回归
回归模型经过训练,基于包括特征和已知标签的训练数据来预测数值标签值。 训练回归模型(或者实际上,任何监督式机器学习模型)的过程涉及多次迭代,在这些迭代中,你使用适当的算法(通常带有一些参数化设置)来训练模型,评估模型的预测性能,并通过使用不同的算法和参数重复训练过程来优化模型,直到达到可接受的预测准确性级别。
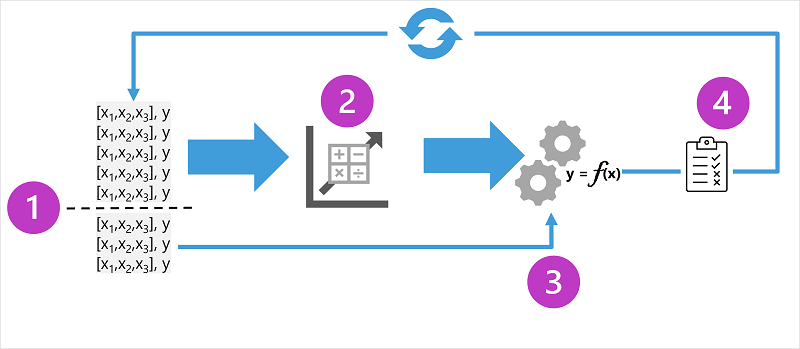
此图显示了监督式机器学习模型的训练过程的四个关键元素:
- 拆分训练数据(随机)以创建用于训练模型的数据集,同时保留要用于验证已训练模型的一部分数据。
- 使用算法以将训练数据拟合到模型。 对于回归模型,使用回归算法,例如线性回归。
- 使用保留的验证数据,通过预测特征的标签来测试模型。
- 将验证数据集中的已知实际标签与模型预测的标签进行比较。 然后,聚合预测的标签值和实际的标签值之间的差异以计算一个指标,该指标指示模型对验证数据的预测准确度。
每次训练、验证和评估迭代后,可以使用不同的算法和参数重复该过程,直到达到可接受的评估指标。
示例 - 回归
让我们通过一个简化的示例来探索回归,在该示例中,我们将训练一个模型以基于单个特征值 (x) 预测数值标签 (y)。 大多数实际场景涉及多个特征值,这增加了一些复杂性;但原理是相同的。
对于示例,让我们继续使用之前讨论过的冰淇淋销售场景。 对于特征,我们将考虑温度(假设该值是给定日期的最高温度),我们希望训练模型以预测的标签是当天售出的冰淇淋数量。 我们将从一些历史数据开始,其中包括每日温度 (x) 和冰淇淋销售额 (y) 的记录:
 |
 |
|---|---|
| 温度 (x) | 冰淇淋销售额 (y) |
| 51 | 1 |
| 52 | 0 |
| 67 | 14 |
| 65 | 14 |
| 70 | 23 |
| 69 | 20 |
| 72 | 23 |
| 75 | 26 |
| 73 | 22 |
| 81 | 30 |
| 78 | 26 |
| 83 | 36 |
训练回归模型
首先,我们将拆分数据,并使用其中一部分数据来训练模型。 下面是训练数据集:
| 温度 (x) | 冰淇淋销售额 (y) |
|---|---|
| 51 | 1 |
| 65 | 14 |
| 69 | 20 |
| 72 | 23 |
| 75 | 26 |
| 81 | 30 |
若要深入了解这些 x 和 y 值如何相互关联,我们可以将它们绘制为沿两个轴的坐标,如下所示:
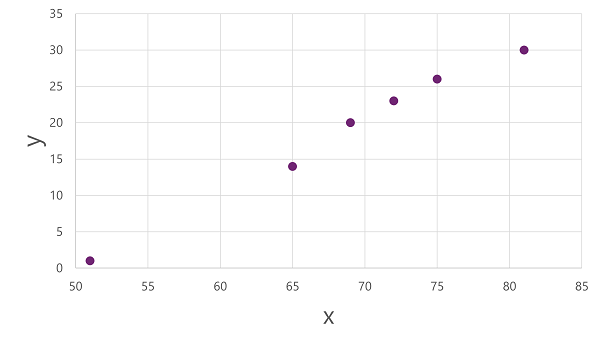
现在,我们已准备好将算法应用于训练数据,并将其拟合到将运算应用于 x 以计算 y 的函数。 其中一种算法是线性回归,它的工作原理是派生一个函数,该函数通过 x 和 y 值的交点生成一条直线,同时最小化直线和绘制点之间的平均距离,如下所示:
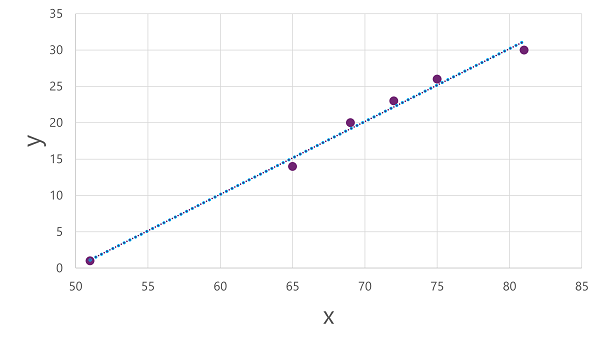
这条直线是函数的可视表示形式,其中直线的斜率描述了如何针对给定的 x 值计算 y 值。 这条直线在 50 处与 x 轴相交,因此当 x 为 50 时,y 为 0。 从绘图中的轴标记可以看出,直线倾斜,使得沿 x 轴每增加 5,沿 y 轴就会增加 5;因此当 x 为 55 时,y 为 5;当 x 为60时,y 为 10,依此类推。 若要针对给定的 x 值计算 y 值,函数只需减去 50;换句话说,函数可以如下表示:
f(x) = x-50
可以使用此函数来预测任何给定温度下一天售出的冰淇淋数量。 例如,假设天气预报告诉我们,明天将是 77 度。 我们可以应用模型来计算 77-50,并预测我们明天将销售 27 个冰淇淋。
但是我们的模型有多准确呢?
