Azure 数据工厂的工作原理
在这里,你将了解 Azure 数据工厂的组件和互联系统及其工作原理。 这些知识将有助于你确定如何最好地使用 Azure 数据工厂来满足组织的要求。
Azure 数据工厂是一系列互联系统,这些系统结合起来提供端到端数据分析平台。 在此单元中,你将了解以下 Azure 数据工厂功能:
- 连接和收集
- 转换和扩充
- 持续集成和持续交付 (CI/CD) 和发布
- 监视
你还将了解 Azure 数据工厂的以下关键组件:
- 管道
- 活动
- 数据集
- 链接服务
- 数据流
- 集成运行时
Azure 数据工厂功能
Azure 数据工厂包含多个功能,这些功能结合起来可为你的数据工程师提供完整的数据分析平台。
连接和收集
此过程的第一部分是从相应的数据源收集所需的数据。 这些源可以位于不同的位置,包括本地源和云中。 数据可能是以下类型:
- 结构化
- 非结构化
- 半结构化
此外,这些异构数据可能以不同的速度和间隔到达。 通过 Azure 数据工厂,你可以使用复制活动将数据从各种源移动到云中单一的集中式数据存储。 复制数据后,使用其他系统对其进行转换和分析。
复制活动涉及以下基本步骤:
从源数据存储中读取数据。
对数据执行以下任务:
- 序列化/反序列化
- 压缩/解压缩
- 列映射
注意
可能还有其他任务。
将数据写入目标数据存储(称为“接收器”)。
下图总结了此过程:

转换和扩充
成功地将数据复制到基于云的中心位置后,可以根据需要使用 Azure 数据工厂映射数据流来处理和转换数据。 通过数据流,你可以创建在 Spark 上运行的数据转换图。 但你无需了解 Spark 群集或 Spark 编程。
提示
虽然没有这个必要,但你可能更喜欢手动编写转换代码。 如果是这样,Azure 数据工厂支持通过外部活动来运行转换。
CI/CD 和发布
借助 CI/CD 支持,可以在发布之前以增量方式开发和交付提取、转换和加载 (ETL) 流程。 Azure 数据工厂通过使用以下内容为数据管道提供 CI/CD:
- Azure DevOps
- GitHub
注意
持续集成意味着自动尽早测试对代码库所做的每项更改。 持续交付遵循以下测试,并将更改推送到暂存或生产系统。
在 Azure 数据工厂优化原始数据后,你可将数据加载到业务用户可以从商业智能工具访问的任何分析引擎中,包括:
