服务级别指标 (SLI) 和服务级别目标 (SLO)
本模块到目前为止,介绍了如何提升操作意识,如何扩展对可靠性的理解和认知,以及工作中需要的一些 Azure Monitor 工具。 现在是时候探索此模块中最重要的一个观点,以及实现它的过程。
先来回答一个问题,"如何使用所有这些内容在组织中提高可靠性"。
进入反馈循环
下面是一个可以解决此问题的大胆想法:
适当的反馈循环会提高组织中的可靠性。
提高组织可靠性是一个迭代过程。 本单元中,我们将了解站点可靠性工程领域的一种非常有效的做法,它用于在组织中创建和维护反馈循环,帮助提高可靠性。 最起码,它会激发组织中有关基于目标数据的可靠性的具体对话。
此模块的前面部分中,提到它作为站点可靠性工程的定义:
站点可靠性工程是一种工程规范,致力于持续帮助组织实现系统、服务和产品的适当可靠性级别。
下面是适当可靠性级别的概念。
服务级别指标 (SLI)
服务级别指标 (SLI) 涉及前面讨论的有关可靠性的扩展性理解。 记得这张图吗?
使用 SLI 指定将如何衡量系统的可靠性。 服务良好运行(执行预期操作)的指标是什么? 可以测量哪些内容来回答这个问题?
示例:Web 服务器可用性和延迟
假设处理 Web 服务器及其可用性。 我们可能对它收到的 HTTP 请求数和成功响应的 HTTP 请求数感兴趣。 更准确地说,想要了解作为 Web 服务器它究竟有多么成功,可以通过了解其成功请求数与请求总数的比率来得出结论。
如果用成功请求数除以请求总数,会得到一个比率。 可以将此比率乘以 100 得到一个百分比。 举一个整数例子,如果 Web 服务器收到 100 个请求,成功响应了 80 个,则比率为 0.8。 再乘以 100,就可以说可用性为 80%。
再举一个例子。 这次指定与 Web 服务的延迟相关的度量值。 我们可能想要知道在不到 10 毫秒内完成的操作数与总操作数的比率。 如果进行相同的数学运算 - 阈值时间范围内返回了 80 个请求,除以请求总数 100,这样再次得到了 0.8 的比率。 再乘以 100,于是可以说,通过此度量值得出延迟要求的成功率为 80%。
要清楚地说:这不仅仅关乎网站。 如果有处理数据的管道服务,则可以说需要测量覆盖范围(如我们处理的数据量)。 不同的系统,相同的基本运算。
SLI:何处测量
若要使 SLI 在使用目标数据的具体讨论中有用,除了指定测量的内容外,还需要指定一点。 创建 SLI 时,不仅需要记下测量的内容,还需要记下测量的位置。
例如,当指定测量之前提到的 Web 服务器的可用性的内容时,没有说从哪里检索到总 HTTP 请求数和成功请求数。 如果尝试就此 Web 服务器可靠性与一些同事进行对话,你看着服务器前面负载均衡器中收集的请求统计信息,但他们看着服务器本身的统计信息,则对话可能不会顺畅。 这些数字可能截然不同,因为负载均衡器可能看到传入网络的所有请求,但如果网络或负载均衡器本身有问题,则并非所有请求都可以到达服务器。 我们将根据两个不同的数据集来下结论。
解决这个问题的简单方法是,在 SLI 中指出具体的数据源。 对于 Web 服务器的可用性,可以说“在负载均衡器处测得的成功请求数与总请求数的比率”。 对于延迟,可以说“在客户端处测得的不到 10 毫秒内完成的操作数与总操作数的比率”。
这将导致一个逻辑问题:测量 SLI 的最佳位置在哪里? 遗憾的是,没有通用的“正确”答案。 做这个决定时,必须明白总会有取舍。 回到之前关于可靠性的讨论,可以提供这样一个指导:尝试在最准确地反映客户体验的地方进行测量。
服务级别目标 (SLO)
确定要测量的内容(和位置)是一个很好的开始,但这只是成功了一半。 如果找到了 Web 服务器可用性 SLI 所需的指标,并且发现确实是 80% 的可用性。
这是好呢还是不好呢? 它属于“适当可靠性级别”吗?