评估回归模型
为了验证模型并评估其预测效果,我们保留了一些已知标签 (y) 值的数据。 下面是我们保留的数据:
| 温度 (x) | 冰淇淋销售额 (y) |
|---|---|
| 52 | 0 |
| 67 | 14 |
| 70 | 23 |
| 73 | 22 |
| 78 | 26 |
| 83 | 36 |
可以使用模型根据特征 (x) 值来预测此数据集中每个观测值的标签;然后,将预测的标签 (ŷ) 与已知的实际标签值 (y) 进行比较。
使用前面训练的模型(该模型封装函数 f(x) = x-50),可生成以下预测:
| 温度 (x) | 实际销售额 (y) | 预测销售额 (ŷ) |
|---|---|---|
| 52 | 0 | 2 |
| 67 | 14 | 17 |
| 70 | 23 | 20 |
| 73 | 22 | 23 |
| 78 | 26 | 28 |
| 83 | 36 | 33 |
我们可以针对特征值绘制预测标签和实际标签,如下所示:
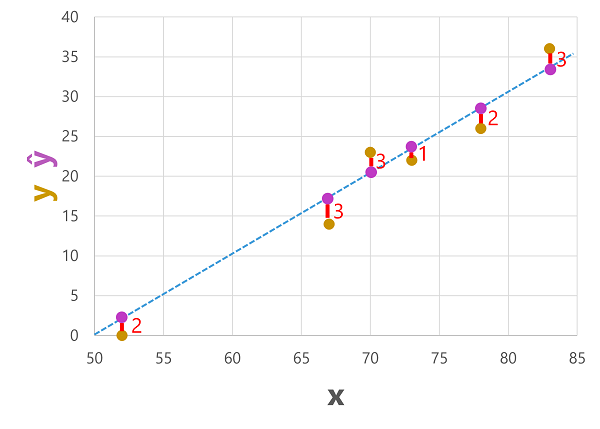
预测标签由模型计算,因此它们位于函数线上,但是由函数计算的 ŷ 值与来自验证数据集的实际 y 值之间存在一些差异;这在绘图上表示为 ŷ 值和 y 值之间的线,显示预测值与实际值的差距。
回归评估指标
根据预测值和实际值之间的差异,可以计算用于评估回归模型的一些常见指标。
平均绝对误差 (MAE)
此示例中的方差指示每个预测错误的冰淇淋数量。 预测是高于还是低于实际值无关紧要(例如,-3 和 +3 都表示方差为 3)。 此指标被称为每个预测的绝对误差,并且可以被总结为整个验证集的平均绝对误差 (MAE)。
在冰淇淋示例中,绝对误差(2、3、3、1、2 和 3)的平均值为 2.33。
均方误差 (MSE)
平均绝对误差指标同等地考虑预测标签和实际标签之间的所有差异。 然而,相比误差较少但较大的模型,一个始终误差较小的模型可能更可取。 生成“放大”较大误差的指标的一种方法是对单个误差求平方,并计算平方值的平均值。 此指标被称为均方误差 (MSE)。
在我们的冰淇淋示例中,绝对值平方(4、9、9、1、4 和 9)的平均值为 6。
均方根误差 (RMSE)
均方误差有助于考虑误差的幅度,但是因为它对误差值进行平方,所以得到的指标不再代表标签测量的量。 换句话说,我们可以说模型的 MSE 为 6,但这并不能衡量它在被错误预测的冰淇淋数量方面的准确性;6 只是一个数字分数,表示验证预测中的错误级别。
如果要根据冰淇淋的数量来衡量误差,我们需要计算 MSE 的平方根;不出所料,这生成了一个名为均方根误差的指标。 在本例中,为 √6,即 2.45(冰淇淋)。
决定系数 (R2)
到目前为止,所有指标都比较预测值与实际值之间的差异,以评估模型。 然而,在现实中,模型考虑到了冰淇淋日销售额中的一些自然随机差异。 在线性回归模型中,训练算法拟合一条直线,使函数和已知标签值之间的平均方差最小化。 决定系数(通常称为 R2 或 R 平方)是一种指标,用于测量验证结果中可由模型解释的方差比例,而不是验证数据的某些异常方面(例如,由于当地节日,某一天的冰淇淋销售量非常不寻常)。
R2 的计算比前面的指标更复杂。 它将预测标签和实际标签之间的平方差之和与实际标签值和实际标签值的平均值之间的平方差之和进行比较,如下所示:
R2 = 1- ∑(y-ŷ)2 ÷ ∑(y-ȳ)2
如果这看起来很复杂,不要太担心;大多数机器学习工具都可以为你计算指标。 重要的一点是,结果是一个介于 0 和 1 之间的值,该值描述了模型所解释的方差的比例。 简单来说,此值越接近 1,模型就越拟合验证数据。 对于冰淇淋回归模型,根据验证数据计算的 R2 为 0.95。
迭代训练
上述指标通常用于评估回归模型。 在大多数实际场景中,数据科学家将使用迭代过程来重复训练和评估模型,包括:
- 特征选择和准备(选择要包含在模型中的特征,以及应用于这些特征的计算,以帮助确保更好地拟合)。
- 算法选择(我们在上一示例中探讨了线性回归,但还有许多其他回归算法)
- 算法参数(控制算法行为的数字设置,更准确地说,称为超参数,以区别于 x 和 y 参数)。
在多次迭代后,选择产生特定场景可接受的最佳评估指标的模型。