什么是 Azure HDInsight?
让我们回顾一下 HDInsight 的功能和用法。 此概述可帮助你评估 HDInsight 是否满足组织的要求。
什么是大数据?
术语“大数据”描述了组织收集的大量结构化数据和非结构化数据。 此数据对于组织可能非常有用。 具体而言,如果组织可以分析数据以获取见解,则可以更好地制定决策。 结果是这些决策可以帮助组织变得更加成功。 例如,大数据分析可能使商业组织能够识别客户习惯,从而帮助增加销售额。
Azure HDInsight 定义
Azure HDInsight 是面向企业的完全托管、基于云的开放源代码分析服务。 HDInsight 使你能够控制和管理你的大数据。 HDInsight:
是 Hadoop 组件的云发行版。
可让你更轻松、更快、更经济高效地处理大量数据。
支持使用开源框架,如:
- Hadoop
- Apache Spark
- Apache Hive
- Apache Kafka
注意
可以通过这些框架启用各种各样的方案,例如提取、转换和加载 (ETL);数据仓库操作;机器学习;IoT。
HDInsight 可为使用大数据的组织提供多项好处。 它:
开放源代码:使你能够为各种开放源代码框架创建优化的群集。
可靠:为所有生产工作负载提供端到端 SLA。
可缩放:使你能够缩放工作负载以响应需求变化。
提示
通过按需创建群集,可以降低成本。 只需为使用的资源付费。
安全:使你能够通过与以下各项集成来保护企业数据资产:
- Azure 虚拟网络
- Azure 加密技术
- Microsoft Entra ID
合规:满足常用的行业和政府合规性标准。
受监视:与 Azure Monitor 日志集成以提供单个界面。 使用单个界面监视所有群集。
HDInsight 如何帮助你处理大数据
