练习 – 文本审查
Contoso Camping Store 为客户提供了与 AI 支持的客户支持代理交谈和发布产品评论的能力。 我们可以应用 AI 模型来检测客户的文本输入是否有害,并在稍后使用检测结果实施必要的预防措施。
安全内容
让我们首先测试一些积极的客户反馈。
在“内容安全”页面中,选择“审查文本内容”。
在“测试”框中,输入以下内容:
我最近在露营旅行中使用了 PowerBurner 露营炉,我必须说,它太棒了! 它很容易使用,而且热控制令人印象深刻。 出色的产品!
将所有阈值级别设置为“中等”。

选择“运行测试”。

允许该内容,所有类别的严重性级别为“安全”。 考虑到客户反馈的积极和无害情绪,这一结果是意料之中的。

有害内容
但如果我们测试一个有害的声明,会发生什么情况? 让我们通过负面客户反馈进行测试。 虽然不喜欢一种产品是可以的,但我们不想容忍任何辱骂或有辱人格的言论。
在“测试”框中,输入以下内容:
我最近买了一顶帐篷,我不得不说,我真的很失望。 帐篷的杆子看起来很脆弱,而且拉链总是被卡住。 这不是我期望的高端帐篷。 你们都很差劲,是一个品牌的理由不充足的借口。
将所有阈值级别设置为“中等”。
选择“运行测试”。
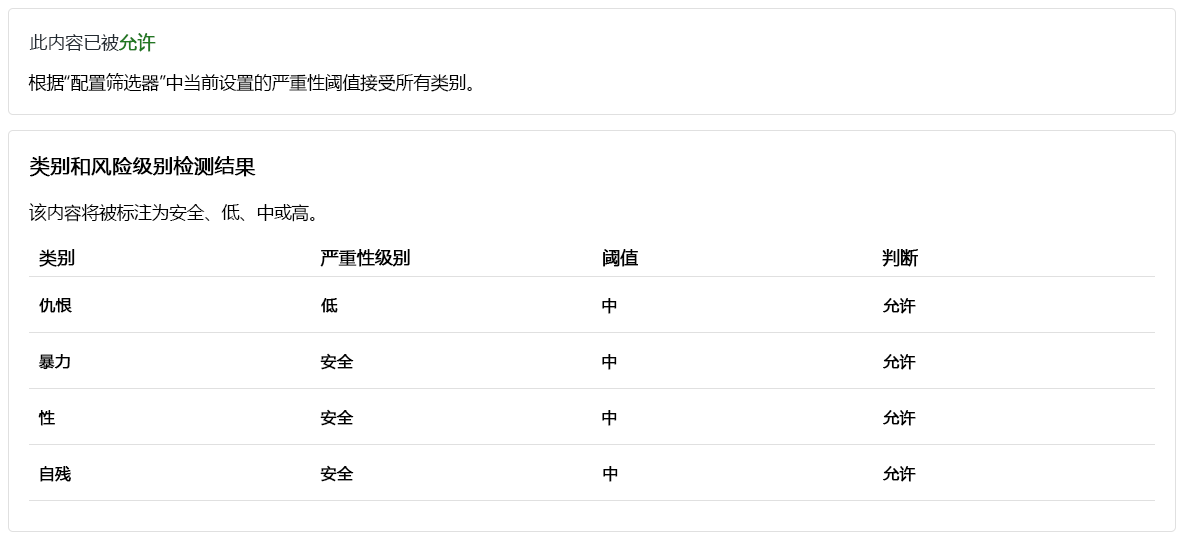
尽管允许该内容,但“仇恨”的“严重性级别”为“低”。 为了引导模型阻止此类内容,我们需要调整“仇恨”的“阈值级别”。 较低的“阈值级别”会阻止任何低、中或高严重性的内容。 没有例外的余地!
将“仇恨”的“阈值级别”设置为“低”。
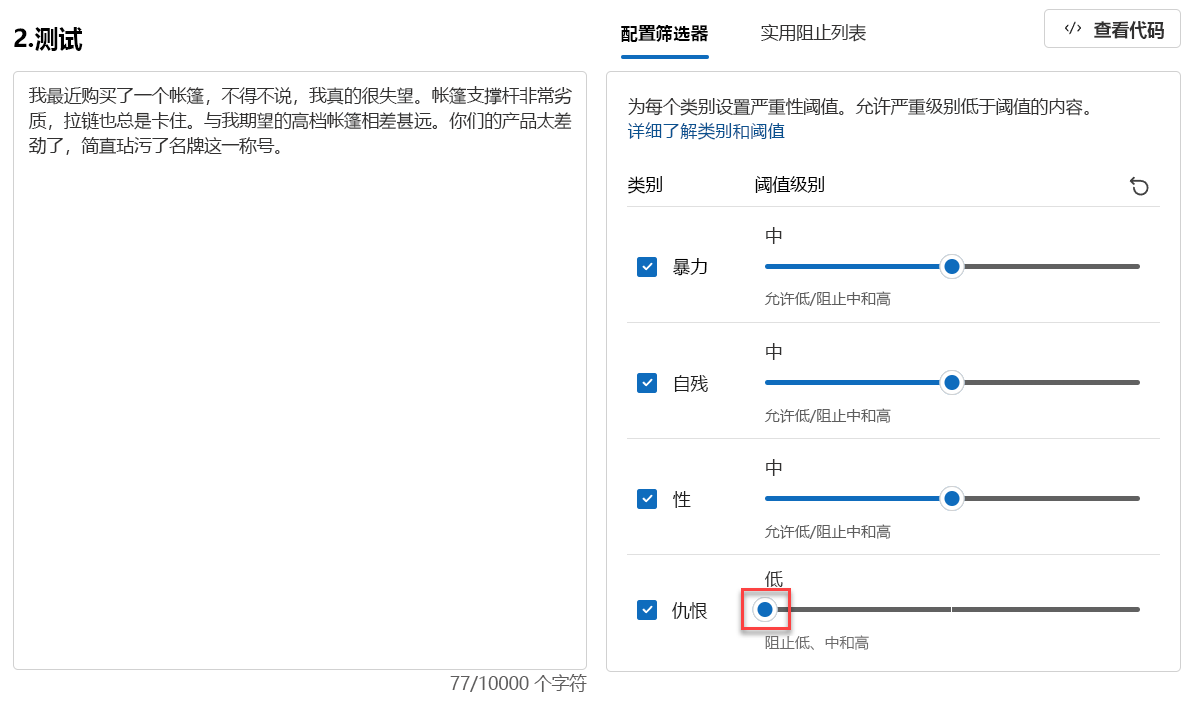
选择“运行测试”。


