混淆矩阵
数据可以是连续数据、分类数据或有序数据(有序分类)。 混淆矩阵是评估分类模型执行情况的一种方法。 若要了解混淆矩阵的工作原理,首先应熟悉有关连续数据的知识。 熟悉之后,我们就会发现,混淆矩阵为何就只是我们已知的直方图的延伸。
连续数据分布
想要了解连续数据,第一步通常是了解它的分布方式。 请考虑以下直方图:
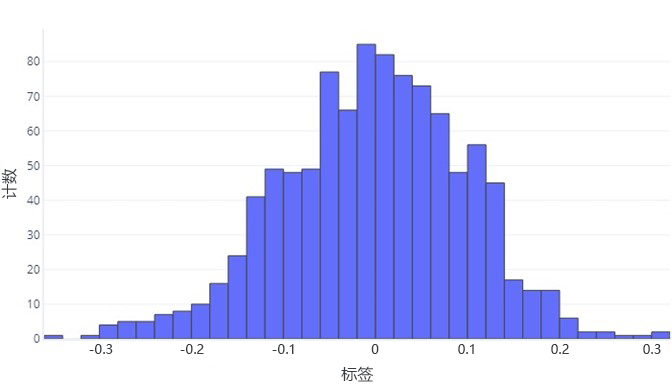
我们可以看到,标签的平均值在 0 上下,大多数数据点都介于 -1 和 1 之间。 数据颇为对称;平均值之下和之上的数量大约相等。 如果需要,我们可以使用表格,而不是直方图,但表格不好处理。
分类数据分布
在某些方面,分类数据与连续数据并无太大区别。 我们仍可以生成直方图来评估每个标签的常见值的显示方式。 例如,二进制标签(true/false)可能会按照以下频率显示:
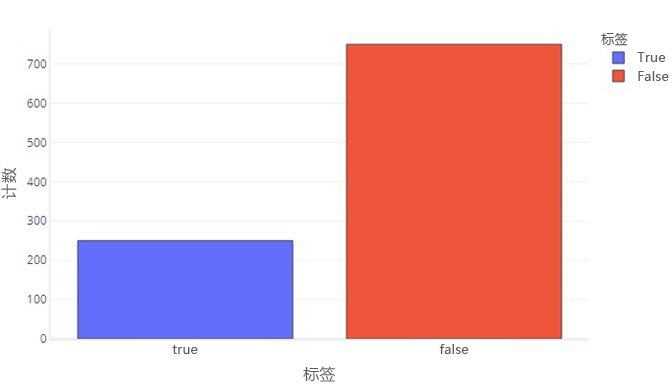
从图中可知,“false”标签有 750 个样本,而“true”标签有 250 个样本。
三个类别的标签类与此类似:
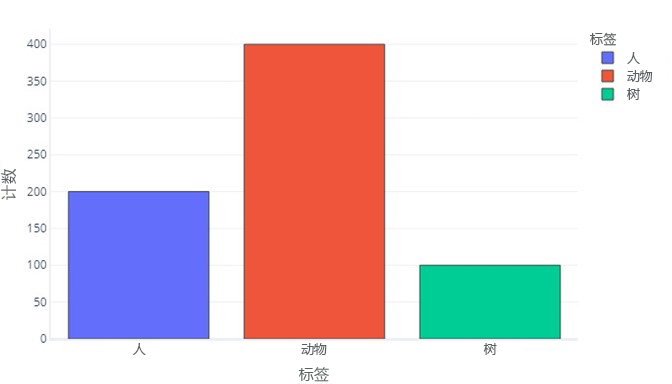
从图中可知,“人物”标签有 200 个样本,“动物”标签有 400 个样本,“树”标签有 100 个样本。