要回答这些问题,需要为该 SLI 设置一个目标:服务级别目标 (SLO)。 此目标将明确表明该服务的目标。
用于创建 SLO 的基本步骤包括以下部分:
要测量的内容:请求数、存储检查、操作;就是要测量什么。
所需比率:例如“50% 的成功时间”、“99.9% 的时间可以读取”、“90% 的时间在 10ms 内返回”。
时间范围:要为目标使用的时间段:最后 10 分钟、上个季度期间、30 天的滚动时间内。 SLO 多半使用滚动时间段或者日历单位(如“一个月”)来指定,使我们可以比较不同时间段的数据。
将这些部分组合在一起,并在其中包含重要的“位置”信息,示例 SLO 如下所示:
据负载均衡器报告,最近 30 天内,90% 的 HTTP 请求成功。
同样,衡量延迟的基本 SLO 可能如下所示:
据客户端报告,最近 30 天内,90% 的 HTTP 请求在 20 毫秒内返回。
将这种做法引入组织时,从这种简单的基本 SLO 开始。 之后可以根据需要创建更复杂的 SLO。
Azure Monitor 上的 SLI 和 SLO
本单元的最后一个部分,我们来看看如何使用 Log Analytics 在 Azure Monitor 中表示简单的 SLI/SLO。 为了保持一致,我们返回到 Web 服务器示例。
在上一单元中,我们了解到可使用 Kusto 查询语言 (KQL) 在 Log Analytics 中创建查询。 下面是一个 KQL 查询,它显示了 Web 服务的可用性 SLI:
requests
| where timestamp > ago(30d)
| summarize succeed = count (success == true), failed = count (success == false), total = count() by bin(timestamp, 5m)
| extend SLI = succeed * 100.00 / total
| project SLI, timestamp
| render timechart
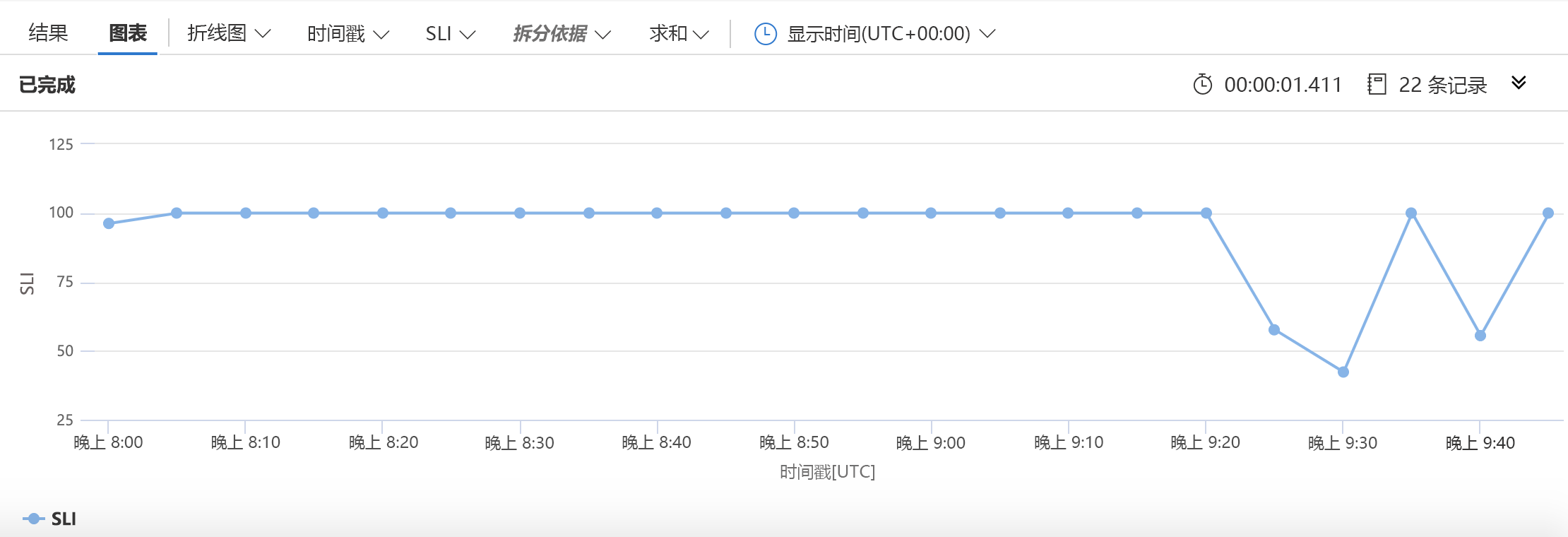
