介绍
机器学习正在通过支持数据驱动型决策和自动化来改变企业运作方式。 但是,开发机器学习模型只是一个开始。 真正的挑战在于将这些模型部署到生产环境中,让它们可以提供实时见解和预测。
Azure Databricks 是一个集数据工程和数据科学于一体的多功能平台。 它提供了一个统一的分析平台,用于简化大规模生成、训练和部署机器学习模型的过程。 借助其协作环境,数据科学家和工程师可以协同工作,创建有效的机器学习解决方案。
若要充分利用 Azure Databricks 的功能,必须了解完整的机器学习工作流。
探索机器学习工作流
机器学习工作流是一个包含多个关键任务的综合过程,每项任务都在开发和部署有效的机器学习模型方面发挥着重要作用。 机器学习工作流包括以下任务:
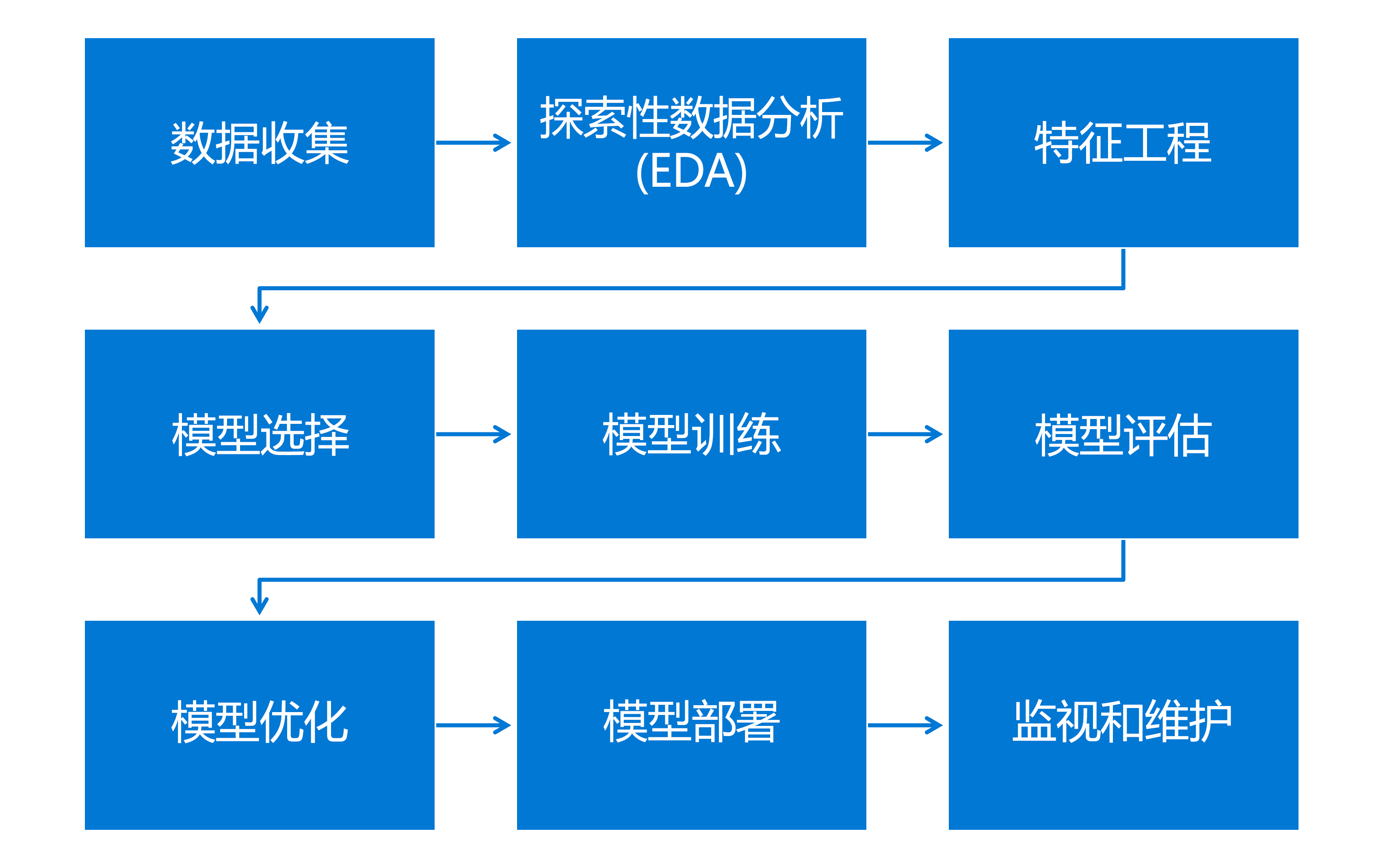
- 数据收集:数据可以是数字、图像和文本等任何形式,具体取决于计算机需要学习的内容。
- EDA(探索性数据分析):分析数据以汇总其主要特征并发现其中的模式。
- 特征工程:创建新特征或修改现有特征以提高模型性能。
- 模型选择:模型是一种数学公式或算法,通过发现数据中的模式进行预测。
- 模型训练:机器学习算法利用数据来学习将输入(特征)连接到输出(目标)的模式。 模型将通过调整其参数最大程度地减少其预测结果与训练数据中实际结果之间的差异。
- 模型评估:使用名为“测试集”的新数据集评估模型的性能。 准确度、精准率、召回率和 ROC 曲线下的面积等指标用于评估不同类型的模型。
- 模型优化:对模型的参数和算法进行微调,旨在提高其准确度和效率。
- 模型部署:将模型部署到生产环境中,在其中进行批处理或实时预测。
- 监视和维护:持续监视对于确保模型在基础数据分布中出现新数据和潜在变化时仍能保持有效性至关重要。
为了完成机器学习工作流的每个阶段并将模型引入生产环境,请务必使用正确的工具和技术。 Azure Databricks 和其他 Azure 服务提供了一组工具,用于支持此过程的每个步骤。 从数据收集和特征工程到模型部署和监视,Azure 提供了可实现顺畅集成和高效工作流的工具。
让我们来了解一下这些有助于将机器学习工作流引入生产环境的工具。