由于分类标签很简单,因此通常可以将它们显示为简单表。 前面的两个图将如下所示:
| Label | False | True |
|---|---|---|
| 计数 | 750 | 250 |
以及:
| Label | 人员 | 动物 | 树 |
|---|---|---|---|
| 计数 | 200 | 400 | 100 |
观察预测
我们可以观察模型做出的预测,就像我们观察数据中的真值标签一样。 例如,我们可能会看到,在测试集中,我们的模型预测为“false”有 700 次,为“true”有 300 次。
| 模型预测 | 计数 |
|---|---|
| False | 700 |
| True | 300 |
这为我们的模型所做的预测提供了直接信息,但它不能告诉我们哪些预测是正确的。 虽然可以使用代价函数来理解给出正确响应的频率,但代价函数不会告诉我们发生了哪些错误。 例如,模型可能会正确地猜出所有“true”值,但也可能会在本应猜测“false”时却猜测“true”。
混淆矩阵
了解模型性能的关键是将模型预测表与真值数据标签表相结合:
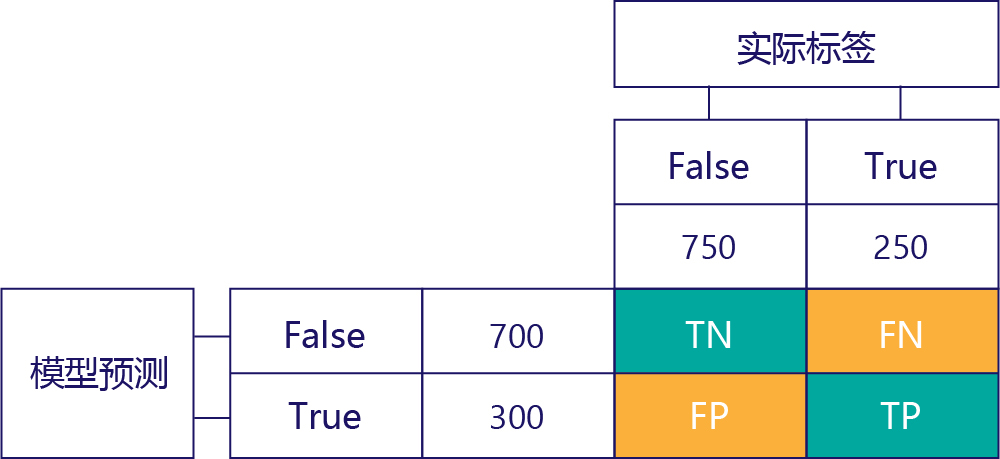
我们没有填充的方块称为混淆矩阵。
