了解可训练分类器
组织对内容进行分类和标记,以便保护和正确处理内容。 对内容进行分类和标记是信息保护规则的起点。 Microsoft 365 有三种内容分类方式:
手动。 手动分类需要人工判断和操作。 用户和管理员在遇到内容时对其进行分类。 可以使用预先存在的标签和敏感信息类型,也可以使用自定义创建的标签和敏感信息类型。 然后,可以保护内容并管理其处置。
自动模式匹配。 此类别的分类机制包括通过以下方式查找内容:
- 关键字或元数据值(关键字查询语言)。
- 使用以前识别的敏感信息模式(如社会保障、信用卡或银行帐号)。
- 识别项目,因为它是模板的变体(文档指纹识别,本培训的后续单元对此进行了介绍)。
- 使用存在的精确字符串完全匹配数据。
可训练分类器。 Microsoft 365 可训练分类器是组织可以“训练”以识别各种类型的内容的工具。 Microsoft 365 包含内容广泛的预定义分类器列表。 组织还可以创建自己的自定义分类器。 可以通过为分配器提供要分析的样本来对其进行训练。 训练分类器后,组织可以使用它来识别应用 Office 敏感度标签、通信合规性策略和保留标签策略的项目。
本单元将深入介绍可训练分类器的使用。
可训练的分类器
若要开始在 Microsoft Purview 中使用可训练分类器,可以先启动扫描流程。 此流程将分析公司的数据,并确定系统可用于训练分类器的模式。 系统扫描数据后,会识别常见主题和模式。 然后,系统可以使用此信息为可训练分类器创建规则。 此流程有助于确保可训练分类器准确有效地识别和分类数据。 扫描流程完成后,可以使用标识的模式和规则训练可训练分类器。 训练完分类器后,可以将其应用于新数据以自动对其进行分类。
警告
扫描可能需要 7 到 14 天才能完成。 如果不想通过运行扫描流程来为组织创建自定义训练分类器,可以使用 Microsoft Purview 的内置分类器。
首次访问 Microsoft Purview 合规门户中的“训练分类器”页时,将显示以下屏幕截图。
首先,创建自定义可训练分类器涉及提供手动选取且与类别正匹配的样本。 处理这些样本后,可以通过混合提供阳性和阴性样本来对分类器的预测能力进行测试。 本单元将深入介绍如何创建和训练自定义分类器。 它还研究了如何通过再训练来提高自定义可训练分类器和预训练分类器在其生命周期内的性能。
该分类方法对于自动或手动模式匹配方法无法轻松识别的内容非常有效。 这种分类方法更多的是使用分类器根据项目是什么来识别项目,而不是通过项目中的元素(模式匹配)来识别。 分类器通过查看数百个内容类型的示例来学习如何识别该内容类型。
注意
可以通过在筛选器面板中展开可训练分类器来在内容浏览器工具中查看可训练分类器。 可训练分类器会自动显示在 SharePoint、Teams 和 OneDrive 中发现的事件数,而无需任何标记。 如果不想使用此功能,则必须向 Microsoft 支持部门提出请求以禁用现成分类。 这样会在创建标签策略之前禁用对敏感内容和标签内容的扫描。
分类器可用作以下操作的条件:
- 使用敏感度标签进行 Office 自动标记
- 根据条件自动应用保留标签策略
- 通信合规性
注意
分类器仅适用于未加密的项。
有两种类型的可训练分类器:
- 预先训练的分类器。 Microsoft 创建并预先训练了多个分类器,无需训练即可开始使用它们。 这些分类器显示的状态为“可供使用”。
- 自定义可训练分类器。 如果组织的分类需求超出了预先训练的分类器所涵盖的范围,则可以创建和训练自己的分类器。
以下部分将深入介绍这些分类器类型。
预先训练的分类器
Microsoft 365 附带多个预先训练的分类器:
成人、猥亵和血腥图像。 检测这些类型的图像。 图像的大小必须介于 50 KB 和 4 MB 之间。 它们的高度 x 宽度尺寸还必须大于 50 x 50 像素。 系统支持扫描和检测 Exchange Online 电子邮件以及 Microsoft Teams 频道和聊天。
协议。 此分类器检测与法律协议相关的内容。 例如,工作说明书、贷款和租赁协议以及雇佣和非竞争协议。
客户投诉。 客户投诉分类器可检测有关组织的产品或服务的反馈和投诉。 此分类器可帮助你达到有关投诉检测和分类的监管要求,例如消费者金融保护局和食品药品监督管理局的要求。
歧视。 此分类器可检测显式的色情语言,与其他社区相比,它对针对非洲美洲/黑色社区的攻击性语言很敏感。
财务。 此分类器可检测企业财务、会计、经济、银行和投资类别中的内容。
骚扰。 此分类器检测特定类别的冒犯性语言文本项目。 这些项目必须涉及基于以下特征针对一个或多个个人的冒犯性行为:种族、民族、宗教、国籍、性别、性取向、年龄、残疾。
医疗保健。 此分类器可检测医疗和医疗保健管理方面的内容。 例如,医疗服务、诊断、治疗、索赔等。
人力资源 (HR)。 此分类器可检测人力资源相关类别中的内容。 例如,招聘、面试、招聘、培训、评估、警告和解雇。
