定义监督式学习
训练模型的过程可以是监督式过程,也可以是非监督式过程。 我们的目标是对比这些方法,然后深入了解学习过程,其中我们将重点讲解监督式学习。 在整个讨论中都需要记住,监督式学习和非监督式学习之间的唯一区别在于目标函数的工作方式。
什么是非监督式学习?
在非监督式学习中,我们训练模型来解决我们并不知道正确答案的问题。 事实上,非监督式学习通常用于那种没有正确答案而只论解决方案好坏的问题。
假设我们想让机器学习模型画出逼真的雪崩救援犬图片。 无法画出一张“正确”的图。 只要图像看起来有点像狗,我们就会感到满意。 但如果生成的图像是一只猫,则这是一个更糟糕的解决方案。
请记住,训练需要几个组成部分:
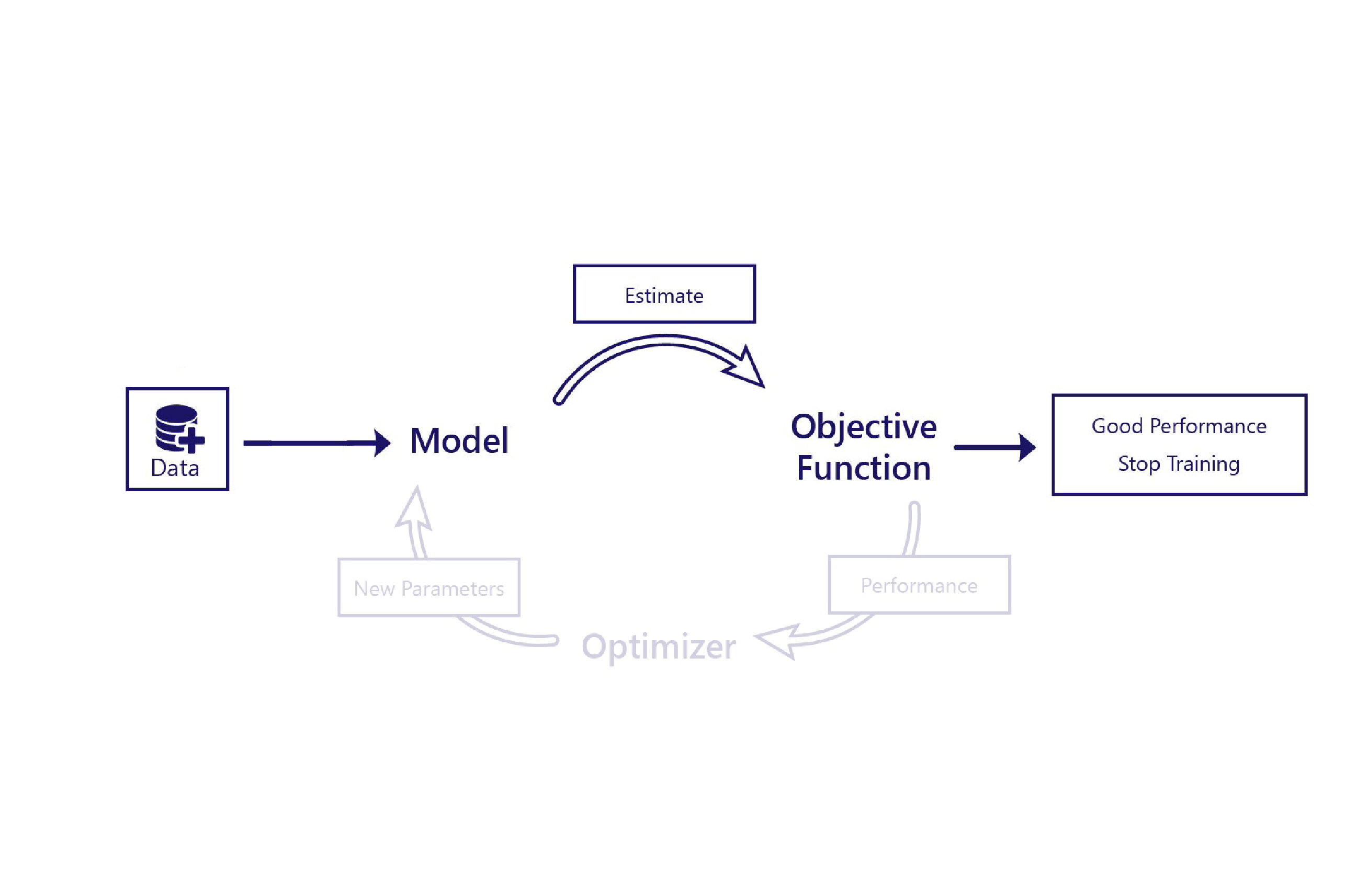
在非监督式学习中,目标函数仅根据模型的估计值做出判断。 这意味着目标函数通常相对复杂。 例如,目标函数可能需要包含“小狗检测程序”,用于评估模型绘制的图像看起来是否逼真。 对于非监督式学习,唯一所需的数据是特征:即我们提供给模型的数据。
什么是监督式学习?
