对小型查找实体进行建模
数据模型包括两个小的引用数据实体:ProductCategory 和 ProductTag。 这些实体用于引用值,并且通过 1:Many relationship 与其他实体相关。
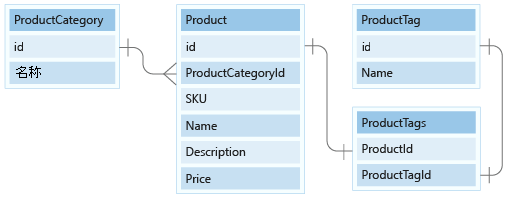
在本单元中,我们将对文档模型中的 ProductCategory 和 ProductTag 实体进行建模。
对产品类别进行建模
首先对于类别,我们将对使用其 ID 和“名称”列作为唯一属性的数据进行建模,并将其放入名为 的新容器中ProductCategory。
接下来,需选择分区键。 接下来探索需对此数据执行的操作。
我们将创建一个新的产品类别,编辑一个产品类别,然后列出所有产品类别。 创建和编辑产品类别不是经常进行的操作。 我们的电子商务应用程序通常会在用户访问网站时列出所有产品类别。 因此,最后一个操作执行最频繁。
最后一个操作的查询将如下所示:SELECT * FROM c。
使用 ID 作为所选分区键,此查询现在将跨分区,即使我们想要尝试优化这些读取量大的操作,也尽可能仅使用单个分区。 我们还知道,产品类别的数据永远不会增长到接近 20 GB 的大小,那么,当我们列出所有产品类别时,这些信息将如何帮助我们对数据建模,从而进行单个分区查询。
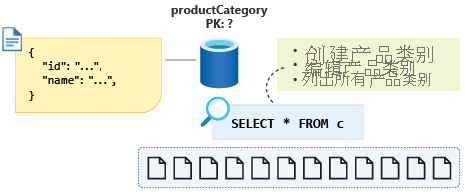
为了将此少量数据强制回单个分区,我们可以将实体鉴别器属性添加到架构中,并将其用作此容器的分区键。 通过为容器中这一类型的所有文档分配一个常量值,可以确保现在有一个单一分区查询。 在这种情况下,我们将调用 type 属性,并给出 category 的常量值。 我们的查询现在如下所示:SELECT * FROM c WHERE c.type = ”category”。

对产品标记进行建模
接下来是 ProductTag 实体。 此实体在功能上与我们上一部分讨论的 ProductCategory 实体几乎完全相同。 我们在此处采用相同的方法,对文档进行建模,以包含 ID 和名称属性,并创建名为 type 的实体鉴别器属性(在本例中常量值为 tag)。 我们来新建一个名为 ProductTag 的容器,并将 type 设置为新的分区键。
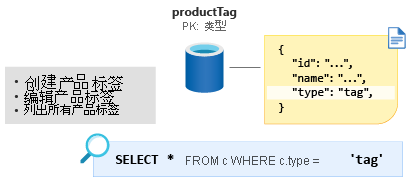
一些用户会发现用于对小型查找表进行建模的这种技术很奇怪。 不过,通过该方式对数据进行建模可提供进一步优化的机会,下一模块中将对此进行介绍。