知识产权 (IP)。 此分类器可检测知识产权相关类别中的内容,例如商业机密和类似的机密信息。
信息技术 (IT)。 此分类器可检测“信息技术”和“网络安全”类别中的内容。 例如,网络设置、信息安全、硬件和软件。
法律事务。 此分类器可检测与法律事务相关的类别中的内容。 例如,诉讼、法律程序、法律义务、法律术语、法律和立法。
采购。 此分类器可检测商品及服务供应的投标、报价、购买和支付类别的内容。
脏话。 此分类器可检测包含使大多数人难过的表达式的冒犯性语言文本项的特定类别。
简历。 此分类器检测 docx、.pdf、.rtf 和 .txt 项目,这些项目是申请人个人、教育、专业资格、工作经验和其他个人识别信息的文本描述。
源代码。 此分类器检测包含用 GitHub 上最常用的 25 种计算机编程语言编写的一组指令和语句的项目:ActionScript、C、C#、C++、Clojure、CoffeeScript、Go、Haskell、Java、JavaScript、Lua、MATLAB、Objective- C、Perl、PHP、Python、R、Ruby、Scala、Shell、Swift、TeX、Vim 脚本。
注意
源代码分类器可检测大部分文本是源代码的情况。 它不会检测穿插纯文本的源代码文本。
税务。 此分类器可检测与税务相关的内容,例如税务规划、税单、税务申报、税务法规。
威胁。 此分类器可检测与实施暴力或对人身或财产造成人身伤害或损坏的威胁相关的特定类别的攻击性语言文本项目。
这些可训练分类器显示在 Microsoft Purview 合规性门户中。 在导航窗格中,选择“数据分类”。 在“数据分类”页上,选择“可训练的分类器”选项卡。查看状态为“可供使用”的分类器。
自定义分类器
对于某些组织,预先训练的分类器无法满足其数据分类需求。 在这种情况下,组织可以创建和训练自己的分类器。 创建自定义分类器涉及更多工作,但组织可以对其进行定制以更好地满足其需求。 创建自定义分类器所涉及的大致步骤包括:
- 开始创建自定义可训练分类器,方法是向该分类器提供肯定属于该类别的示例。
- 分类器处理这些示例后,可以通过混合提供匹配和非匹配示例来对其进行测试。
- 然后,分类器会预测任何给定项是否属于要构建的类别。
- 然后确认其结果,并整理出阳性、阴性、误报和漏报,以帮助提高其预测的准确性。
- 对测试结果感到满意后,可以通过发布分类器来部署分类器。
发布分类器时,它会对 SharePoint Online、Exchange 和 OneDrive 等位置中的项目进行排序,并将内容分类。 发布分类器后,可以继续使用类似于初始训练过程的反馈过程对其进行训练。
例如,可以为以下内容创建可训练分类器:
- 法律文档。 例如,律师客户特权、结业集、工作说明书。
- 战略业务文档。 例如,新闻稿、并购、交易、业务或营销计划、知识产权、专利和设计文档。
- 定价信息。 例如,发票、报价单、工作订单和投标文档。
- 财务信息。 例如,组织投资、季度或年度业绩。
准备自定义可训练分类器
在深入了解之前,了解创建自定义可训练分类器所涉及的组件会很有帮助。 以下部分将深入介绍其中每个组件。
日程表
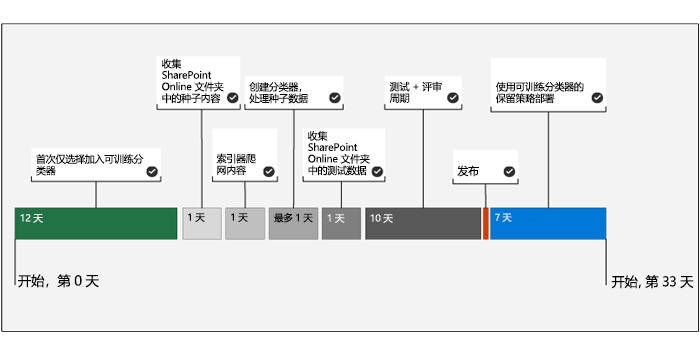
下图显示了反映了可训练分类器样本部署的时间线。
提示
系统只需在第一次选择加入可训练分类器。 Microsoft 365 需要 12 天才能完成对组织内容的基线评估。 Microsoft 365 全局管理员必须启动选择加入过程。
总体工作流
若要详细了解创建自定义可训练分类器的总体工作流,请参阅创建自定义可训练分类器的过程流。
种子内容
Microsoft Purview 使用可训练分类器来独立准确地将项目标识为特定类别的内容。 若要创建可训练的分类器,组织必须先向其提供该类别中内容类型的多个样本。 种子设定是将样本馈送到可训练分类器的过程。 组织必须选择要用于表示内容类别的种子内容。
提示
必须至少有 50 个阳性样本,最多 500 个。 样本。 可训练分类器最多可处理 500 个最新创建的样本(按文件创建日期/时间戳)。 提供的样本越多,分类器的预测就越准确。
测试内容
可训练分类器处理足够多的阳性样本来生成预测模型后,组织必须对分类器的预测进行测试。 应使用与最初提供的初始种子数据不同的数据进行测试。 测试应验证分类器是否可以正确区分与类别匹配的项目和不匹配的项目。 在测试一开始,应该选择另一组(最好是更大的)手动选择的内容,这些内容称为测试样本。 它应包含属于该类别的样本和不属于该类别的样本。
分类器处理此测试样本后,必须手动查看结果。 执行此操作时,应验证每个预测是正确、不正确还是不确定。 可训练分类器使用此反馈来改进其预测模型。
提示
为了获得最佳结果,测试样本应至少包含 200 个项目。 它应包括均匀分布的阳性匹配和阴性匹配。