决策树和模型体系结构
当我们谈到体系结构时,我们经常会想到建筑物。 体系结构负责建筑物的结构、高度、深度、楼层数以及内部连接方式。 这种体系结构也决定了我们如何使用一个建筑物:具体而言,就是从哪里进入,“从中可以得到什么”。
在机器学习中,体系结构具有类似的概念。 它有多少参数,这些参数如何链接起来以实现计算? 我们是执行大量并行计算(宽度)还是依赖于之前的计算(深度)的串行操作? 如何为这个模型提供输入,以及如何接收输出? 这样的体系结构决策通常只适用于更复杂的模型,体系结构决策可以涵盖从简单到复杂的情况。 通常在训练模型之前做出这些决策,但在某些情况下,在训练后还有更改的空间。
让我们以决策树为例,更具体地探讨这一点。
什么是决策树?
决策树实际上是一个流程图。 决策树是一种将决策划分为多个步骤的分类模型。
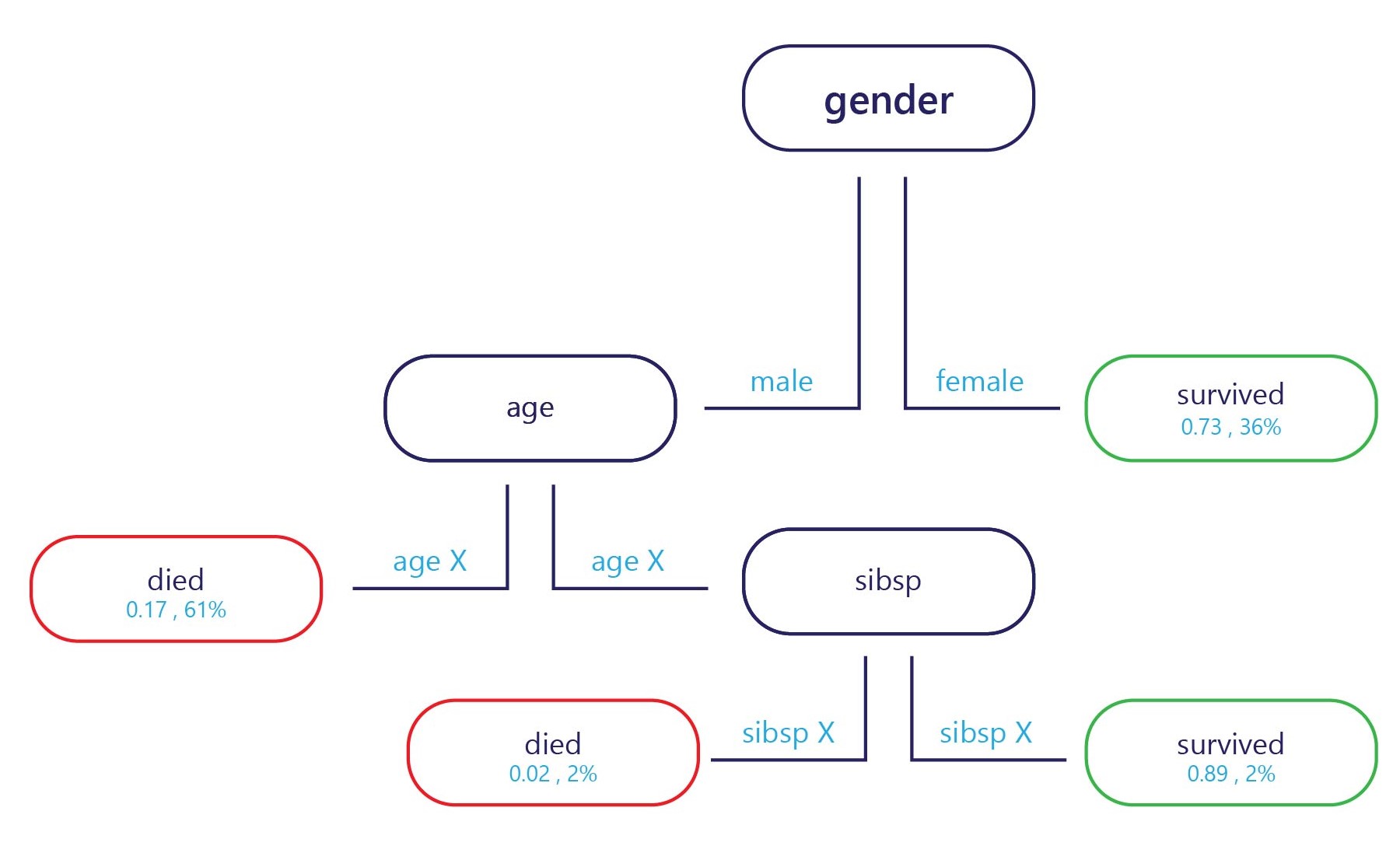
该示例在入口点(上图中的顶部)和每个出口点都有一个标签(上图中的底部)。 在每个节点上,一个简单的“if”语句将决定样本接下来要传递到的分支。 一旦分支到达树的末端(叶子),它就会被分配给一个标签。
如何训练决策树?
