合并和优化数据
组织通常整理来自许多源的不同类型的信息。 信息存储在大量的表中。 有时,你可能需要根据表之间的逻辑关系联接表,以便进行更深入的分析或报告。 在零售公司场景中,你使用表来存储客户、产品和销售信息。
在本模块中,你将了解在 Kusto 查询中合并数据的各种方法,以便为团队成员提供提升产品知名度和提高销售额所需的信息。
了解数据
在开始编写用于合并表中信息的查询前,需要了解数据。 使用 Kusto 查询时,需要将表大致归为以下两个类别之一:
- 事实数据表:所含记录是不可变的“事实”的表,例如零售公司场景中的 SalesFact 表。 在这些表中,记录以流式处理方式或以大块的方式逐渐追加。 这些记录会一直保留在表中,直到被删除为止,并且永远不会进行更新。
- 维度表:所含记录是可变的“维度”的表,例如零售公司场景中的 Customers 和 Products 表。 这些表保存引用数据,例如从实体标识符到其属性在内的各种查找表。 维度表不会用新数据定期更新。
在我们的零售公司场景中,请使用维度表为 SalesFact 表扩充附加信息,或提供更多用于筛选查询数据的选项。
此外还需要了解正在使用的数据量及其结构或架构(列名和类型)。 可以通过将 TABLE_NAME 替换为要检查的表的名称来运行以下查询,以获取该信息:
若要获取表中的记录数,请使用
count运算符:TABLE_NAME | count若要获取表的架构,请使用
getschema运算符:TABLE_NAME | getschema
在零售公司场景中,对事实表和维度表运行这些查询将获取类似于以下示例的信息:
| 表 | 记录 | 架构 |
|---|---|---|
| SalesFact | 2,832,193 | - SalesAmount (real) - TotalCost (real) - DateKey (datetime) - ProductKey (long) - CustomerKey (long) |
| 客户 | 18,484 | - CityName (string) - CompanyName (string) - ContinentName (string) - CustomerKey (long) - Education (string) - FirstName (string) - Gender (string) - LastName (string) - MaritalStatus (string) - Occupation (string) - RegionCountryName (string) - StateProvinceName (string) |
| 产品 | 2,517 | - ProductName (string) - Manufacturer (string) - ColorName (string) - ClassName (string) - ProductCategoryName (string) - ProductSubcategoryName (string) - ProductKey (long) |
在表中,我们突出显示了用于合并表之间记录的唯一标识符 CustomerKey 和 ProductKey。
了解多表查询
分析数据后,需要了解如何合并表来提供所需的信息。 Kusto 查询提供了多个运算符,可用于合并来自多个表的数据,包括 lookup、join 和 union 运算符。
join 运算符通过匹配每个表中指定列的值来合并两个表的行。 生成的表取决于所使用的联接类型。 例如,如果使用内联,则表会有与左表(有时称为外部表)相同的列,以及来自右表(有时称为内部表)的列。 在下一部分详细了解联接类型。 为获得最佳性能,如果某个表始终小于另一个表,则将其用作 join 运算符的左侧。
lookup 运算符是 join 运算符的特殊实现,可优化查询的性能,其中事实数据表使用维度表中的数据进行扩充。 它使用在维度表中查找的值扩展事实数据表。 为获得最佳性能,系统默认情况下假定左表是较大的(事实)表,右表是较小的(维度)表。 此假设与 join 运算符使用的假设完全相反。
union 运算符可返回两个或多个表中的所有行。 如果要合并来自多个表的数据,此运算符非常有用。
materialize() 函数在查询执行中缓存结果,以便随后在查询中重复使用。 这类似于获取子查询结果的快照,并在查询中多次使用它。 此函数对于优化特定场景的查询非常有用,这些场景中的结果:
- 计算成本昂贵
- 具有不确定性
稍后详细了解各种表合并运算符和 materialize() 函数,以及如何使用它们。
联接类型
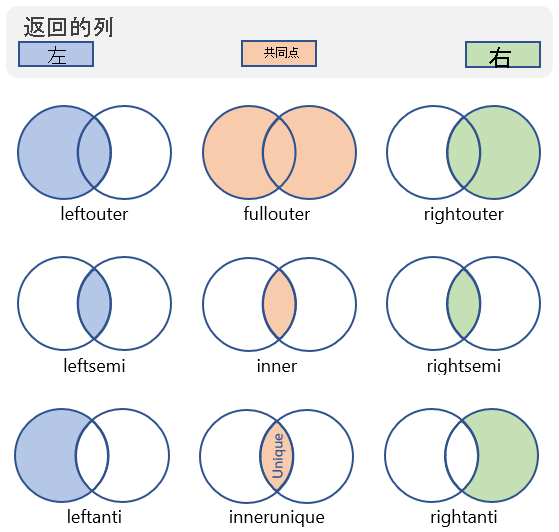
可以执行许多不同类型的联接,它们会影响生成的表中的架构和行。 下表显示了 Kusto 查询语言支持的联接类型以及它们返回的架构和行:
| 联接种类 | 说明 | 图示 |
|---|---|---|
innerunique(默认值) |
执行左侧重复数据删除的内联 架构:两个表中的所有列,包括匹配的键 行:左表中与右表中的行匹配的行,其中已删除重复的行 |

|
inner |
标准内联 架构:两个表中的所有列,包括匹配的键 行:仅限两个表中的匹配行 |

|
leftouter |
左外部联接 架构:两个表中的所有列,包括匹配的键 行:左表中的所有记录,并且仅匹配右表中的行 |

|
rightouter |
右外部联接 架构:两个表中的所有列,包括匹配的键 行:右表中的所有记录,并且仅匹配左表中的行 |

|
fullouter |
完全外联 架构:两个表中的所有列,包括匹配的键 行:两个表中的所有记录,其中不匹配的单元格填充为 null |

|
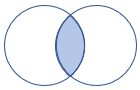
leftsemi |
左半联 架构:左表中的所有列 行:左表中所有与右表中记录相匹配的记录 |
|
leftanti、anti、leftantisemi |
左反联接和半变体 架构:左表中的所有列 行:左表中所有与右表中记录不匹配的记录 |

|
rightsemi |
右半联 架构:右表中的所有列 行:右表中所有与左表中记录相匹配的记录 |

|
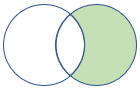
rightanti、rightantisemi |
右反联接和半变体 架构:右表中的所有列 行:右表中所有与左表中记录不匹配的记录 |
|
请注意,默认联接类型为 innerunique,且不需要指定。 不过,为清楚起见,最佳做法是始终显式指定联接类型。
在浏览此模块的过程中,你还将了解 arg_min() 和 arg_max() 聚合函数、as 运算符(作为 let 语句的替代方法)以及有助于按月对数据进行分组的 startofmonth() 函数。