像以前一样,先指定数据源:requests 表。 然后,缩小要使用的数据范围,仅使用过去 30 天内的有用信息。 接着,(在 5 分钟存储桶中)收集成功请求数、失败请求数和请求总数。 使用之前看到的简单算法创建 SLI。 告诉 KQL 绘制该 SLI 与时间戳,然后创建如下所示的图表:
现在我们来一行行看一下 SLO 的简单表示形式:
requests
| where timestamp > ago(5h)
| summarize succeed = count (success == true), failed = count (success == false), total = count() by bin(timestamp, 5m)
| extend SLI = succeed * 100.00 / total
| extend SLO = 80.0
| project SLI, timestamp, SLO
| render timechart
此示例较之前示例有两行发生了更改。 第一个定义了将用于 SLO 的数字,第二个告诉 KQL 应将 SLO 包含在图表中。 结果类似以下形式:
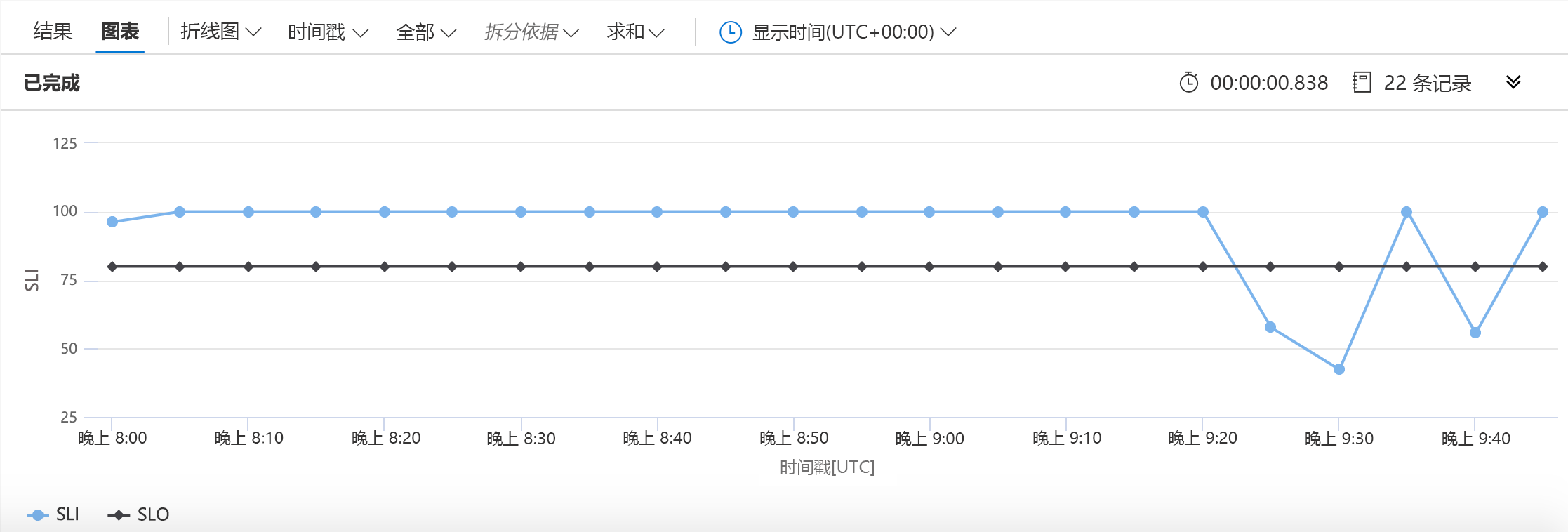
此图表中,可以很容易看到低于可用性目标的时间。
使用 SLI/SlO
SLI 和 SLO 始终都会出现一些优化(不管怎样,这是一个迭代过程)。 但一旦完成,如何处理这些信息呢?
好消息是可能会注意到,仅构建 SLI 和 SLO 就会对组织产生积极影响。 它要求与利益干系人进行讨论,还要进行其他保证事情朝良好方向运行的沟通。 下一轮围绕如何处理这些问题的讨论也同样有用。
最终,SLI 和 SLO 成为工作规划工具。 它们有助于制定工程决策,例如“该为服务使用新功能还是该专注于可靠性工作?”它们可帮助实现之前讨论的反馈循环。
SLI 和 SLO 的次要但相当常见的用途是作为更为直接的监视/响应系统的一部分。 除了工作规划方面(首先要关注的方面),许多人都将它们用作操作信号。 例如,如果服务长时间低于其 SLO,可选择向其人员发出警报。 此类警报将我们引入此模块的下一单元。