决策树一次训练一个节点或决策点。 在第一个节点上评估整个训练集。 从这里选择一个特征,它可以采用最佳方式将集合分成两个具有更多同质标签的子集。 例如,假设训练集如下所示:
| 体重(特征) | 年龄(特征) | 赢得奖牌(标签) |
|---|---|---|
| 90 | 18 | 否 |
| 80 | 20 | 否 |
| 70 | 19 | 否 |
| 70 | 25 | 否 |
| 60 | 18 | 是 |
| 80 | 28 | 是 |
| 85 | 26 | 是 |
| 90 | 25 | 是 |
如果我们想找到一条简单的规则来拆分这个些数据,我们可能会按年龄(大约 24 岁左右)进行拆分,因为大多数奖牌得主都超过了 24 岁。 这种分割方法会提供两个数据子集。
子集 1
| 体重(特征) | 年龄(特征) | 赢得奖牌(标签) |
|---|---|---|
| 90 | 18 | 否 |
| 80 | 20 | 否 |
| 70 | 19 | 否 |
| 60 | 18 | 是 |
子集 2
| 体重(特征) | 年龄(特征) | 赢得奖牌(标签) |
|---|---|---|
| 70 | 25 | 否 |
| 80 | 28 | 是 |
| 85 | 26 | 是 |
| 90 | 25 | 是 |
如果就此打住,我们将得到一个简单的模型,包含一个节点和两片叶子。 叶子 1 包含未赢得奖牌的人,并且在我们的训练集上准确率为 75%。 叶子 2 包含奖牌获得者,并且在我们的训练集上准确率也为 75%。
不过,我们不需要在此处停住。 我们可以通过进一步拆分树叶来继续此过程。
在子集 1 中,第一个新节点可以按体重进行拆分,因为唯一的奖牌获得者的体重小于未获得奖牌的人。 可以将规则设置为“体重 < 65”。 预测体重 < 65 的人员将获得奖牌,而所有体重 ≥65 的人都不符合这一标准,预测其可能不会获得奖牌。
在子集 2 中,第二个新节点也可以按体重拆分,但这一次预测体重超过 70 的人将获得奖牌,而体重小于 70 的人将不会获得奖牌。
这将为我们提供一个在训练集上可以达到100% 准确率的树。
决策树的优点和缺点
决策树的偏差较小。 这意味着他们通常擅长识别重要的特征,以便正确标记一些内容。
决策树的主要缺点是过度拟合。 考虑前面给出的示例:该模型提供了一种精确的方法来计算谁有可能赢得奖牌,这将正确预测 100% 的训练数据集。 这种精度水平对于机器学习模型来说是很少见的,因为机器学习模型通常会在训练数据集上产生大量错误。 良好的训练性能本身并不是一件坏事,但是树对于训练集已经变得高度专门化,以至于它可能在测试集上表现不佳。 这是因为树已经成功地学会了训练集中的关系,这些关系可能并不真实,例如,如果你年龄在 25 岁以下,体重 60 公斤就能保证获得奖牌。
模型体系结构会影响过度拟合
如何构建决策树是避免其弱点的关键。 树越深,过度拟合训练集的可能性就越大。 例如,在上面的简单树中,如果我们将树限制为仅第一个节点,那么它在训练集中可能会出错,但在测试集中可能会表现得更好。 这是因为,对于谁获得奖牌,会有更普遍的规则(例如“24 岁以上的运动员”),而不是可能只适用于训练集的非常具体的规则。
虽然我们在这里重点介绍的是树,但其他复杂模型通常也有类似的弱点,可通过决定其结构或允许的训练操作方式来弱化这些弱点。