你可以将 HDInsight 用于许多利用大数据处理的方案。 你的数据可能是:
- 历史数据:已收集并存储此数据。
- 实时数据:此数据直接从源流式传输。
下面的类别汇总了此数据的处理方案:
- 批处理
- 数据仓库
- IoT
- 数据科学
- 混合
让我们更仔细地研究这些类别。
批处理
组织使用批处理作业来准备大数据以供进一步分析。 此过程通常涉及三个阶段:
- 从异类数据源读取源数据文件。
- 处理数据。
- 将数据写入可缩放的存储。
注意
此过程通常称为 ETL。
可以将转换的数据用于数据仓库或数据科学。
提示
ETL 的一项重要要求是计算横向扩展。这可以为处理大量数据提供支持。
数据仓库
数据仓库为组织提供了用于存储等待分析的大数据的位置。 使用数据仓库,你可以:
- 存储你的数据。
- 准备数据进行分析。
- 以结构化格式提供准备的数据。 然后,可以使用分析工具来查询数据。
下图描绘了 HDInsight 上的 Apache Hadoop 如何从多个源收集和存储数据。 Apache Spark 和 Apache Hive 准备并分析数据。 最后,数据经过建模以用于商业智能 (BI) 工具。 Power BI 用于数据可视化。
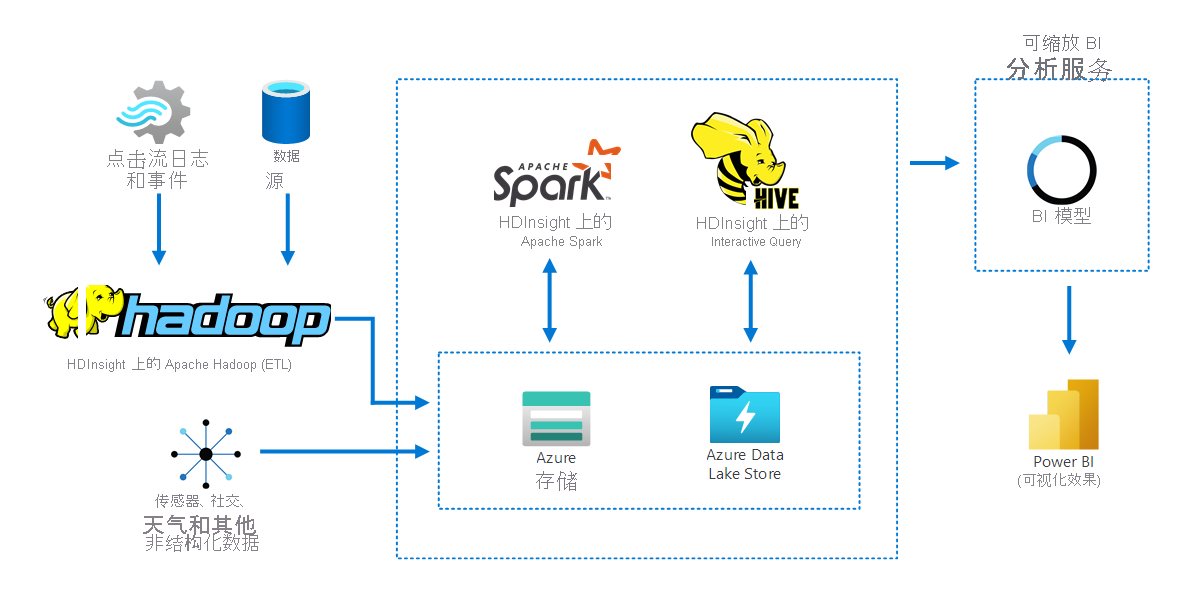
此方案中的组件包括:
- Apache Spark 是一个并行处理框架。 它支持内存中处理,后者可帮助提升大数据分析应用程序的性能。
- HDInsight 中的 Apache Hive 是适用于 Apache Hadoop 的数据仓库系统。 利用 Hive,可进行数据汇总、查询和分析。 可以使用这些组件对任何格式的结构化或非结构化数据执行 PB 规模的查询。
提示
Hive 查询使用 HiveQL(类似于 SQL 的查询语言)编写。