- Azure Synapse Analytics
- Azure SQL 数据库
- Azure Cosmos DB
监视
成功生成和部署数据集成管道后,必须监视计划的活动和管道。 使用监视可以跟踪成功率和失败率。 Azure 数据工厂使用下列方法之一为管道监视提供支持:
- Azure Monitor
- API
- PowerShell
- Azure Monitor 日志
- Azure 门户中的运行状况面板
Azure 数据工厂组件
Azure 数据工厂由下表中所述的组件组成:
| 组件 | 说明 |
|---|---|
| 管道 | 执行特定工作单元的活动的逻辑分组。 这些活动共同执行任务。 使用管道的优点是,你可以更轻松地将活动作为一组而不是作为单个项进行管理。 |
| 活动 | 管道中的单个处理步骤。 Azure 数据工厂支持三种类型的活动:数据移动活动、数据转换活动和控制活动。 |
| 数据集 | 表示数据存储中的数据结构。 数据集指向(或引用)需在活动中作为输入或输出使用的数据。 |
| 链接服务 | 定义 Azure 数据工厂所需的连接信息以连接到外部资源,如数据源。 Azure 数据工厂出于两个目的会使用链接服务:表示数据存储或计算资源。 |
| 数据流 | 使数据工程师无需编写代码即可开发数据转换逻辑。 数据流使用横向扩展的 Apache Spark 群集作为活动在 Azure 数据工厂管道内运行。 |
| 集成运行时 | Azure 数据工厂使用计算基础结构在不同的网络环境中提供以下数据集成功能:数据流、数据移动、活动调度和 SQL Server Integration Services (SSIS) 包执行。 在 Azure 数据工厂中,集成运行时可作为活动和链接服务之间的桥梁。 |
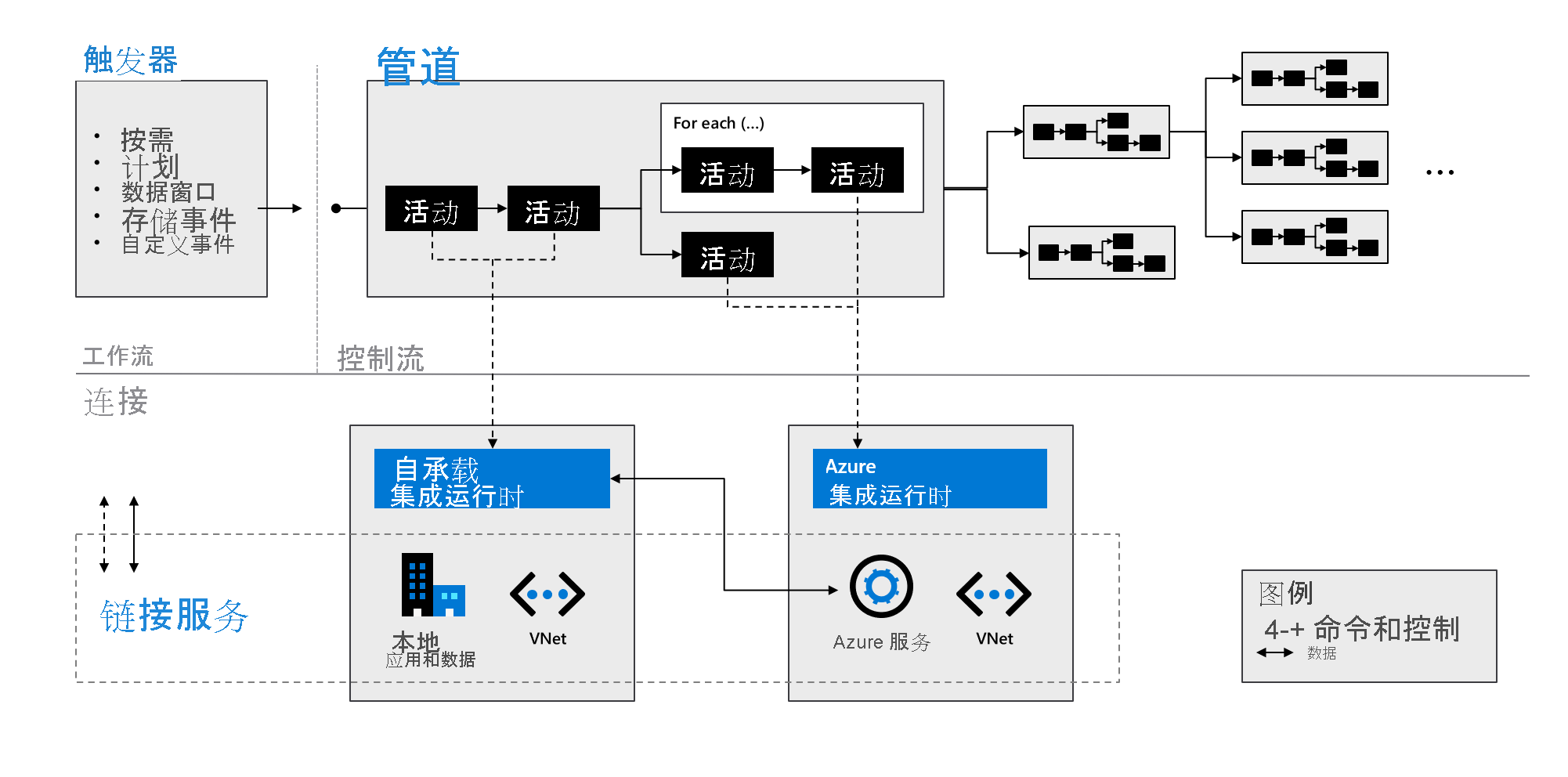
如下图所示,这些组件协同工作,为数据工程师提供完整的端到端平台。 使用数据工厂可以执行以下操作:
- 按需设置触发器,并根据需要计划数据处理。
- 将管道与触发器相关联,或在需要时手动启动。
- 通过集成运行时连接到链接服务(例如本地应用和数据)或 Azure 服务。
- 在 Azure 数据工厂用户体验中(或通过使用 Azure Monitor)以本机方式监视所有管道运行。