介绍
SQL 语言
SQL 是结构化查询语言的首字母缩写。 SQL 用来与关系数据库进行通信。 SQL 语句用于执行任务,如更新数据库中的数据,或从数据库中检索数据。 例如,SQL SELECT 语句用于查询数据库并返回一组数据行。 一些常见的使用 SQL 的关系数据库管理系统包括 Microsoft SQL Server、MySQL、PostgreSQL、MariaDB 和 Oracle。
美国国家标准协会 (ANSI) 为 SQL 语言定义了一种标准。 每个供应商都要添加自己的变体和扩展。
通过学习本模块,你将了解如何:
- 了解什么是 SQL 及其使用方式
- 识别架构中的数据库对象
- 识别 SQL 语句类型
- 使用 SELECT 语句在数据库中查询表
- 使用数据类型
- 处理 NULL
Transact-SQL
无论使用何种关系数据库系统,都可以使用基本 SQL 语句,例如 SELECT、INSERT、UPDATE 和 DELETE。 虽然这些 SQL 语句都是 ANSI SQL 标准的一部分,但许多数据库管理系统也有自己的扩展。 这些扩展提供了 SQL 标准未包含的功能,包括安全管理和可编程性等领域。 Microsoft 数据库系统(如 SQL Server、Azure SQL 数据库、Microsoft Fabric 等)使用一种称作 Transact-SQL 或 T-SQL 的 SQL 方言。 T-SQL 包含用于写入存储过程和函数(存储在数据库中的应用程序代码)以及管理用户帐户的语言扩展。
SQL 是一种声明性语言
编程语言可分为过程或声明性类别。 使用过程语言可以定义计算机执行任务所遵循的指令序列。 使用声明性语言可以说明所需的输出,并可保留为执行引擎生成输出所需步骤的详细信息。
SQL 支持某些过程语法,但通过 SQL 查询数据通常遵循声明性语义。 可以使用 SQL 来说明想要的结果,而数据库引擎的查询处理器将制定一个查询计划来进行检索。 查询处理器使用有关数据库中数据的统计信息和表中定义的索引来提供良好的查询计划。
关系数据
SQL 最常(但并不总是)用来查询关系数据库中的数据。 关系数据库是一种已将数据组织到多个表中(技术上称为“关系”)的数据库,其中每个表代表一种特定类型的实体(例如客户、产品或销售订单)。 这些实体的属性(例如客户名称、产品价格或销售订单的订单日期)被定义为表的列或属性,而表中的每一行代表一个实体类型实例(例如特定客户、产品或销售订单)。
数据库中的表通过键列相互关联,键列唯一标识所代表的特定实体。 为每个表定义一个主键,并将任意相关表中对此键的引用定义为外键。 通过示例可以更轻松地了解这些信息:
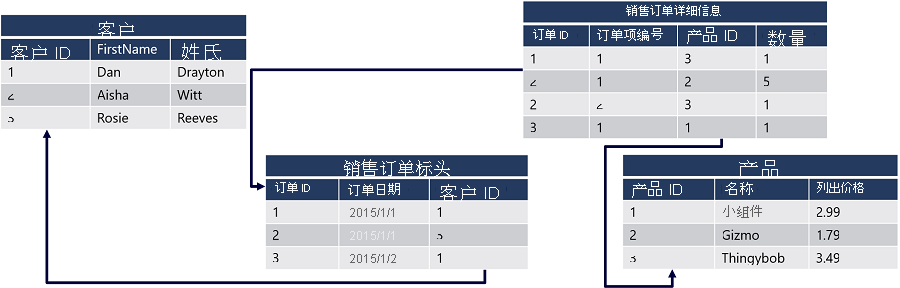
该图显示了一个包含四个表的关系数据库:
- 客户
- SalesOrderHeader
- SalesOrderDetail
- 产品
每个客户由唯一的 CustomerID 字段标识 - 此字段是“客户”表的主键。 SalesOrderHeader 表中包含标识每个订单的主键,名为 OrderID,还包括引用“客户”表中主键的外键 CustomerID,它用于标识哪个客户与哪个订单相关联。 订单中各项的数据存储在 SalesOrderDetail 表中,它的主键是复合主键,即将 SalesOrderHeader 表中的 OrderID 与 LineItemNo 值结合在了一起。 这些值的组合用于唯一标识行项。 此外,“OrderID”字段用作外键来指示行项所属的订单,“ProductID”字段用作“产品”表中的 ProductID 主键的外键,指示订购的哪款产品。
基于集的处理
集理论是数据管理关系模型的数学基础之一,也是使用关系数据库的基础。 虽然你可能能够在未全面了解集的情况下以 T-SQL 写入查询,但对于优化性能可能需要的一些更复杂的语句类型,最终可能难以写入。
如果未深入学习集理论的数学原理,可以将集视为“作为整体考虑的非重复确切对象的集合”。在应用到 SQL Server 数据库方面,可以将集视为包含零个或多个相同类型成员的非重复对象的集合。 例如,“客户”表代表一个集:具体而言,就是所有客户的集。 你可以看到,SELECT 语句的结果也会形成一个集。
随着对 T-SQL 查询语句的了解加深,必须始终考虑整个集,而不是单个成员,这一点非常重要。 这种思维方式让你能够更好地写入基于集的代码,而不是一次思考一行。 使用集时,需要从“一次运行全部”操作方面考虑,而不是每次一个。
关于集理论需要注意的一项重要特征是,对于集中成员的顺序没有特别规定。 这种无序做法适用于关系数据库表。 没有第一行/第二行或最后一行的概念。 可以按任何顺序访问(和检索)元素。 如果需要以特定顺序返回结果,则必须在 SELECT 查询中使用 ORDER BY 子句显式指定。