机器学习类型
机器学习有多种类型,必须根据尝试预测的内容应用适当的类型。 下图显示了常见机器学习类型的细目。
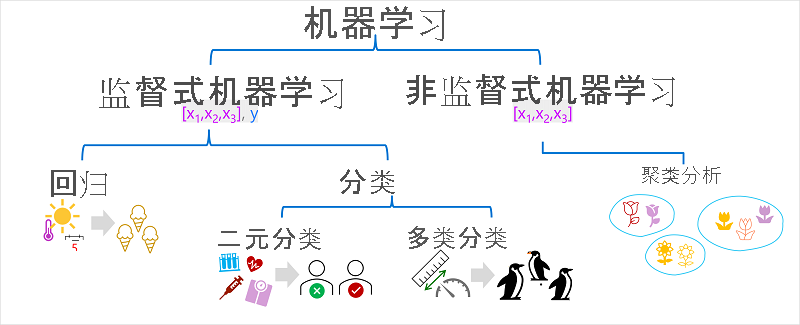
监督式机器学习
监督式机器学习是机器学习算法的一个通用术语,其中训练数据包括特征值和已知标签值。 监督式机器学习用于通过确定过去观测值中特征与标签之间的关系来训练模型,以便将来可以预测特征的未知标签。
回归
回归是监督式机器学习的一种形式,其中模型预测的标签是数值。 例如:
- 给定一天销售的冰淇淋数量,基于温度、降雨量和风速。
- 物业的销售价格,基于物业大小(以平方英尺为单位)、所含卧室数量及所在位置的社会经济指标。
- 汽车燃油效率(以英里/加仑为单位),基于发动机大小、重量、宽度、高度和长度。
分类
分类是监督式机器学习的一种形式,其中标签表示一个分类或类。 有两种常见的分类场景。
二元分类
在二元分类中,标签确定观察到的项是(或不是)特定类的实例。 换句话说,二元分类模型预测两个互斥结果中的一个。 例如:
- 基于体重、年龄、血糖水平等临床指标,患者是否有患糖尿病的风险。
- 基于收入、信用记录、年龄和其他因素,银行客户是否会拖欠贷款。
- 基于人口统计属性和过去的购买情况,邮寄列表客户是否会对营销产品/服务做出积极响应。
在所有这些示例中,模型为单个可能类预测二进制 true/false 或积极/消极预测。
多类分类
多类分类扩展了二元分类,以预测表示多个可能类之一的标签。 例如,
- 企鹅的物种(阿德利企鹅、巴布亚企鹅或帽带企鹅),基于身体测量。
- 电影的流派(喜剧、恐怖、爱情、冒险或科幻),基于演员、导演和预算。
在涉及一组已知多个类的场景中,多类分类用于预测互斥标签。 例如,一只企鹅不能同时是巴布亚企鹅和阿德利企鹅。 但是,还可以使用一些算法来训练多标签分类模型,其中对于单个观测值可能有多个有效标签。 例如,一部电影可能同时被归类为科幻和喜剧。
非监督式机器学习
非监督式机器学习涉及使用仅包含特征值且没有任何已知标签的数据来训练模型。 非监督式机器学习算法确定训练数据中观测值的特征之间的关系。
群集
非监督式机器学习最常见的形式是聚类分析。 聚类分析算法基于观测值的特征识别观测值之间的相似性,并将它们分组到离散群集中。 例如:
- 根据花的大小、叶数和花瓣数量,对类似的花进行分组。
- 根据人口统计属性和购买行为,确定类似客户的组。
在某些方面,聚类分析类似于多类分类;因为它将观侧值分类为离散组。 区别在于,使用分类时,你已经知道训练数据中的观测值所属的类;因此,该算法的工作原理是确定特征与已知分类标签之间的关系。 在聚类分析中,没有以前已知的分类标签,算法完全基于特征的相似性对数据观测值进行分组。
在某些情况下,聚类分析用于确定在训练分类模型之前存在的类集。 例如,可以使用聚类分析将客户细分到多个组,然后对这些组进行分析,以识别不同的客户类并对其进行分类(高价值 - 低交易量、经常购买小额产品等)。 然后,可以使用分类来标记聚类分析结果中的观测值,并使用标记的数据来训练预测新客户可能属于哪个客户类别的分类模型。