混淆矩阵中的每个单元格都会告诉我们一件有关模型表现的事情。 这些是真正 (TN),假正 (FN),假负 (FP) 和真负 (TP)。
让我们用实际的值来替换这些缩写词,逐一进行解释。 蓝绿色的方块表示模型的预测是正确的,橘色的方块表示模型的预测是错误的。
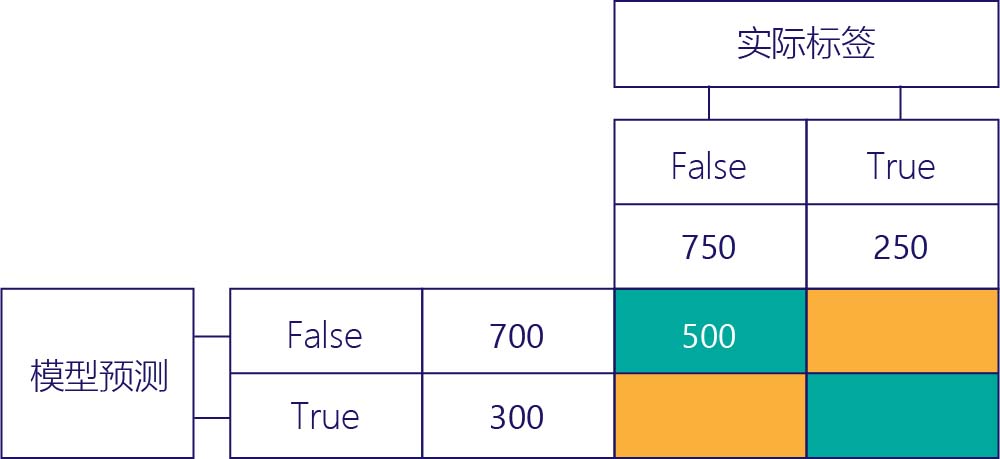
真负 (TN)
左上角的值将列出模型预测为“false”并且实际标签也为“false”的次数。 换句话说,它列出了模型正确预测“false”的次数。 举个例子,假设这种情况发生了 500 次:
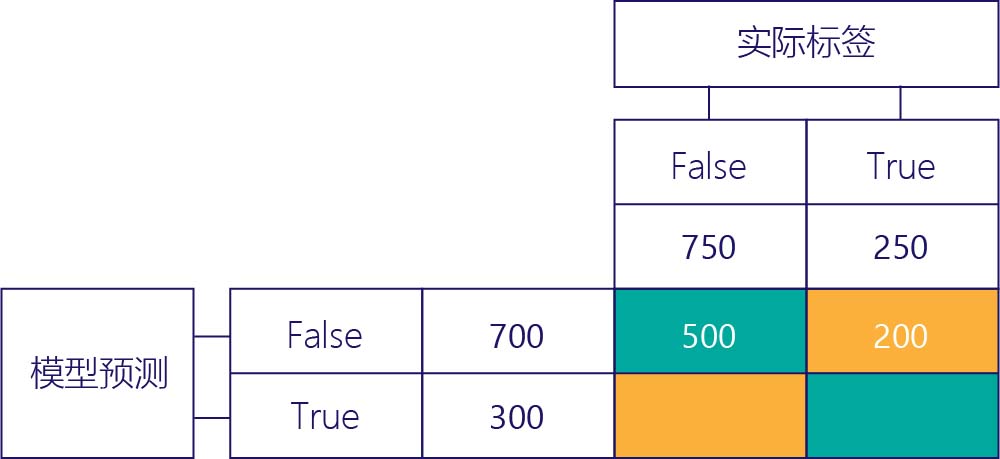
假负 (FN)
右上角的值将指示模型预测为“false”但实际标签为“true”的次数。 现在我们知道此值为 200。 如何操作? 因为这个模型预测了 700 次“false”,其中有 500 次是正确的。 因此,该模型一定预测了 200 次“false”,但它不该预测这么多次。
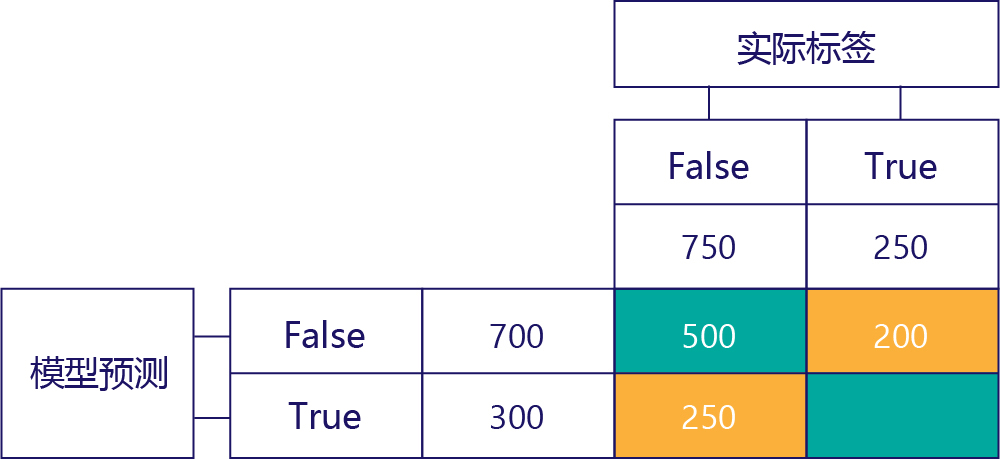
假正 (FP)
左下角的值包含假正。 它指示模型预测为“true”的次数,但实际标签为“false”。 现在我们知道此值为 250,因为有 750 次正确答案是“false”。 其中有 500 次出现在左上角单元格 (TN):
