了解 LLM
大型语言模型 (LLM) 是一类 AI,可以处理和生成自然语言文本。 它从大量来自书籍、文章、网页和图像等来源的数据中学习,以发现语言模式和规则。
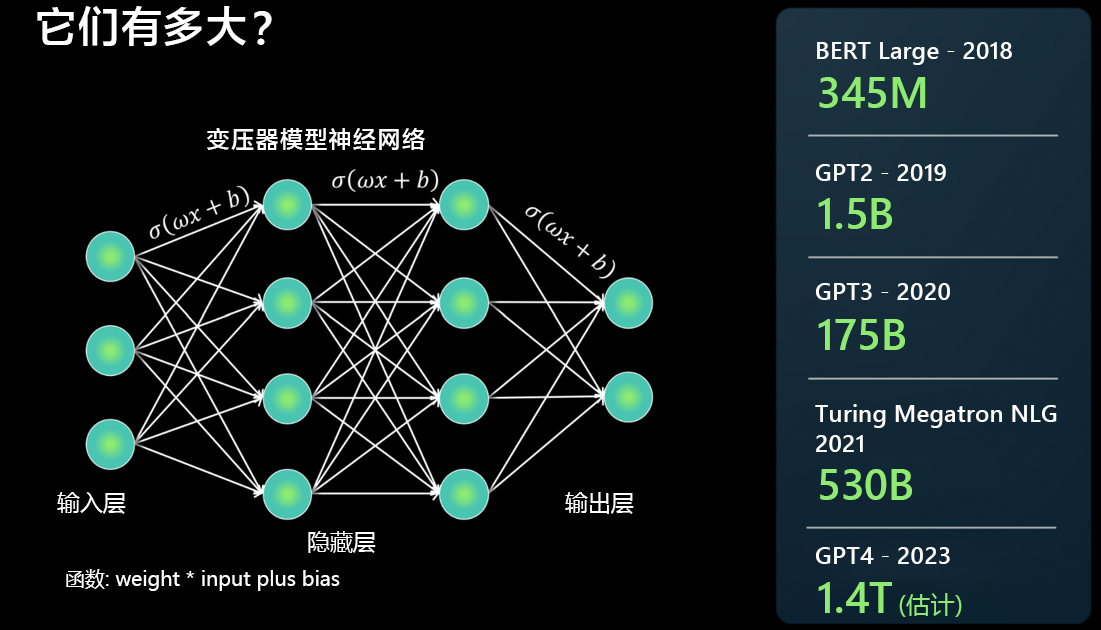
它们有多大?
LLM 是使用神经网络体系结构生成的。 它接收一个输入内容,具有几个隐藏层,这些层可分解语言的不同方面,并在输出层生成内容。
我们经常说最新的基础模型比上一个模型大,但这意味着什么? 简言之,模型具有的参数越多,它可以处理、学习和生成的数据越多。
对于神经网络体系结构的每两个神经元之间的连接,有一个函数:weight * input + bias(权重 * 输入 + 偏差)。 此网络会生成数值,用于确定模型处理语言的方式。
LLM 确实很大,而且发展迅速。 一些模型在 2018 年已可计算数百万个参数。 但今天,GPT-4 可以计算数万亿个参数。
基础模型在何处适合 LLM?
基础模型是指 LLM 的特定实例或版本。 例如,GPT-3、GPT-4 或 Codex。
基础模型是在大型文本库上训练和微调的,如果是 Codex 模型实例,则使用的是代码。
基础模型采用所有不同格式的训练数据,并使用转换器体系结构生成通用模型。 可以创建适应和专用化,以通过提示或微调来实现某些任务。
LLM 与更传统的自然语言处理 (NLP) 有何不同?
有一些内容可将传统 NLP 与 LLM 分开。
| 传统 NLP | 大型语言模型 |
|---|---|
| 每个功能需要一个模型。 | 单个模型用于许多自然语言用例。 |
| 提供一组标记的数据来训练 ML 模型。 | 在基础模型中使用数 TB 的未标记数据。 |
| 用自然语言描述希望模型执行的操作。 | 针对特定用例进行高度优化。 |
LLM 不做什么?
与了解 LLM 可以执行的操作一样,了解它无法执行的操作同样重要,因为这样你可以选择适合作业的工具。
了解语言:LLM 是一个预测引擎,它基于预先存在的文本拉取模式以生成更多文本。 LLM 不理解语言或数学。
了解事实:LLM 没有单独的信息检索和创造性写作模式,它只会预测最有可能的下一个标记。
了解礼仪、情感或道德:LLM 不能展示拟人观或理解伦理。 基础模型的输出是训练数据和提示的组合。