优化 Azure AI 搜索解决方案的性能
搜索解决方案性能可能会受到索引的大小和复杂性的影响。 你还需要了解如何编写有效的查询来搜索它并选择正确的服务层。
在这里,你将探索所有这些维度,并了解可以采取的用于提高搜索解决方案性能的步骤。
衡量当前的搜索性能
如果不知道搜索服务的性能如何,则无法进行优化。 创建基线性能基准,这样就可以验证所做的改进,但你也可以检查随时间推移性能的下降情况。
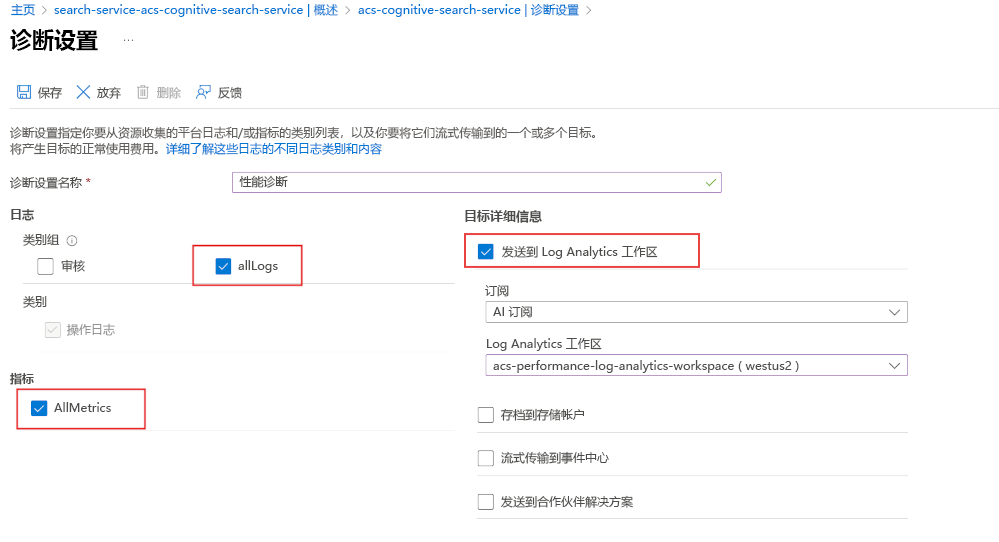
首先,使用 Log Analytics 启用诊断日志记录:
- 在 Azure 门户中,选择“诊断设置”。
- 选择“+ 添加诊断设置”。

- 为诊断设置指定名称。
- 选择 allLogs 和 AllMetrics。
- 选择“发送到 Log Analytics 工作区”
- 选择或创建 Log Analytics 工作区。
请务必在搜索服务级别捕获此诊断信息。 因为最终用户或应用可能会发现多个位置的性能问题。

如果可以证明搜索服务表现良好,那么如果存在性能问题,则可以将其从可能的因素中排除。
检查搜索服务是否存在限制
Azure AI 搜索的搜索和索引可能受到限制。 如果用户或应用设置了搜索限制,Log Analytics 捕获到这一信息时会显示 503 HTTP 响应。 如果索引存在限制,将显示 207 HTTP 响应。
可以针对搜索服务日志运行此查询,它可以显示搜索服务是否受到限制。

在 Azure 门户中的“监视”下,选择“日志”。 在“新建查询 1”选项卡中,你将使用此查询:
AzureDiagnostics
| where TimeGenerated > ago(7d)
| summarize count() by resultSignature_d
| render barchart
你将运行命令以查看搜索服务 HTTP 响应的条形图。 可以在上图中看到有多个 503 响应。
检查单个查询的性能
测试单个查询性能的最佳方法是使用 Postman 等客户端工具。 可以使用任意显示查询响应标头的工具。 Azure AI 搜索将始终返回一个“已用时间”值,该值指示服务完成查询所用的时间。

如果想知道发送和接收来自客户端的响应需要多长时间,可用总往返时间减去已用时间。 在上面的示例中,则为 125 毫秒 - 21 毫秒,即 104 毫秒。
优化索引大小和架构
搜索查询的执行方式与索引的大小和复杂性直接相关。 索引越小、优化程度越高,Azure AI 搜索就能越快地响应查询。 如果你发现个别查询存在性能问题,那么下面的一些提示可以提供帮助。
如果不留意,索引会随着时间的推移而增长。 应检查索引中的所有文档是否仍然相关,并且可进行搜索。
如果无法删除任何文档,是否可以降低架构的复杂性? 是否仍需要相同的字段才能进行搜索? 是否仍需要最初创建索引时使用的所有技能组?

