,但我们可以使用最后一个简单的步骤来进一步改进模型的工作方式。 不过,为了理解这一点,我们需要回到基础知识。
概率和类别
许多模型有多个决策阶段,最后一个阶段通常只是一个二值化步骤。 在二值化期间,概率转换为硬标签。 例如,假设模型获得了特征,并计算出有 75% 的几率显示为一名徒步旅行者,25% 的几率显示为一棵树。 一个对象不可能是 75% 的徒步旅行者和 25% 的树,它只能是其中一个! 因此,模型应用了一个阈值,通常为 50%。 由于徒步旅行者类大于 50%,因此声明对象为一名徒步旅行者。
阈值为 50% 合乎逻辑,这意味着始终根据模型选择最可能的标签。 但是,如果模型存在偏差,则 50% 的阈值可能不适合。 例如,如果相比徒步旅行者,模型略微倾向于选取树,选取树的频率比它应该的频率高出 10%,我们可以调整决策阈值来解决这个问题。
决策矩阵刷新程序
决策矩阵是评估模型的错误类型的好方法。 这为我们提供了真正 (TP) 率、真负 (TN) 率、假正 (FP) 率和假负 (FN) 率

我们可以从混淆矩阵中计算一些简单的特征。 两个常用特征是:
- 真正率(敏感度):“True”标签被正确识别为“True”的频率。例如,当模型显示的样本实际上是徒步旅行者时,模型预测“徒步旅行者”的频率。
- 假正率(误报率):“False”标签被错误识别为“True”的频率。例如,模型在显示一棵树时预测“徒步旅行者”的频率。
查看真正率和假正率有助于我们了解模型的性能。
请考虑我们的徒步旅行者示例。 理想情况下,真正率非常高,假正率非常低,因为这意味着模型很好地识别了徒步旅行者,并且不会经常将树识别为徒步旅行者。 但是,如果真正率非常高,但假正率也很高,则模型存在偏差;它几乎将遇到的所有对象都识别为徒步旅行者。 同样,我们不希望模型的真正率很低,因为当模型遇到徒步旅行者时,它会将他们标记为树。
ROC 曲线
接收者操作特征 (ROC) 曲线是我们绘制真正率与假正率的图表。
对于初学者来说,ROC 曲线可能令人困惑,主要有两个原因。 第一个原因是,初学者知道模型的真正率和真负率只有一个值,因此 ROC 绘图必须如下所示:
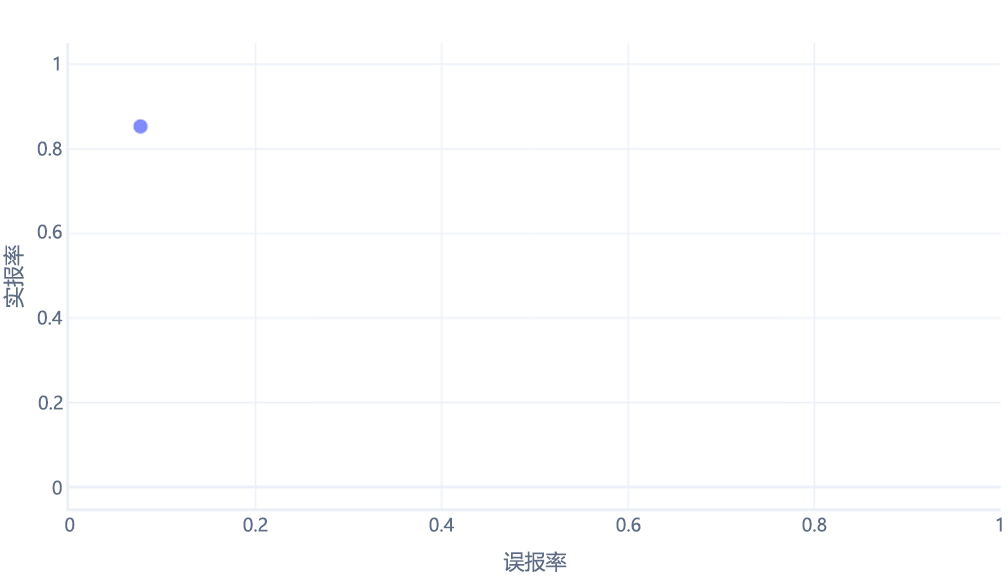
