使用 Microsoft Fabric 浏览和处理数据
数据是数据科学的基石,尤其是在旨在训练机器学习模型以实现人工智能时。 通常,随着训练数据集大小的增加,模型会表现出增强的性能。 除了数据数量外,数据的质量也同样重要。
为了保证数据的质量和数量,使用 Microsoft Fabric 强大的数据引入和处理引擎是值得的。 在建立基本的数据引入、浏览和转换管道时,可以灵活地选择低代码或代码优先方法。
将数据引入 Microsoft Fabric
若要在 Microsoft Fabric 中处理数据,首先需要引入数据。 你可以从多个源(本地和云数据源)引入数据。 例如,可以从本地计算机或 Azure Data Lake Storage (Gen2) 中存储的 CSV 文件引入数据。
提示
连接到数据源后,可以将数据保存到 Microsoft Fabric 湖屋中。 你可以使用湖屋作为中心位置来存储任何结构化、半结构化和非结构化文件。 然后,每当想要访问数据进行浏览或转换时,你都可以轻松连接到该湖屋。
浏览和转换数据
作为数据科学家,你可能最熟悉的是在笔记本中编写和执行代码。 Microsoft Fabric 提供了一种大家熟悉的笔记本体验,该体验由 Spark 计算提供支持。
Apache Spark 是用于实现大规模数据处理和分析的开源并行处理框架。
笔记本会自动附加到 Spark 计算。 首次在笔记本中运行单元格时,会启动一个新的 Spark 会话。 运行后续单元格时,会话将保留。 Spark 会话将在处于非活动状态一段时间后自动停止,以节省成本。 也可以手动停止会话。
在笔记本中工作时,可以选择要使用的语言。 对于数据科学工作负载,你可能会使用 PySpark (Python) 或 SparkR (R)。
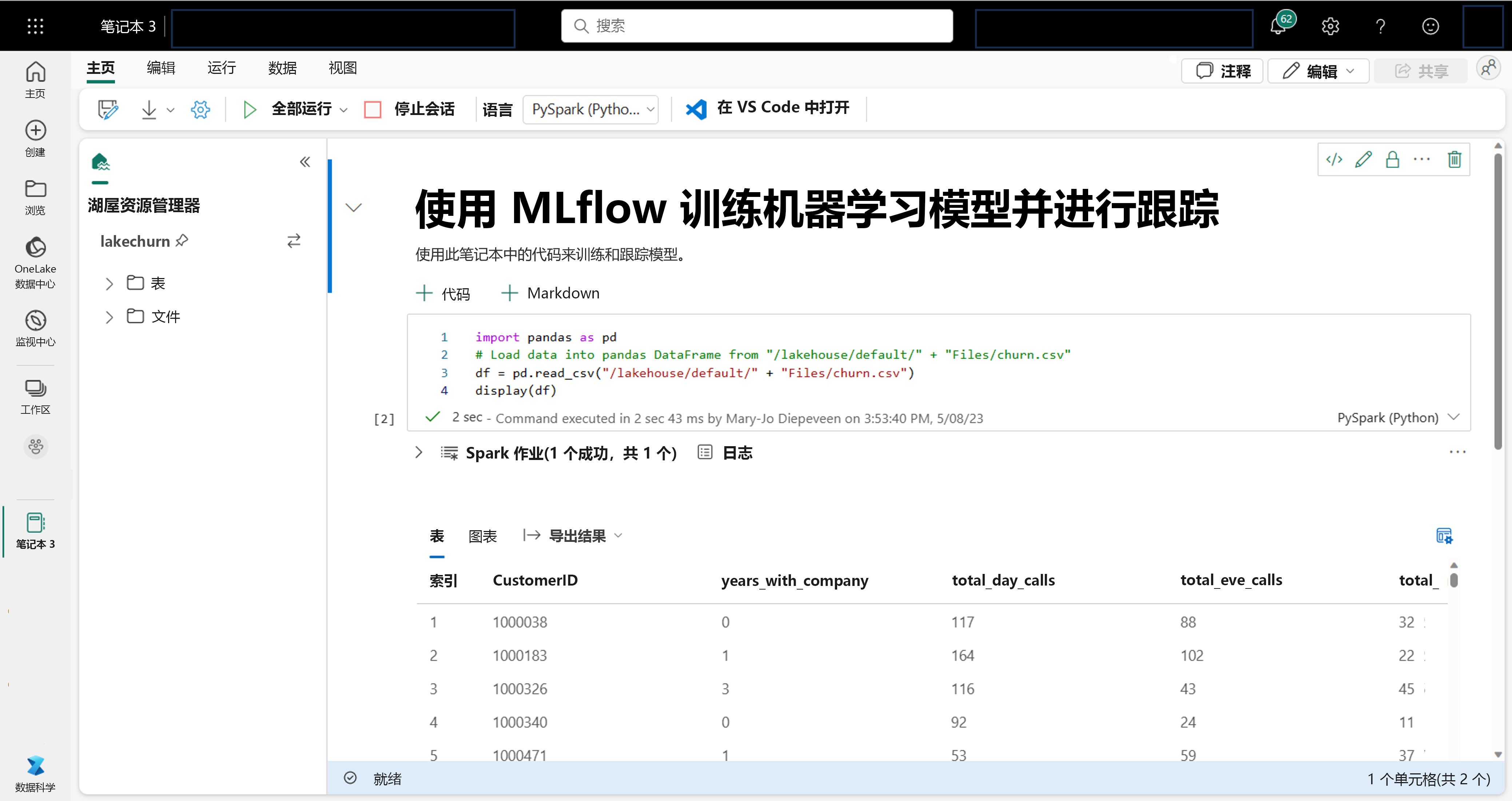
在笔记本中,你可以使用首选库或任意内置可视化选项来浏览数据。 如果有必要,你可以转换自己的数据,并通过将处理后的数据写回到湖屋来保存这些数据。
使用数据整理器准备数据
为了帮助你更快地浏览和转换数据,Microsoft Fabric 提供了易于使用的数据整理器。
启动数据整理器后,你将获得所处理数据的描述性概述。 你可以查看数据的摘要统计信息,以查找任何问题,如缺少值。
若要清理数据,可以选择任何内置的数据清理操作。 选择操作时,系统将自动生成结果预览和关联的代码。 选择所有必要的操作后,可以将转换导出为代码,然后对数据执行这些代码。