物联网
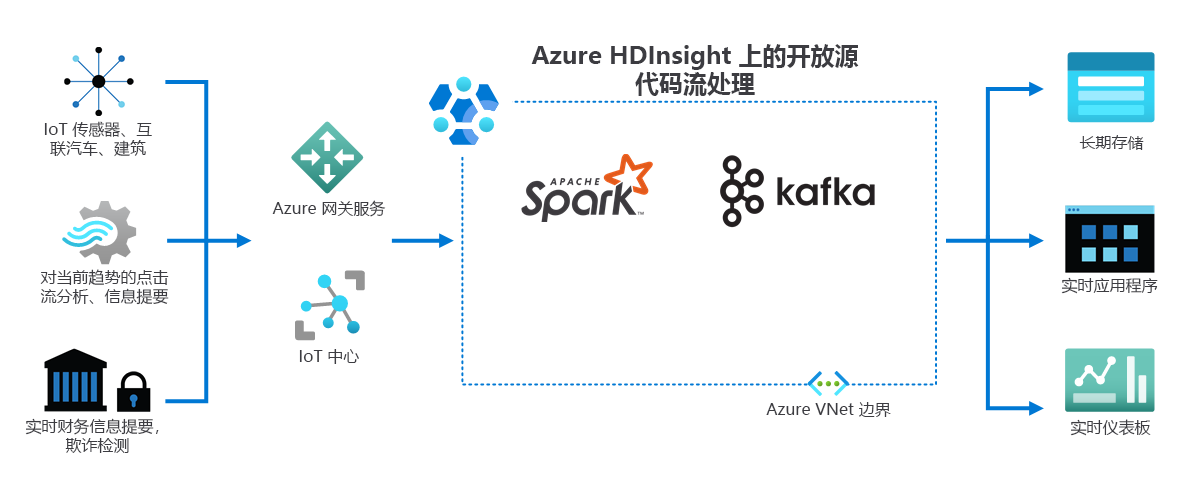
如下图所示,HDInsight 处理从不同设备和传感器实时接收的流式处理数据。 在此示例中,多个开放源代码框架提供流处理,其中包括 Apache Spark 和 Apache Kafka。
Azure 网关服务和 IoT 中心将来自各种源的数据定向到这些框架。 然后,框架处理数据,并将其传递到:
- 长期存储。
- 实时应用。
- 实时仪表板。
数据科学
可以使用 HDInsight 来完成常见的数据科学任务,例如:
- 数据引入。
- 特征工程。
- 建模。
- 模型评估。
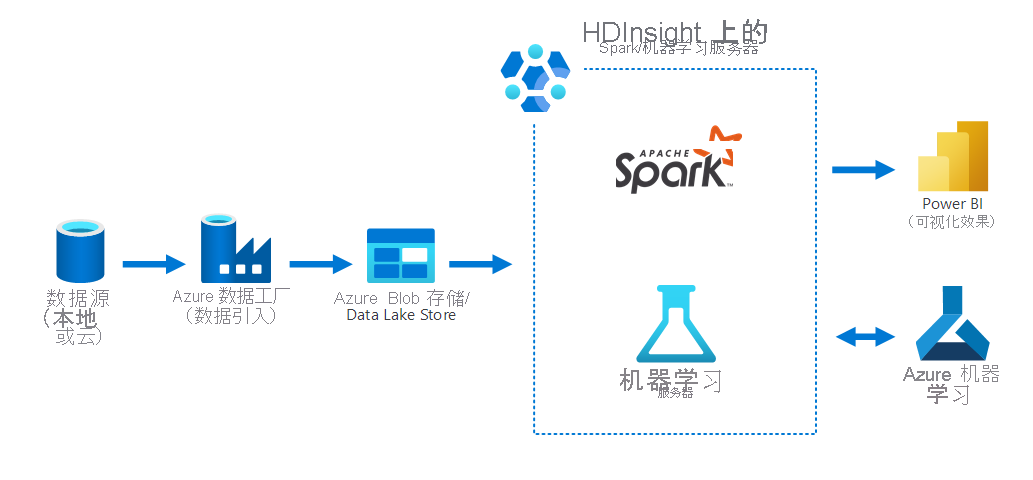
下图描绘了一个数据科学方案,其中:
- 使用 Azure 数据工厂从本地数据源收集数据。
- 然后,引入的数据存储在 Azure 存储(Azure Blob 存储或 Data Lake Store)中。
- HDInsight 上的 Azure Spark 为 Azure 机器学习处理并准备数据。 还可以使用 Power BI 将数据可视化。
混合
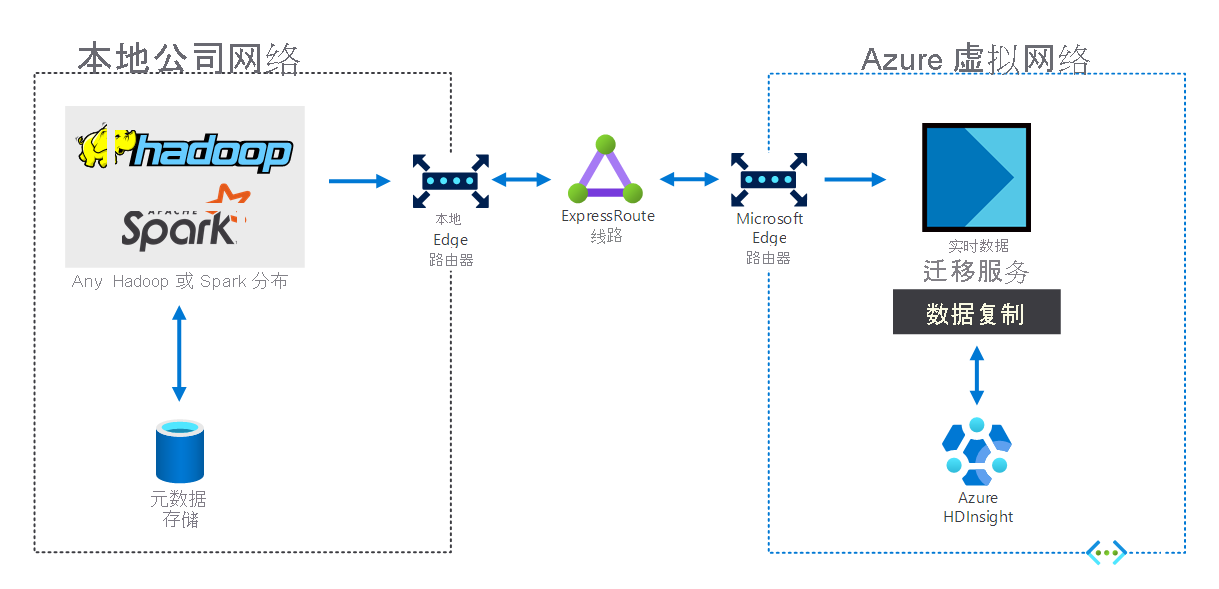
具有本地大数据基础结构的组织可以使用 HDInsight 来扩展到 Azure。 这为你提供了 Azure 云的高级分析功能的优势。 下图描绘了混合方案,其中:
- 本地大数据基础结构由元数据存储以及本地 VM 上的 Hadoop 或 Spark 分发组成。
- Azure ExpressRoute 线路将本地公司网络环境连接到 Azure 虚拟网络。
- 适用于 Azure 的实时数据迁移程序将从本地接收的数据复制到 HDInsight。