如果你也这么想,那你就对了。 经过训练的模型只生成一个点。 但是,请记住,我们的模型有一个阈值(通常为 50%),用于决定应该使用 true(徒步旅行者)还是 false(树)标签。 如果将此阈值更改为 30%,并重新计算真正率和假正率,则得到另一个点:
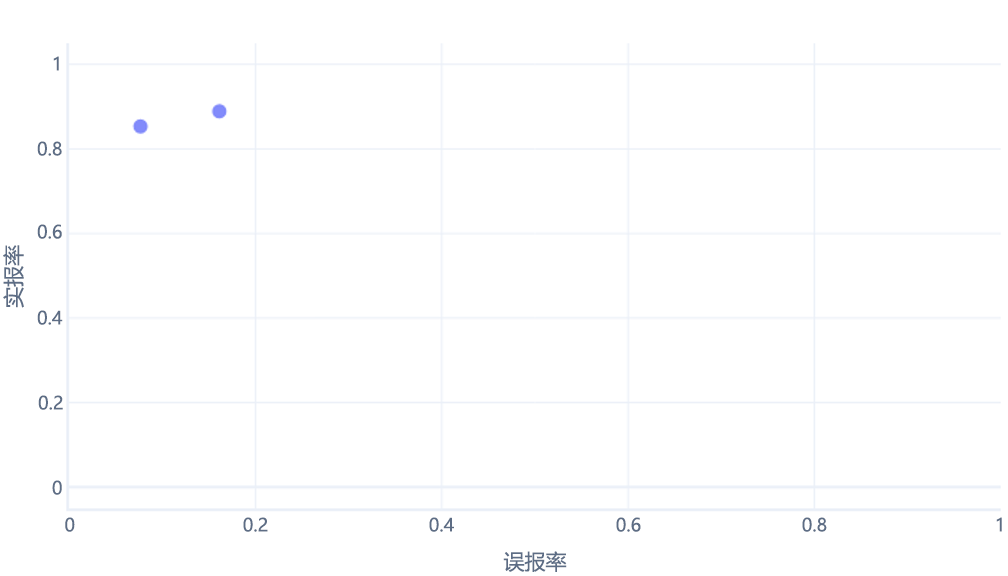
如果针对 0% - 100% 之间的阈值执行此操作,可能会获得如下所示的图:
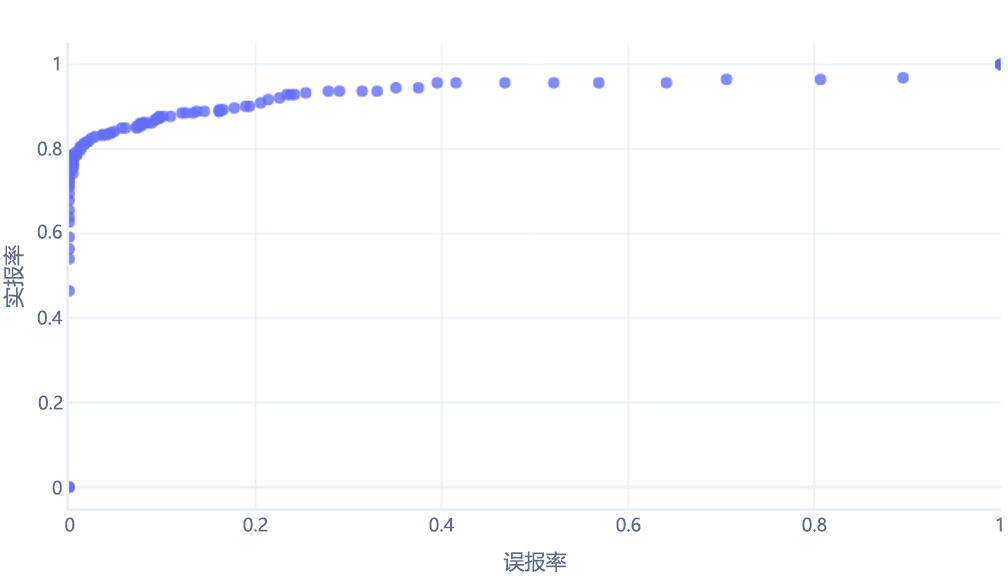
我们通常将其显示为一条线,如下所示:
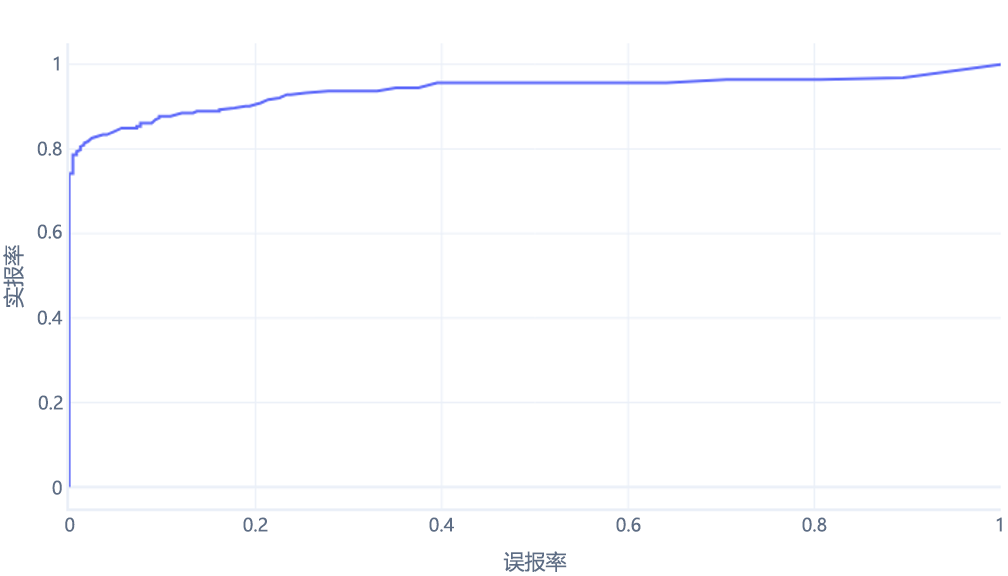
这些图可能令人困惑的第二个原因是涉及的术语。 请记住,我们需要较高的真正率(将徒步旅行者识别为徒步旅行者)和较低的假正率(不将树识别为徒步旅行者)。
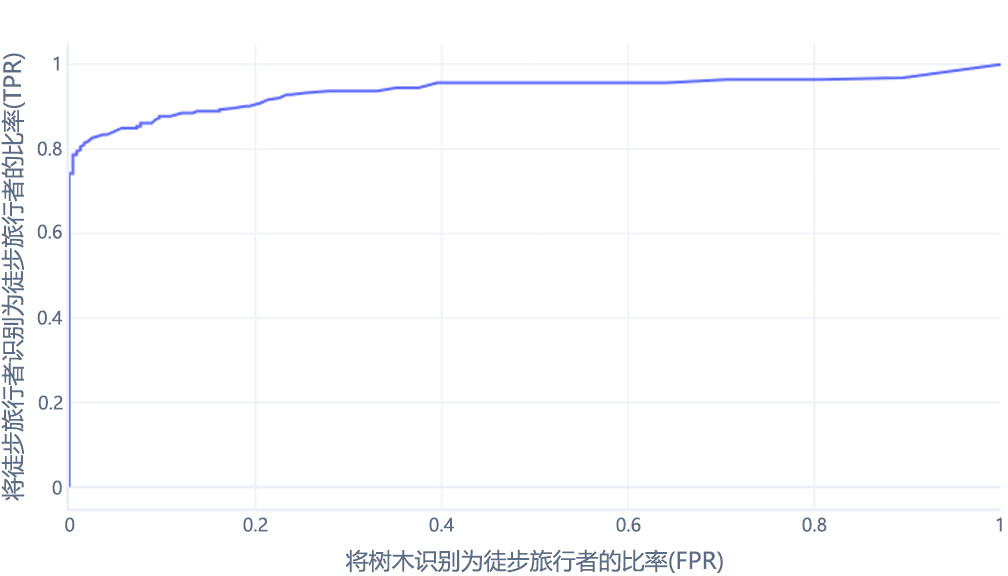
良好 ROC,不良 ROC
最好在交互式环境中来了解良好 ROC 曲线和不良 ROC 曲线。 准备就绪后,请跳转到下一个练习来探索该主题。