独热向量
到目前为止,我们已经介绍了连续数据编码(浮点数)、有序数据编码(通常是整数)和二进制分类数据编码(如幸存/死亡、男性/女性等)。
现在,我们将了解如何对数据进行编码,并探索具有两个以上类的分类数据资源。 我们还将探讨模型改进决策对模型性能的潜在有害影响。
分类数据不是数字数据
分类数据处理数字的方式与其他数据类型处理数字的方式不同。 对于有序或连续(数字)数据,数值越高表示数量越多。 例如,泰坦尼克号的票价是 30 英镑,比 12 英镑的票价要贵。
相比之下,分类数据没有逻辑顺序。 如果我们尝试将具有两个以上类的分类特征编码为数字,会遇到问题。
例如,登船港口有三个值:C(瑟堡)、Q(皇后镇)和 S(南安普敦)。 不能将这些符号替换为数字。 这样做意味着其中一个港口“小于”其他港口,而另一个港口“大于”其他港口。 这种替换没有意义。
作为这个问题的一个例子,让我们将谨慎抛之脑后,构建启航港和票务等级之间的关系,将启航港视为一个数字。 首先,我们假设 C < S < Q:
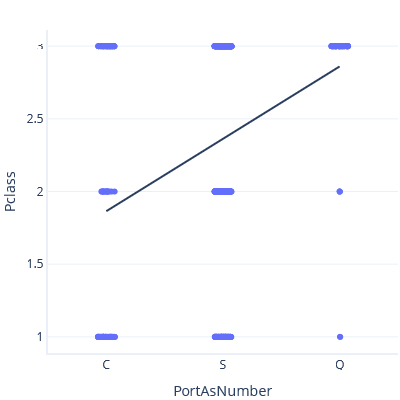
在此图中,这条线预测港口 Q 大概是 3 等票。
现在,如果假设 S < C < Q,我们将获得不同的趋势线和预测:

这两条趋势线都不正确。 将类别视为连续特征是没有意义的。 那么,我们该如何处理类别呢?
独热编码
独热编码可以采用避免此问题的方式对分类数据进行编码。 每个可用类别都有自己的一列,而给定行仅包含其所属的类别中的一个 1 值。
例如,我们可以将港口值编码为三列,一列用于瑟堡,一列用于皇后镇,一列用于南安普敦(确切的顺序与此无关)。 在瑟堡登船的人会在 Port_Cherbourg 列中有一个 1,如下所示:
| Port_Cherbourg | Port_Queenstown | Port_Southampton |
|---|---|---|
| 1 | 0 | 0 |
在皇后镇登船的人在第二列中有一个 1:
| Port_Cherbourg | Port_Queenstown | Port_Southampton |
|---|---|---|
| 0 | 1 | 0 |
在南安普敦登船的人在第三列中有一个 1
| Port_Cherbourg | Port_Queenstown | Port_Southampton |
|---|---|---|
| 0 | 0 | 1 |
独热编码、数据清理和统计功效
在使用独热编码之前,应了解使用该编码可能会对模型的实际性能产生正面或负面影响。
什么是统计功效?
统计功效是指模型可靠地识别特征和标签之间真实关系的能力。 例如,功能强大的模型可以高度确定地报告票价和幸存率之间的关系。 相比之下,统计功效较低的模型可能会以较低的确定性报告此关系,甚至可能根本找不到这种关系。
我们在这里避开数学运算,但请记住,我们所做的选择会影响模型的功能。
删除数据会降低统计功效
我们多次提到,数据清理(部分)涉及删除不完整的数据样本。 遗憾的是,数据清理会降低统计功效。 例如,假设我们希望根据以下数据预测泰坦尼克号航行的幸存率:
| 票价 | 幸存人数 |
|---|---|
| 4 英镑 | 0 |
| 8 英镑 | 0 |
| 10 英镑 | 1 |
| 25 英镑 | 1 |
我们可以猜测,持有价值 15 英镑船票的人会幸存,因为持有至少 10 英镑船票的人都幸存下来了。 不过,如果我们的数据量较少,这种猜测将变得更加困难:
| 票价 | 幸存人数 |
|---|---|
| 4 英镑 | 0 |
| 8 英镑 | 0 |
| 25 英镑 | 1 |
无价值的列会降低统计功效
价值不大的特征也会损害统计功效,尤其是当特征数(或列)开始接近样本数(或行)时。
例如,假设我们希望能够根据以下数据预测幸存率:
| 票价 | 幸存人数 |
|---|---|
| 4 英镑 | 0 |
| 4 英镑 | 0 |
| 25 英镑 | 1 |
| 25 英镑 | 1 |
我们可以自信地预测,买 A 舱船票的人会幸存下来,因为买 25 英镑船票的人都幸存下来了。
但是,现在还有另一个特征(船舱):
| 票价 | Cabin | 幸存人数 |
|---|---|---|
| 4 英镑 | A | 0 |
| 4 英镑 | A | 0 |
| 25 英镑 | B | 1 |
| 25 英镑 | B | 1 |
船舱不能提供有用的信息,因为它只是对应于票价。 目前还不清楚是否有持有 25 英镑的 A 舱船票的人会幸存下来。 他们是会像 A 舱的其他人一样灭亡,还是像那些持有 25 英镑船票的人一样幸存下来?
独热编码会降低统计功效
独热编码比连续数据或有序数据更能降低统计功效,因为它需要多个列,每个可能的分类值都对应一个列。 例如,如果我们对登船港口进行独热编码,我们会添加三个模型输入(C、S 和 Q)。
如果类别的数量远远低于样本的数量(数据集行),则分类变量会很有用。 如果分类变量通过其他输入向模型提供尚不可用的信息,则分类变量也很有用。
例如,我们发现,在不同港口登船的人幸存的可能性不同。 此差异可能反映了在皇后镇港口登船的大多数人都持有三等票这一事实。 因此,在没有为模型添加相关信息的情况下,登船可能会在一定程度上降低统计功效。
相比之下,船舱很可能对生存有着重大影响。 这是因为,在轮船中靠近上层甲板的舱室进水之前,船的下层舱室就已经进水了。 也就是说,泰坦尼克号数据集包含 147 个不同的船舱。 如果将它们包含在内,这会降低模型的统计功效。 可能需要尝试在模型中包括或排除船舱数据,看看船舱数据能否为我们提供帮助。
在下一个练习中,我们最终将生成模型来预测泰坦尼克号航行幸存率,并在此过程中练习独热编码。