混合文件访问要求
前面的单元重点介绍了存储解决方案的作用。 本单元将重点介绍数据所在的位置。 具体而言,我们将介绍混合文件访问注意事项,以及如何对其进行处理。
混合文件访问概述
你已决定在 Azure 运行目前在数据中心运行的 HPC 工作负载。 你的计算环境会访问你的 NAS 上的数据,而该 NAS 正在为你的工作负载提供 NFSv3 操作。 它已在此处运行多年,但也许你的 NAS 环境快要到达其周期末尾。 你正在考虑将它长期迁移到云中,而不是替换它。
作出此决定后,但在完整云部署 HPC 工作负载前,需要确定 Azure 策略并建立你的基准帐户/订阅/安全设置。 接下来的操作比较困难:那就是移动 HPC 工作负载!
本模块不就 HPC 群集及其管理平面的扩展进行讨论。 我们假设你已确定了想要在群集中运行的虚拟机类型和数量。
现在,我们还假设你的目标是按原样运行工作负载。 也就是说,你不想修改当前在本地部署的逻辑或访问方法。 这意味着代码希望数据在群集成员本地文件系统的目录路径上。
首要目标是了解所需数据及其来源。 数据可能位于单个 NAS 环境的单个目录中,也可能分布在不同环境中。
下一个目标是确定运行工作负载所需的数据量。 源数据是几 GB 还是几百 TB?
最后,必须确定如何在 Azure 计算中显示数据。 它是在本地提供给每个 HPC 群集计算机,还是由基于云的 NAS 解决方案共享?
远程数据访问注意事项
你有一个想要在 Azure 中运行的基因组学工作负载。 你的数据由基因排序器本地生成并发送到本地 NAS 环境。 本地研究人员将数据用于各种用途。 这些研究人员可能还希望使用你打算在 Azure 中运行的 HPC 工作负载的结果。 但其中一些研究人员会使用本地工作站来实现此目的。 我们还将假设会定期生成新的基因组数据。 因此在需要替换/刷新数据之前,只间隔了一段有限的时间供你运行当前的工作负载。
面临的难题是将数据以经济高效的方式按时提供给 Azure 计算,但仍保留对其的本地访问权限。
下面是尝试在 Azure 中运行 HPC 工作负载时要询问的一些主要问题:
- 是否可在不保留本地副本的情况下将源数据移动到 Azure?
- 是否可在不保留本地副本的情况下将结果数据保存在 Azure 存储?
- 本地用户是否需要并发访问源数据或结果数据?
- 如果需要,他们是否能够对 Azure 中的数据进行操作,或者是否需要将数据存储在本地?
如果数据需要保存在本地,则必须将多少数据复制到 Azure 来执行工作负载? 处理数据后,需要多长时间才能处理新的数据集? 你的工作负载是否将在该时间段内运行?
此外,你需要考虑与 Azure 的网络连接。 你是否仅可通过 Internet 访问 Azure? 这种局限可能是正常的,具体取决于要复制/传输的数据大小和两次刷新之间的时间量。 或许你每次都要复制大量数据。 你可能需要使用 Azure ExpressRoute 通过广域网 (WAN) 连接到 Azure,这会提供更多的带宽来复制/传输数据。
