在数据分析工作负载中使用 Azure Data Lake Storage Gen2
Azure Data Lake Storage Gen2 是一种支持多个数据分析用例的技术。 我们来探讨一些常见类型的分析工作负载,并确定 Azure Data Lake Storage Gen2 如何与其他 Azure 服务配合使用来支持它们。
大数据处理和分析
大数据方案通常是指涉及需要快速(即所谓的“三 v”)处理的各种格式的大量数据的分析工作负载。 Azure Data Lake Storage Gen2 提供可缩放且安全的分布式数据存储,其中 Azure Synapse Analytics、Azure Databricks 和 Azure HDInsight 等大数据服务可以应用 Apache Spark、Hive 和 Hadoop 等数据处理框架。 存储和处理计算的分布式特性使任务可以并行执行,即使在处理大量数据时也能实现高性能和可伸缩性。
数据仓库
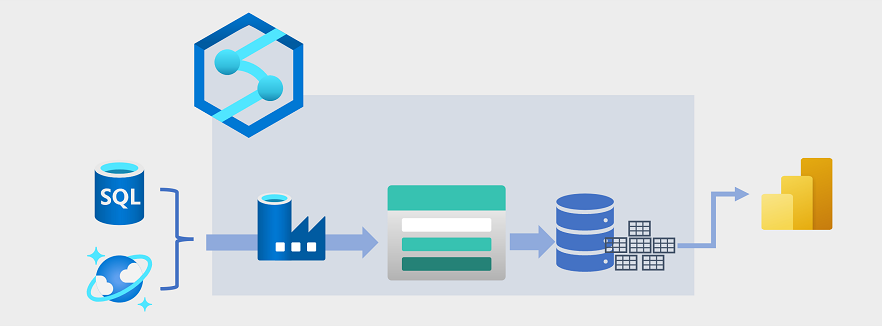
近年来,数据仓库不断发展,将作为文件存储在数据湖中的大量数据与数据仓库中的关系表集成。 在数据仓库解决方案的典型示例中,从操作数据存储(如 Azure SQL 数据库或 Azure Cosmos DB)中提取数据,并将数据转换为更适合分析工作负载的结构。 通常,数据会在加载到关系数据仓库之前暂存到数据湖中,这样有利于分布式处理。 在某些情况下,数据仓库使用外部表在数据湖中的文件上定义关系元数据层,并创建混合“数据仓库”或“湖数据库”体系结构。 然后,数据仓库可以支持用于报告和可视化效果的分析查询。
可通过多种方式实现这种类型的数据仓库体系结构。 此示意图显示了一个解决方案,其中 Azure Synapse Analytics 托管管道,并使用 Azure 数据工厂技术执行提取、转换和加载 (ETL) 进程。 这些进程从操作数据源中提取数据,并将数据加载到在 Azure Data Lake Storage Gen2 容器中托管的数据湖中。 然后,数据经过处理并加载到 Azure Synapse Analytics 专用 SQL 池中的关系数据仓库,在那里,数据可以支持使用 Microsoft Power BI 的数据可视化和报告。
实时数据分析
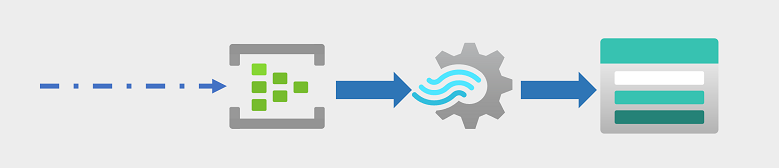
企业和其他组织越来越需要捕获和分析永久性数据流,并实时(或尽可能准实时)地对其进行分析。 这些数据流可以从连接的设备(通常称为物联网 (IoT) 设备)生成,也可以通过社交媒体平台或其他应用程序中的用户生成的数据来生成。 与传统的批处理工作负载不同,流数据需要一个解决方案,能够在发生无限数据流事件时进行捕获和处理。
流事件通常在队列中捕获以进行处理。 可以使用多种技术来执行此任务,包括 Azure 事件中心,如图中所示。 从这里开始对数据进行处理,通常是在临时窗口上聚合数据(例如,每五分钟计算一次带有给定标记的社交媒体消息数,或计算每分钟连接 Internet 的传感器的平均读数)。 使用 Azure 流分析,可以创建作业,在事件数据到达时对其进行查询和聚合,并将结果写入输出接收器。 Azure Data Lake Storage Gen2 就是这样一个接收器;从那里可以分析和可视化已捕获的实时数据。
数据科学和机器学习

数据科学涉及对大量数据的统计分析,通常使用 Apache Spark 等工具和 Python 之类的脚本语言。 Azure Data Lake Storage Gen2 为数据科学工作负载所需的数据量提供了高度可缩放的基于云的数据存储。
机器学习是处理训练预测模型的数据科学的一个子领域。 模型训练需要大量数据,以及有效处理这些数据的功能。 Azure 机器学习是一项云服务,借助此服务,数据科学家可以使用动态分配的分布式计算资源在笔记本中运行 Python 代码。 计算处理 Azure Data Lake Storage Gen2 容器中的数据以训练模型,然后可将模型部署为生产 Web 服务,支持预测分析工作负载。