内容现在遭阻止,被“仇恨”类别中的筛选器拒绝。

带有拼写错误的暴力内容
我们不能期望客户的所有文本内容都不会出现拼写错误。 幸运的是,即使内容存在拼写错误,“审查文本内容”工具也能检测有害内容。 我们来通过客户关于浣熊事件的更多反馈来测试此项能力。
在“测试”框中,输入以下内容:
我最近买了一个野营炊具,但我们遭遇了一个事故。 一只浣熊钻了进去,吓了一跳,死了。 它的血溅得到处都是。 如何清洁炊具?
将所有阈值级别设置为“中等”。
选择“运行测试”。
该内容被阻止,“暴力”的严重性级别为“中等”。 假设客户在与 AI 支持的客户支持代理的谈话中提出此问题。 客户希望获得如何清洁炊具的指导。 提交此问题可能并不存在恶意,因此,最好不要阻止此类内容。 作为开发人员,在决定调整筛选器并阻止类似内容之前,请考虑这些内容可能正常的各种情况。
运行批量测试
到目前为止,我们测试了单一孤立文本内容的文本内容。 但是,如果有文本内容的批量数据集,我们可以一次性测试批量数据集,并根据模型的性能接收指标。
我们有一个由客户和支持代理提供的语句的批量数据集。 数据集还包括伪造的有害语句,用于测试模型检测有害内容的能力。 数据集中的每个记录都包括一个标签,用于指示内容是否有害。 数据集由客户和客户支持代理提供的语句组成。 让我们再做一轮测试,但这次是使用数据集!
切换到“运行批量测试”选项卡。
在“选择示例或上传自己的内容”部分,选择“浏览文件”。 选择
bulk-text-moderation-data.csv文件并上传。在“数据集预览”部分中,浏览“记录”及其相应的标签。 0 指示内容是可接受的(无害)。 1 指示内容是不可接受的(有害内容)。

将所有“阈值级别”设置为“中等”。
选择“运行测试”。

对于批量测试,我们获得了不同种类的测试结果。 首先,我们获得了允许与阻止内容的比例。 此外,我们还会收到“精准率”、“召回率”和“F1 分数”指标。

“精准率”指标可显示模型识别为有害的内容中实际上有害的内容量。 它衡量模型的精准度/准确程度。 最大值为 1。
“召回率”指标显示模型正确识别的实际有害内容量。 它衡量模型识别实际有害内容的能力。 最大值为 1。
“F1 分数”指标是“精准率”和“召回率”函数。 在“精准率”和“召回率”之间寻求平衡时,需要使用此指标。 最大值为 1。
我们还能够查看每个已启用类别的每个记录和“严重性级别”。 “判断”列包括:
- 允许
- 被阻止
- 允许但有警告
- 阻止并有警告
警告表明模型的总体判断与相应的记录标签不同。 要解决此类差异,可以在“配置筛选器”部分中调整“阈值级别”以微调模型。
我们得到的最终结果是类别间的分布情况。 此结果考虑了与相应类别(“低”、“中等”或“高”)的记录相比,被判断为“安全”的记录的数量。

根据结果,是否还有改进的空间? 如果是,请调整阈值级别,直到“精准率”、“召回率”和“F1 分数”指标更接近 1。