如果已与 Azure 建立 ExpressRoute 连接,请注意以下事项:可用于数据复制操作的带宽有多少? 如果此链接严重饱和,则可能需要考虑一天中传输数据的时间。 或者,可能要配置更大的 ExpressRoute 连接来容纳大型数据传输。
如果将数据移至 Azure,可能需要考虑如何保护数据。 例如,你可能有一个本地 NFS 环境,它使用目录服务来帮助将权限扩展给你的用户。 如果你打算将此安全性复制到 Azure,则需要确定是否需要将目录服务作为 Azure 扩展的一部分。 但如果工作负载仅限于 HPC 群集,而且结果会被传输回本地环境,则可能忽略这些要求。
接下来,我们将考虑访问数据的方法:缓存、复制和同步。
缓存、复制与同步
我们来讨论一下可用于向 Azure 添加数据的常规方法。 此数据传输讨论的焦点在于活动数据,而不是数据存档和备份。
假设在我们讨论中传输的数据是 HPC 工作负载的工作集。 在生命科学 HPC 环境中,数据可能包含原始基因组数据等源数据、用于处理该数据的二进制,或者参照基因组等补充数据。 此数据需在到达后立即处理,或在不久后得到处理。 数据还必须存储在 IOPS、延迟、吞吐量和成本各方面适当的介质上。 与之相对,存档/备份数据通常传输到成本尽可能低的存储解决方案,这并不是为了实现高性能访问。
传输活动数据的主要方法是缓存、复制和同步。 我们将从复制开始来讨论一下每种方法的优点和缺点。
复制数据是移动数据最常用的方法。 数据会根据你使用的工具以不同的方式进行复制。
请考虑以下因素:
- 文件大小。
- 文件数。
- 可用于传输数据的吞吐量。
- 可用于传输的时间。
如果要将少量大小合理的文件传输到远程目标,则使用 cp 等基本复制工具即可。 如果通过不安全的网络传输数据,可能需要使用 scp 而不是 cp:scp 通过安全外壳 (SSH) 连接进行加密。
下面是优化复制操作的一些方法,具体取决于你打算将数据复制到的位置。 例如,如果要将文件直接复制到每台 HPC 计算机,可以对每个节点计划单个复制操作。
跨 WAN 链路复制数据时需要注意的是要复制的文件和文件夹数量。 如果要复制大量小型文件,则需要将复制与存档(例如 tar)结合使用,以消除来自 WAN 链接的元数据开销。 将 .tar 文件复制到 Azure,然后将数据复制到计算机。
复制的另一个问题是存在中断风险。 例如,如果你正在尝试复制大型文件,但出现了传输错误,那么使用 cp 是没用的,因为它无法从复制中断的位置重新开始。
复制数据时遇到的最后一个问题是复制可能会过时。 例如,可以将数据集复制到 Azure。 与此同时,一位本地用户可能更新了一个或多个源文件。 你需要确定流程,以确保所用数据正确。
同步数据是一种复制形式,但是更加复杂。 通过像 rsync 这样的工具,我们不仅可从源复制数据,还可在源与目标之间同步数据。 rsync 会根据文件大小和修改日期,确保文件是最新的。 通过同步,可将使用过时文件的可能性降到最低。
rsync 具有恢复功能。 例如,如果你要复制一个大文件,但遇到了传输问题,则 rsync 可以从中断的位置继续。