请考虑查看每个字段上启用的所有属性。 例如,添加对筛选器、分面和排序的支持可以使索引所需的存储空间增加四倍。
注意
字段上的属性过多会限制其功能。 例如,在可分面、可筛选和可搜索的字段中,只能存储 16 KB。 而可搜索字段最多可容纳 16 MB 的文本。
如果索引已优化,但性能仍未达到所需水平,可以选择纵向扩展或横向扩展搜索服务。
提高查询的性能
如果你了解搜索服务的工作原理,则可以优化查询以显着提高性能。 使用此清单编写更好的查询:
- 使用 searchFields 参数指定需要搜索的字段。 因为更多字段需要额外的处理。
- 返回需要在搜索结果页面上呈现的最少字段数。 返回更多数据需要更多时间。
- 尽量避免部分搜索词,如前缀搜索或正则表达式。 这些类型的搜索计算成本更高。
- 避免使用高跳跃值。 这会强制搜索引擎对更大的数据量进行检索和排序。
- 将可分面字段和可筛选字段限制为低基数数据。
- 在筛选条件中使用搜索函数而不是单个值。 例如,可以使用
search.in(userid, '123,143,563,121',',')而不是$filter=userid eq 123 or userid eq 143 or userid eq 563 or userid eq 121。
如果已应用上述所有方法,但仍有个别查询不起作用,可以扩展索引。 根据用于创建搜索解决方案的服务层级,最多可以添加 12 个分区。 分区是索引所在的物理存储。 默认情况下,使用一个分区创建所有新搜索索引。 如果添加更多分区,索引会分散存储在这些分区中。 例如,如果索引有 200 GB,并且有四个分区,则每个分区包含 50 GB 的索引。
添加额外的分区有助于提高性能,因为搜索引擎可以在每个分区中并行运行。 对于返回大量文档的查询和使用分面提供大量文档计数的查询,可获得最佳改进。 这是确定评估文档相关性时的计算成本的一个因素。
使用最适合你搜索需求的服务层级
你已了解可以通过添加更多分区来横向扩展服务层级。 如果由于负载增加而需要扩展,可以使用副本进行横向扩展。 也可以使用更高的层级来“纵向扩展”搜索服务。

上述两个搜索索引的大小为 200 GB。 S1 层使用八个分区,而 S2 层只有两个。 它们都有两个副本,并且两个层级的成本大致相同。 为搜索解决方案选择最佳层需要知道所需的存储总量的大致大小。 目前支持的最大索引是 L2 层中的 12 个分区,总共提供 24 TB。
| 层 | 类型 | 存储 | 副本 | 分区 |
|---|---|---|---|---|
| F | 免费 | 50 MB | 1 | 1 |
| B | 基本 | 2 GB | 3 | 1 |
| S1 | 标准 | 25 GB/分区 | 12 | 12 |
| S2 | 标准 | 100 GB/分区 | 12 | 12 |
| S3 | 标准 | 200 GB/分区 | 12 | 12 |
| S3HD | 高密度 | 200 GB/分区 | 12 | 3 |
| L1 | 存储优化 | 1 TB/分区 | 12 | 12 |
| L2 | 存储优化 | 2 TB/分区 | 12 | 12 |
上述示例的两个层级,你认为哪个性能最好? 你已了解,由于并行性,横向扩展可以带来性能优势。 然而,更高的层级还提供高级存储、更强大的计算资源和额外的内存。 选择第二个选项可提供更强大的基础结构以及将来的索引增长。 遗憾的是,哪一层的性能最好取决于索引的大小和复杂性以及为搜索索引而编写的查询。 所以任何一个都有可能是最好的。
规划未来搜索解决方案使用上的增长意味着应考虑搜索单位。 搜索单位 (SU) 是副本和分区的乘积。 这意味着上述 S1 层使用 16 SU,而 S2 层仅使用 4 SU。 由于更高层级每个 SU 的费用更高,因此成本大致相同。
考虑由于负载增加而需要扩展搜索解决方案的情况。 向两个层级添加另一个副本会将 S1 层增加到 24 SU,但 S2 层仅上升到 6 SU。