将监督式学习视为通过实例学习。 在监督式学习中,通过将模型的估计值与正确答案进行比较来评估模型的性能。 虽然我们的目标函数可以非常简单,但我们同时需要:
- 特征,作为输入提供给模型
- 标签,即希望模型能够生成的正确答案
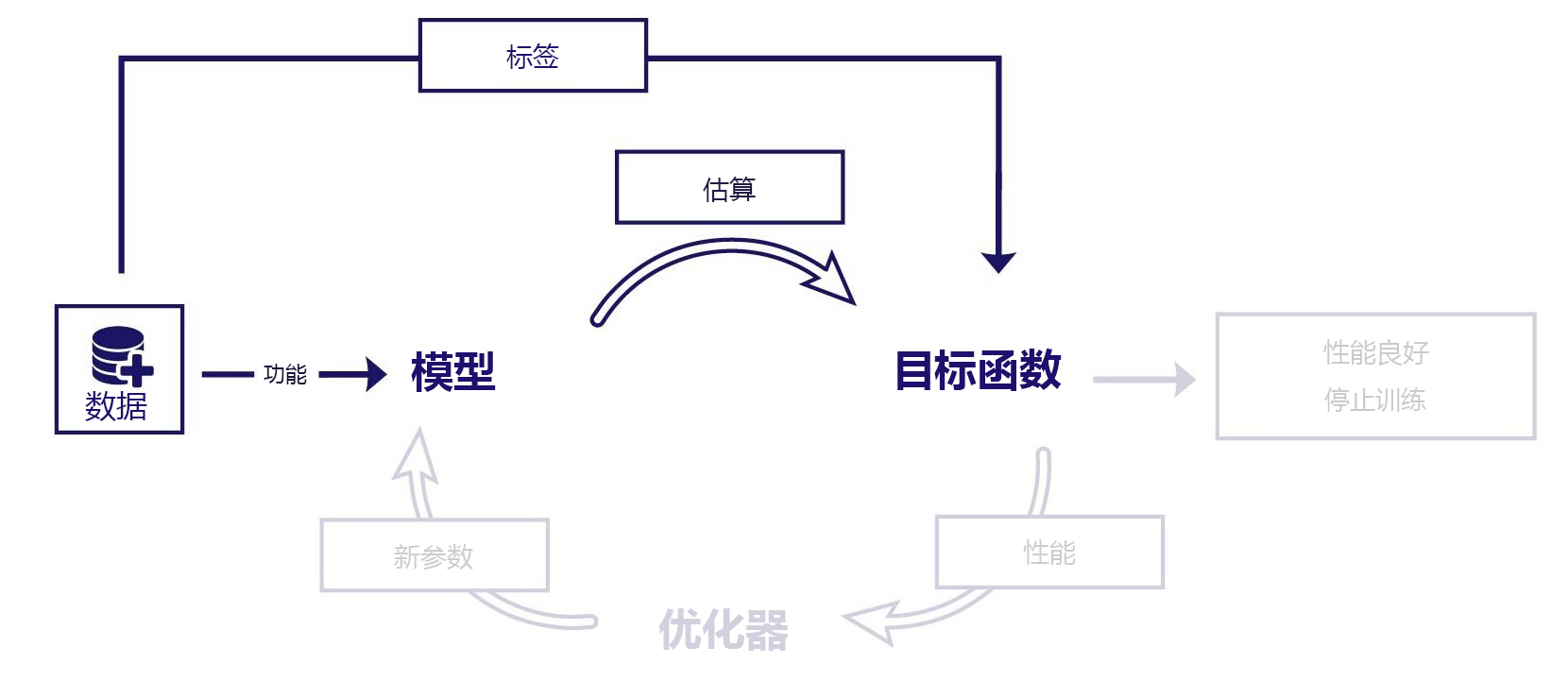
例如,假设我们想要预测某一年 1 月 31 日的温度。 对于这项预测,我们需要的数据包含两个部分:
- 特征:日期
- 标签:日温度(例如,来自历史记录)
在该场景中,我们会为模型提供日期特征。 该模型会预测温度,并且我们会将此结果与数据集的“正确”温度进行比较。 然后,目标函数可以计算模型的表现,并且我们可以对该模型进行调整。
标签仅用于学习
请务必记住,无论模型是如何训练的,它们只处理特征。 在监督式学习期间,目标函数是唯一依赖于对标签的访问的组件。 训练后,无需标签即可使用模型。