rsync 免费提供且易于实现。 它的功能不止我们此处所介绍的这些。 通过它,你可以根据本地数据在 Azure 中建立同步文件系统。
此外,rsync 还有一些需提及的局限性。 首先,它是单线程工具。 一次只能运行一个操作,不能并行访问数据。 复制实用工具 cp 也是单线程工具。 因此,这些工具并没有针对涉及大量数据和较短操作时间的大规模复制/同步操作进行优化。 此外,还需要运行该工具以同步数据。 运行该工具会增加环境的复杂性,因为你需要确保它是依据时间段要求运行的。 例如,你可能需要计划一个包含 rsync 的脚本。 此方法需要添加脚本日志记录,以防出现问题。 这也意味着你需要注意这些问题。 复杂程度可能会急剧增加。
如果你正在运行商业 NAS 解决方案,则可以购买服务器级别的同步工具,这些工具更加成熟且提供多线程性能。 这类工具在启用并配置后将始终运行,并且在一个或多个源与目标之间同步数据。
复制加同步会传输源数据的完整副本。 如果数据集或文件较小,则完整文件传输可能很不错。 如果源数据包含许多大型文件,则可能会导致严重的延迟。 传输的数据越多,传输所需的时间就越长。 同步将确保你只会将新文件添加到云。 但仍然必须完整地传输这些文件。 在某些情况下,HPC 工作负载可能不需要完整的给定文件集。 它可能只需访问文件的特定区域。
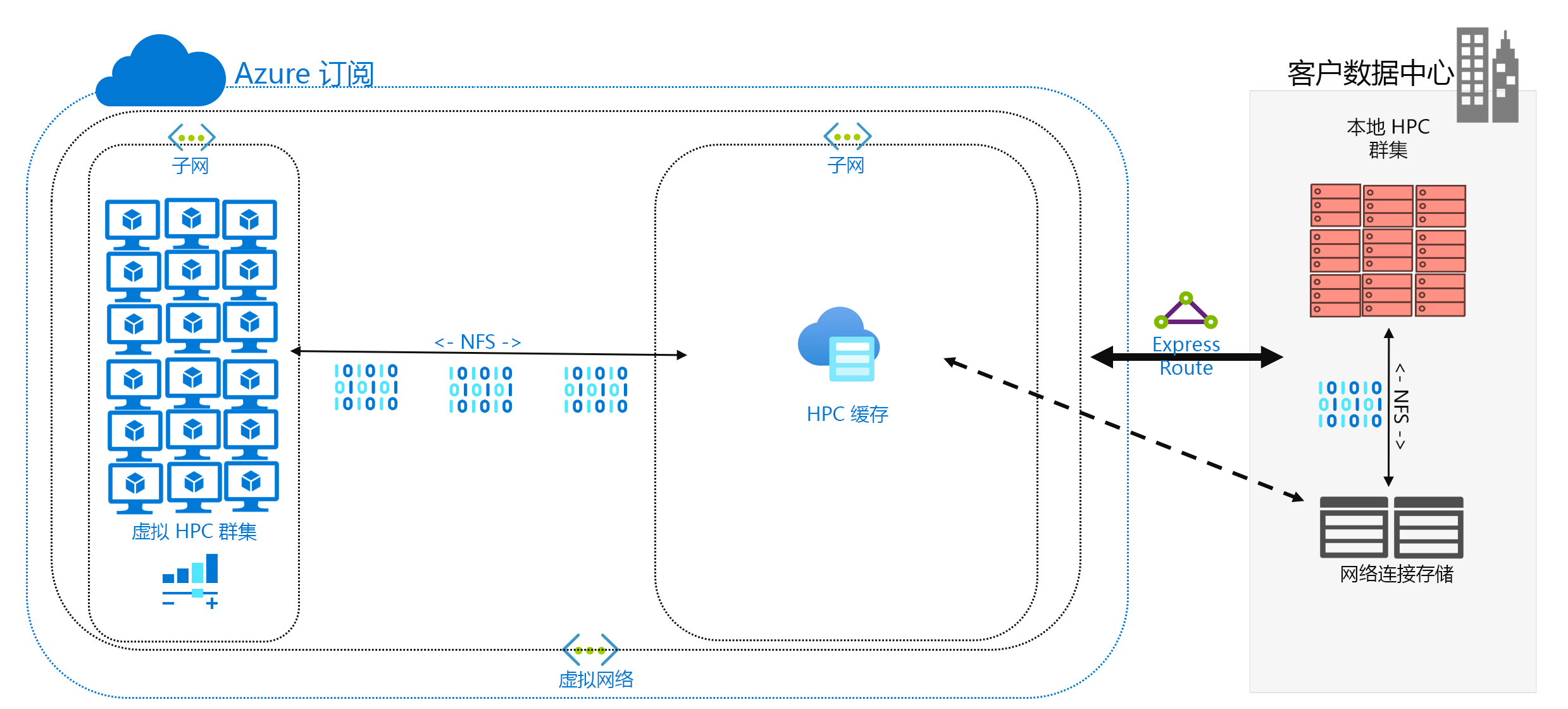
缓存数据是将数据添加到 Azure 的第三种方法。 缓存是指通过缓存检索和显示文件数据。 缓存可位于单独的本地客户端,也可以是为所有 HPC 计算机提供服务的分布式缓存。 缓存通常用于尽量降低延迟,因此在延迟边界放置缓存是提供数据的最佳方法。 例如,你可通过 WAN 连接来缓存数据请求,方法是将分布式缓存放置在通过 WAN 链路连接到本地存储的 Azure 计算中。
在本模块中,我们具体指的是文件缓存,其中缓存本身会处理来自计算机的请求。 它会检索来自后端存储环境(如 NFS NAS 环境)的数据,并向客户端显示该数据。
缓存的功能分为两个部分。 首先,缓存不会检索整个文件。 缓存检索请求的文件子集或字节范围,而不是整个文件。 检索基于客户端对这些字节范围的请求。 当仅需检索文件的一小部分时,这种检索方法可最大程度地降低检索整个大型文件所造成的性能损失。
其次,缓存还会优化对频繁请求数据的重复访问。 当某字节范围位于缓存中后,对该数据的后续请求就会很快。 只有最初的检索速度较慢。 如果运行大量访问公用文件的 HPC 客户端/线程时,你会发现诸多好处。
缓存在混合方案下还具有另外一个优点。 数据只是暂时存储在 Azure 中(缓存中)。 并且仅在 HPC 工作负载操作期间存储。 因此你可减少在更具体地将数据移动到 Azure 时所产生的逻辑开销。 可以将数据隐私和安全性的问题隔离到缓存和 HPC 计算机自身。
最后,某些缓存解决方案可提供所谓的“属性检查”。 与同步类似,缓存会定期检查源中文件的属性,并在源出现较大文件修改时检索字节范围。 此体系结构可确保 HPC 环境始终使用最新数据进行操作。