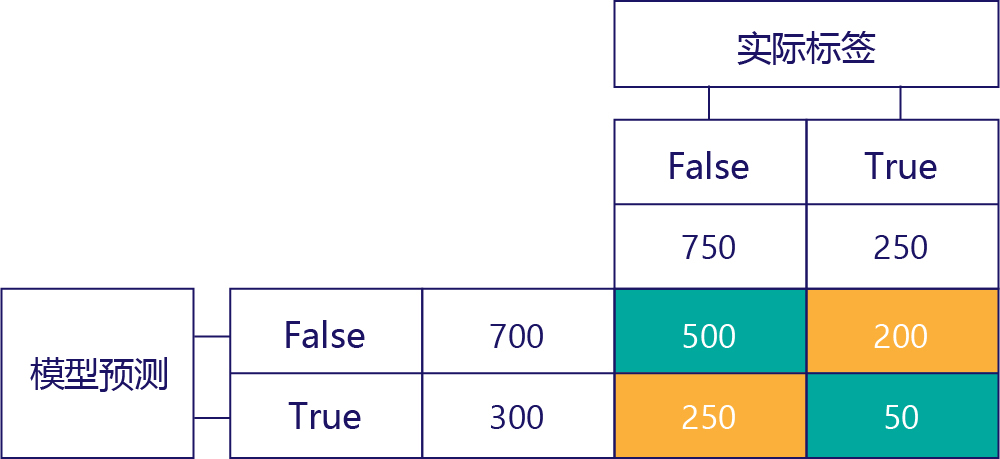
真正 (TP)
最后,我们得到真正。 这是模型正确预测为“true”的次数。 现在我们知道该值为 50,原因有两个。 首先,模型预测为“true”有 300 次,但有 250 次是错误的(左下角单元格)。 其次,有 250 次为“true”的正确答案,但模型预测为“false”有 200 次。
最终矩阵
我们通常会稍微简化混淆矩阵,就像下面这样:
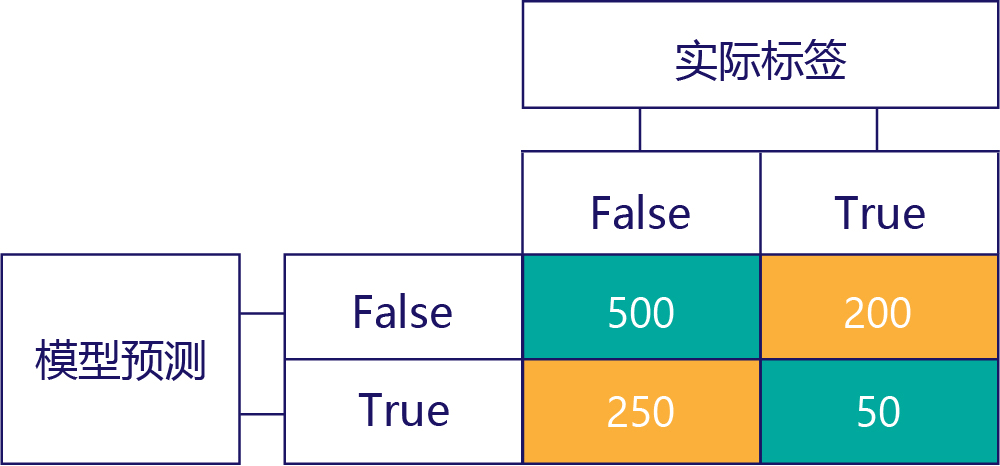
我们在这里给单元格上色,以突出显示模型做出正确预测的时间。 由此,我们不仅知道模型做出某些类型预测的频率,还知道这些预测正确或错误的频率。
如果有更多标签,也可以构造混淆矩阵。 例如,在我们的人物/动物/树示例中,我们可能会得到这样一个矩阵:
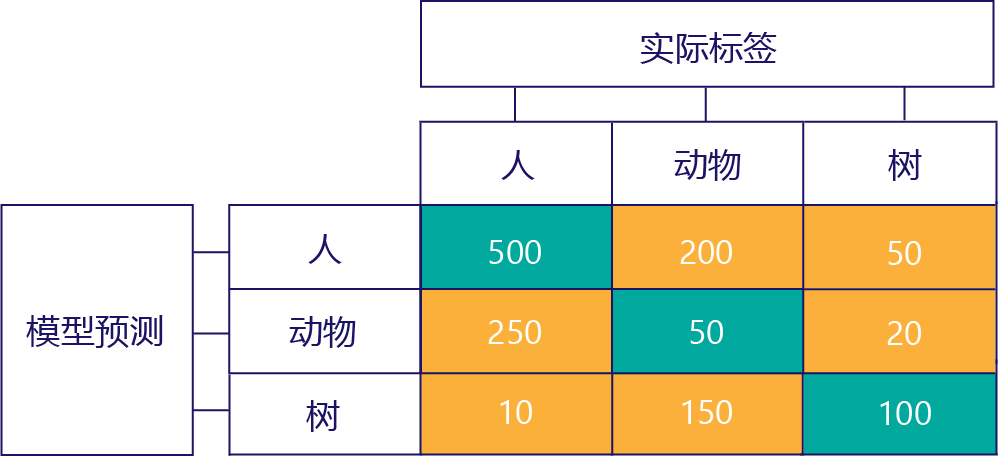
当存在三种类别时,“真正”这样的指标将不再适用,但我们仍然可以看到模型发生某些类型错误的确切频率。 例如,我们可以看到,当实际正确的结果为“动物”时,模型预测为“人物”有 200 次。